![]()
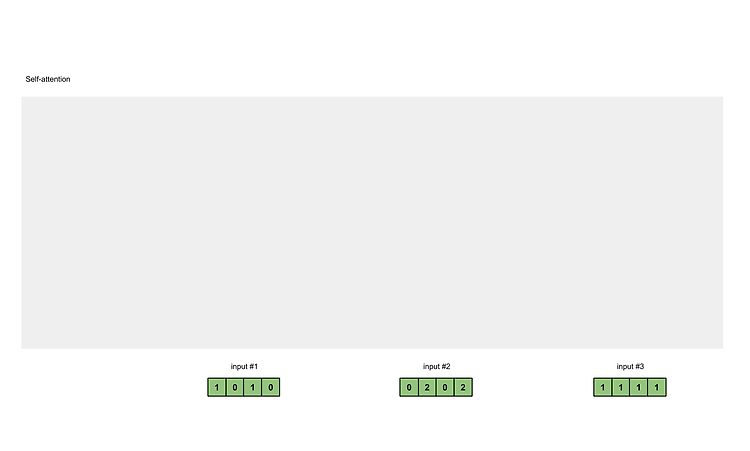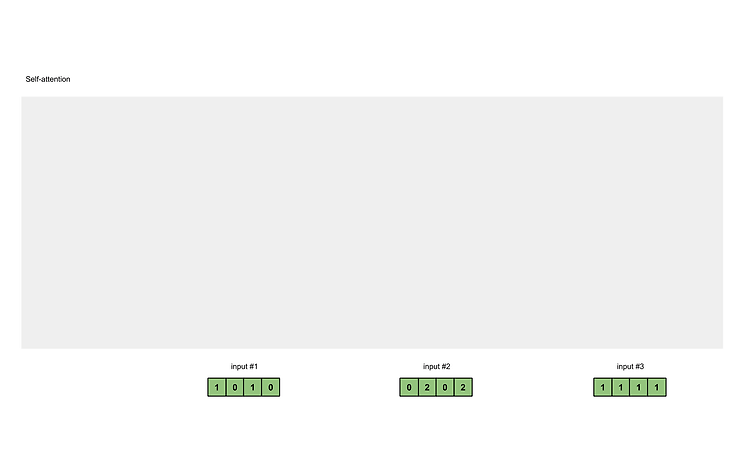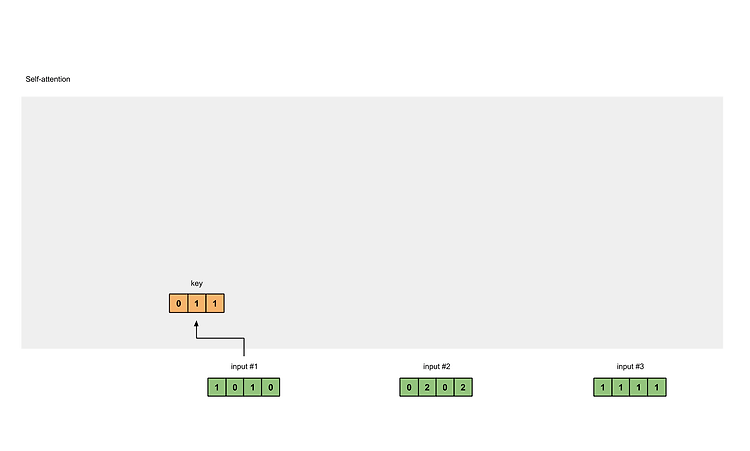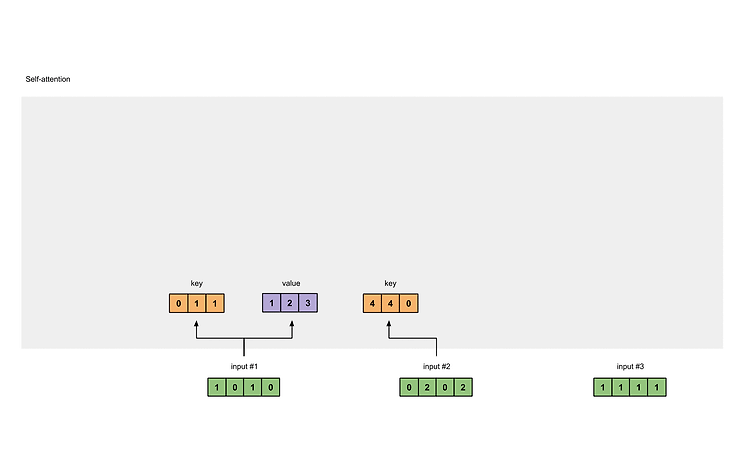
input#1을 기준으로 #2, #3와의 관계를 score로 만들고 output #1을 만든다. 그리고 #2와 #1, #3와의 score를 구하고 다음 #으로 넘어가면서 score를 구한다. 이 점수 score를 모아 attention map을 만든다. 1. Illustrations The illustrations are divided into the following steps: Prepare inputs Initialise weights Derive key, query and value Calculate attention scores for Input 1 Calculate softmax Multiply scores with values Sum weighted values to get Output 1 ..
