

Gated Recurrent Unit
LSTM을 개선한 순환 신경망의 게이트 구조
2014년 뉴욕 대학교의 조경현 교수님 외 6인이 최초 제안 했다.
GRU는 입력 게이트와 망각 게이트를 합한 업데이트 게이트가 있다.
기억 셀에는 출력게이트가 없는 대신 과거에서 이어받은 기억을 선별하는 리셋 게이트가 있다. 이러한
게이트가 동작해 LSTM처럼 장기 기억을 이어 받을 수 있다.

- +: 원소간의 합
- x: 원소간의 곱
- 1-: 전달받은 값을 1에서 빼기
- σ: 시그모이드 함수
- r: 리셋 게이트
- z: 업데이트 게이트
- h: 새로운 기억
x: t 시점에서 신경망층의 입력
h : t-1 이전 시점의 출력
게이트 2개에는 각각 학습 파라미터가 있다. 또한 tanh를 또 다른 활성화 함수로 사용하는 학습 파라미터가 있다. 총 3개의 학습 파라미터가 있다.
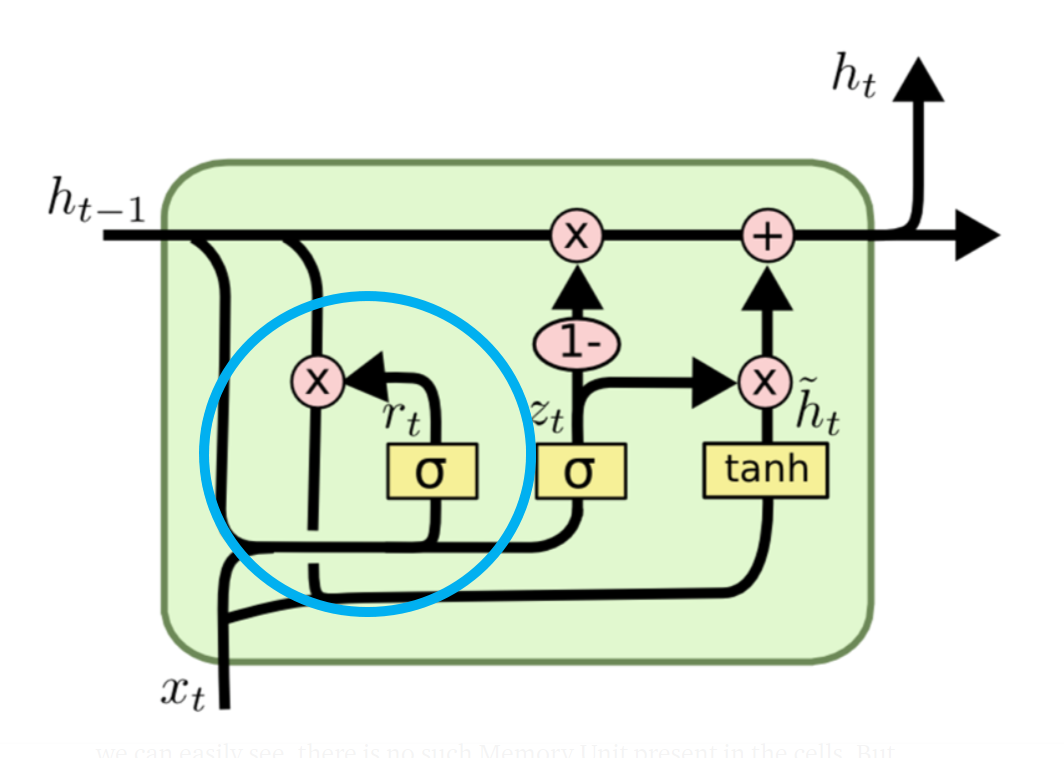
1. 리셋 게이트
시그모이드 함수를 거친 출력과 과거에서
전달받은 데이터의 원소 각각을 곱한다.
