input#1을 기준으로 #2, #3와의 관계를 score로 만들고 output #1을 만든다. 그리고 #2와 #1, #3와의 score를 구하고 다음 #으로 넘어가면서 score를 구한다. 이 점수 score를 모아 attention map을 만든다.

1. Illustrations
The illustrations are divided into the following steps:
- Prepare inputs
- Initialise weights
- Derive key, query and value
- Calculate attention scores for Input 1
- Calculate softmax
- Multiply scores with values
- Sum weighted values to get Output 1
- Repeat steps 4–7 for Input 2 & Input 3
Step 1: Prepare inputs
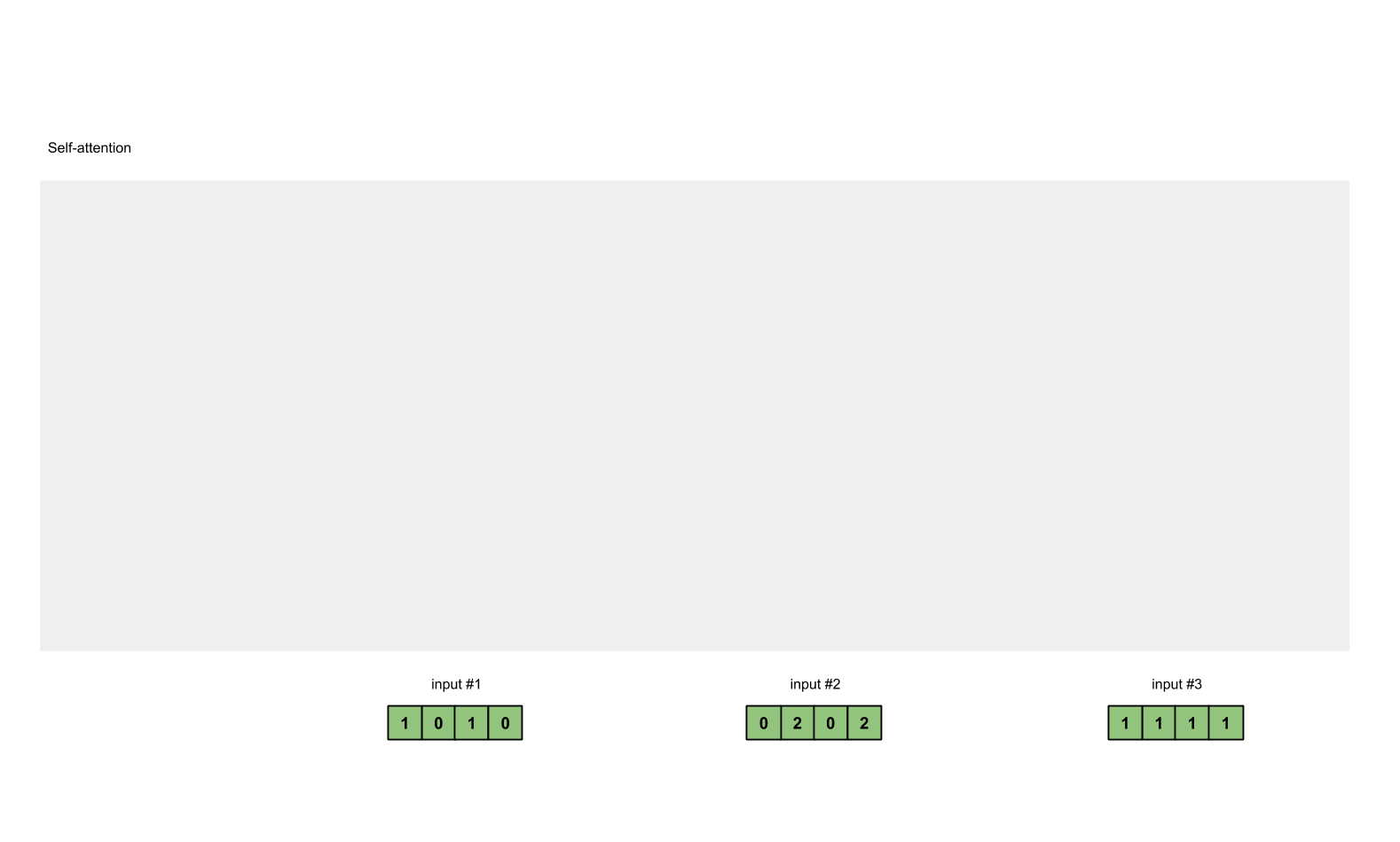
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
데이터 입력
Step 2: Initialise weights
각 인풋 값에 가중치를 부여한 뒤 값을 구한다.