![]()
www.tensorflow.org/tutorials/generative/cvae?hl=ko 컨볼루셔널 변이형 오토인코더 | TensorFlow Core 이 노트북은 MNIST 데이터세트에서 변이형 오토인코더(VAE, Variational Autoencoder)를 훈련하는 방법을 보여줍니다(1 , 2). VAE는 오토인코더의 확률론적 형태로, 높은 차원의 입력 데이터를 더 작은 표현 www.tensorflow.org Data load from IPython import display import glob import imageio import matplotlib.pyplot as plt import numpy as np import PIL import tensorflow as tf import tensor..
![]()
RBM 상수 초기화 (Zeros. Ones, Constant) class Constant: Initializer that generates tensors with constant values class Ones: Initializer that generates tensors initialized to 1. class Zeros: Initializer that generates tensors initialized to 0. class VarianceScaling: Initializer capable of adapting its scale to the shape of weights tensors. 선형 초기화 (Orthogonal, Identity) class Orthogonal: Initializer th..
![]()
reparameterization trick VAE는 입력을 재현하도록 학습한다. 확률 분포에 따라 샘플링한 데이터가 중간에 있스으므로 편미분, 역전파 둘다 불가능하다. 따라서 VAE는 reparameterization trick이라는 방법을 사용한다. reparameterization trick은 평균 = 0 표준편차 = 1 정규화분포를 따른다. z = μ + ϵσ ϵ에 표준편차(σ)를 곱한 후 평균 μ를 더해 계산한다. VAE 재구성 오차
![]()
VAE(Variational Autoencoder)는 오토인코더(자기부호화기)라는 신경망의 발전 형태를 기반에 두었다. 오토인코더는 인코더와 디코더로 구성되어 있다. [Autoencoder] 입력과 출력의 크기는 같고, 은닉층의 크기는 그보다 작다. 신경망은 출력에서 입력한 데이터를 재현하도록 학습하지만, 은닉층의 크기는 입력보다 작다. 인코더로 데이터를 압축하고 디코더로 압축한 데이터를 원래 데이터로 복원한다. 입력 데이터가 이미지라면 은닉층은 인코더와 디코더를 이용해 원래 이미지보다 적은 데이텨 양으로 이미지의 특징을 유지 한다. 즉 오토인코더는 신경망을 이용한 입력의 압축과 복원이라고 이해하면 쉽다. 오토인코더는 지도 데이터가 필요 없으므로 비지도 학습이다. 입력과 출력의 차이를 이용해 비정상적인 ..
- Full Support - All Tesla products, starting with the Kepler architecture - All Quadro products, starting with the Kepler architecture - All GRID products, starting with the Kepler architecture - GeForce Titan products, starting with the Kepler architecture - Limited Support - All Geforce products, starting with the Kepler architecture nvidia-smi [OPTION1 [ARG1]] [OPTION2 [ARG2]] ... -h, --help..
![]()
RNN 특성상 인풋 값을 시계열로 다룬다. 따라서 이미지를 처리 할 때 훈련된 모델에 처음 몇 행을 입력하면 다음 행을 예측한다. 이 예측된 행을 포함해 다시 몇 개의 행을 입력으로 다음 행을 예측하는 훈련을 반복하면 , 항 행씩 이미지를 생성 가능하다. # RNN #RNN을 이용한 이미지 생성 import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split img_size = 8 # 이미지의 폭과 높이 n_time = 4 # 시계열 데이터의 수 n_in = img_size # 입력층의 뉴런 수 n_mid = 128 # 은닉층의 뉴런..
![]()
Gated Recurrent Unit LSTM을 개선한 순환 신경망의 게이트 구조 2014년 뉴욕 대학교의 조경현 교수님 외 6인이 최초 제안 했다. GRU는 입력 게이트와 망각 게이트를 합한 업데이트 게이트가 있다. 기억 셀에는 출력게이트가 없는 대신 과거에서 이어받은 기억을 선별하는 리셋 게이트가 있다. 이러한 게이트가 동작해 LSTM처럼 장기 기억을 이어 받을 수 있다. +: 원소간의 합 x: 원소간의 곱 1-: 전달받은 값을 1에서 빼기 σ: 시그모이드 함수 r: 리셋 게이트 z: 업데이트 게이트 h: 새로운 기억 x: t 시점에서 신경망층의 입력 h : t-1 이전 시점의 출력 게이트 2개에는 각각 학습 파라미터가 있다. 또한 tanh를 또 다른 활성화 함수로 사용하는 학습 파라미터가 있다. 총..