시그모이드 함수는 0~1의 값을 출력한다. 리셋 게이트에서 0~1 값을 곱하는 것으로 과거의 기억을 어느 정도 받아들일지 조정한다. (= 가중치 부여)
$A_1^t = \sigma (X^tW_1 + Y ^{t-1}V_1 + B_1)$
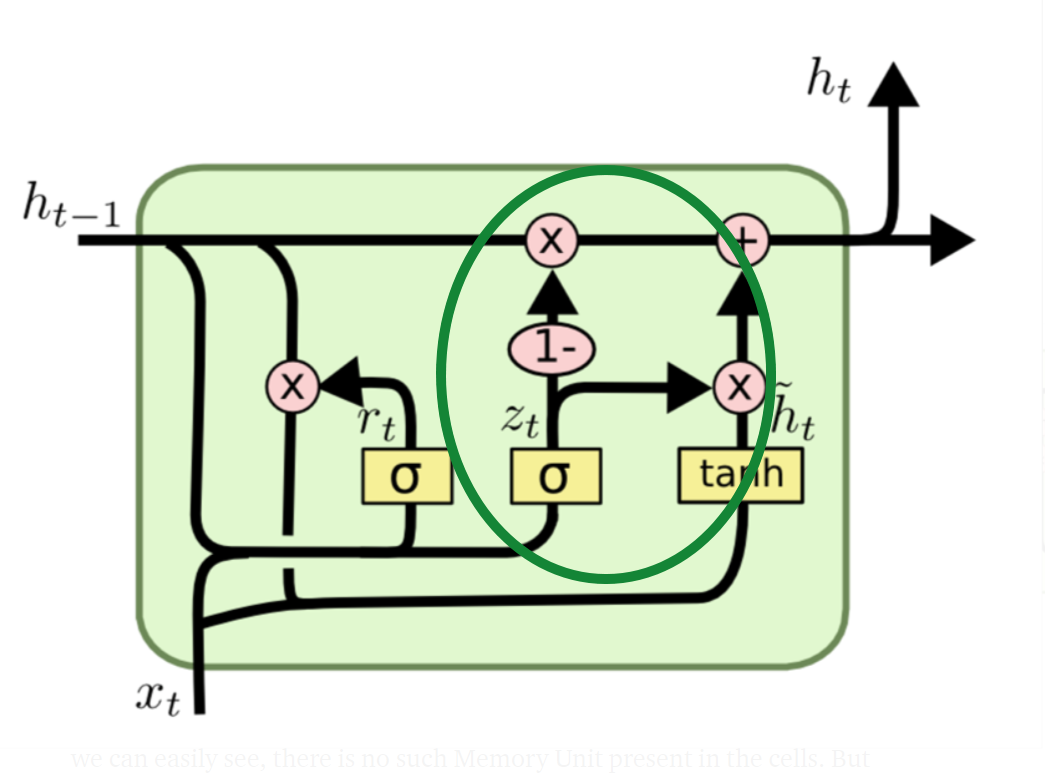
2. 업데이트 게이트
새로운 기억에 업데이트 게이트의 값을 곱하고, 과거 기억에는 1에서 업데이트 게이트의 값을 뺀 결과를 곱한 후 서로 더한다.
그럼 새로운 기억과 과거 기억의 비율이 조정되어 현 시점의 출력을 얻는다.
$A_0^t = \sigma (X^tW_0 + Y ^{t-1}V_0 + B_0)$
'👾 Deep Learning' 카테고리의 다른 글
| VAE(Variational Autoencoder) (1) (0) | 2021.02.18 |
|---|---|
| nvidia-smi 옵션 (0) | 2021.02.16 |
| RNN을 이용한 이미지 생성(feat.MNIST) (0) | 2021.02.15 |
| activation 종류 (0) | 2021.02.10 |
| XG 부스트(eXtream Gradient Boosting) (0) | 2021.02.09 |
Gated Recurrent Unit
LSTM을 개선한 순환 신경망의 게이트 구조
2014년 뉴욕 대학교의 조경현 교수님 외 6인이 최초 제안 했다.
GRU는 입력 게이트와 망각 게이트를 합한 업데이트 게이트가 있다.
기억 셀에는 출력게이트가 없는 대신 과거에서 이어받은 기억을 선별하는 리셋 게이트가 있다. 이러한
게이트가 동작해 LSTM처럼 장기 기억을 이어 받을 수 있다.
- +: 원소간의 합
- x: 원소간의 곱
- 1-: 전달받은 값을 1에서 빼기
- σ: 시그모이드 함수
- r: 리셋 게이트
- z: 업데이트 게이트
- h: 새로운 기억
x: t 시점에서 신경망층의 입력
h : t-1 이전 시점의 출력
게이트 2개에는 각각 학습 파라미터가 있다. 또한 tanh를 또 다른 활성화 함수로 사용하는 학습 파라미터가 있다. 총 3개의 학습 파라미터가 있다.
1. 리셋 게이트
시그모이드 함수를 거친 출력과 과거에서
전달받은 데이터의 원소 각각을 곱한다.
시그모이드 함수는 0~1의 값을 출력한다. 리셋 게이트에서 0~1 값을 곱하는 것으로 과거의 기억을 어느 정도 받아들일지 조정한다. (= 가중치 부여)
At1=σ(XtW1+Yt−1V1+B1)
2. 업데이트 게이트
새로운 기억에 업데이트 게이트의 값을 곱하고, 과거 기억에는 1에서 업데이트 게이트의 값을 뺀 결과를 곱한 후 서로 더한다.
그럼 새로운 기억과 과거 기억의 비율이 조정되어 현 시점의 출력을 얻는다.
At0=σ(XtW0+Yt−1V0+B0)
'👾 Deep Learning' 카테고리의 다른 글
| VAE(Variational Autoencoder) (1) (0) | 2021.02.18 |
|---|---|
| nvidia-smi 옵션 (0) | 2021.02.16 |
| RNN을 이용한 이미지 생성(feat.MNIST) (0) | 2021.02.15 |
| activation 종류 (0) | 2021.02.10 |
| XG 부스트(eXtream Gradient Boosting) (0) | 2021.02.09 |