신경망(neural network)은 연속확률 분포인 Gaussian, Xavier, He Kaming 분포를 이용한다. 이 초기화는 training 전에 한번 사용한다.
key: [[0, 0, 1], query: [[1, 0, 1], value: [[0, 2, 0],
[1, 1, 0], [1, 0, 0], [0, 3, 0],
[0, 1, 0], [0, 0, 1], [1, 0, 3],
[1, 1, 0]] [0, 1, 1]] [1, 1, 0]]
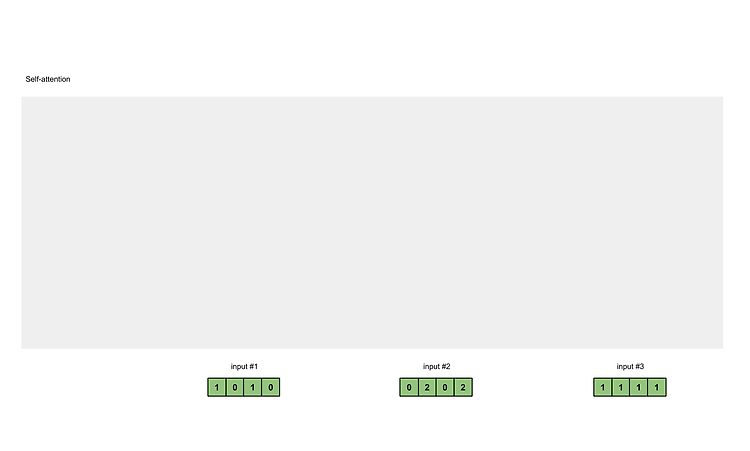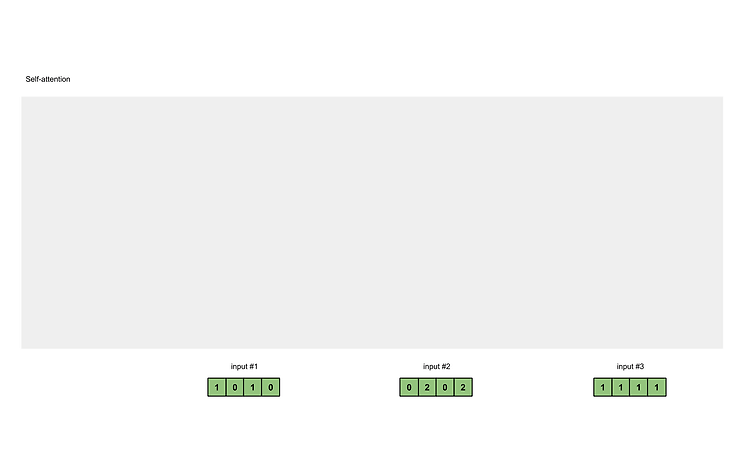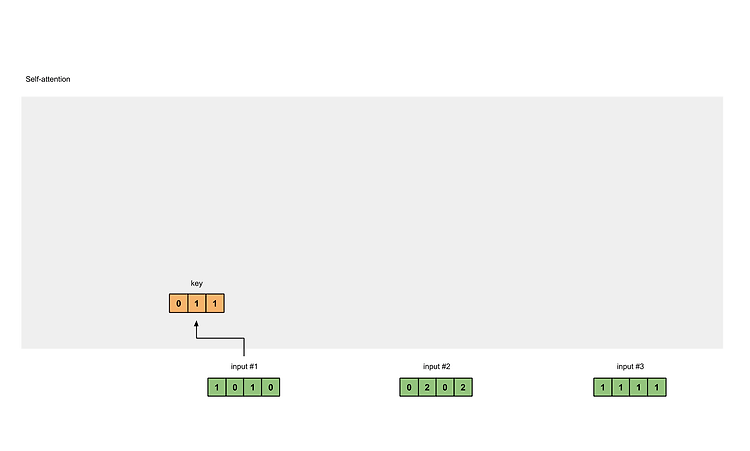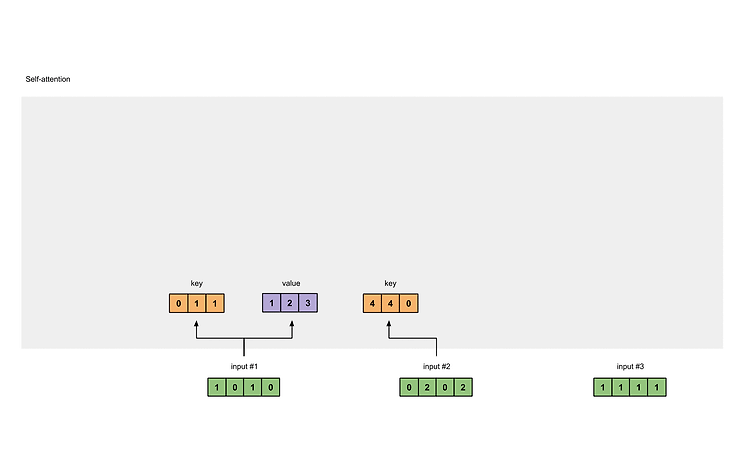
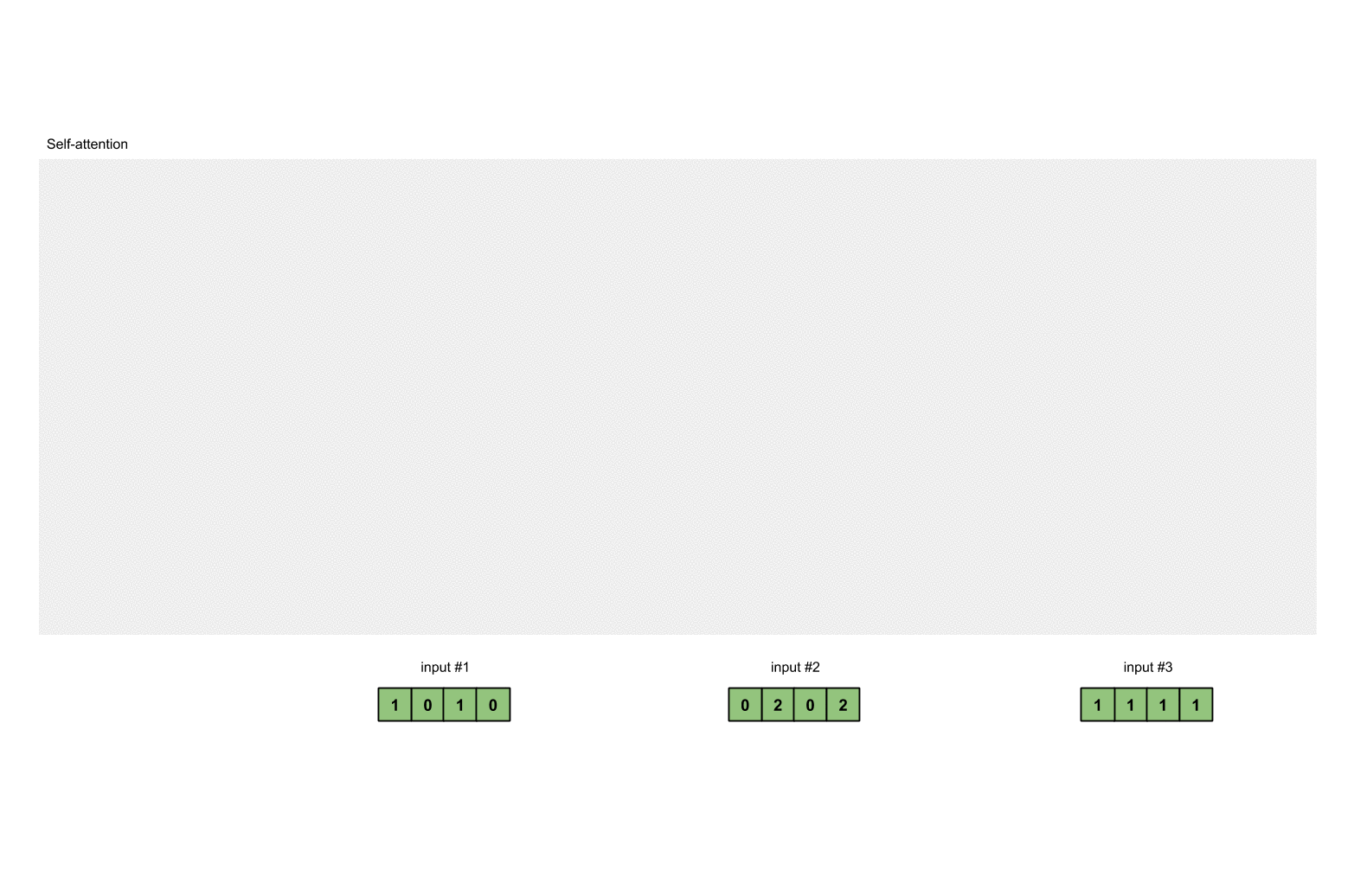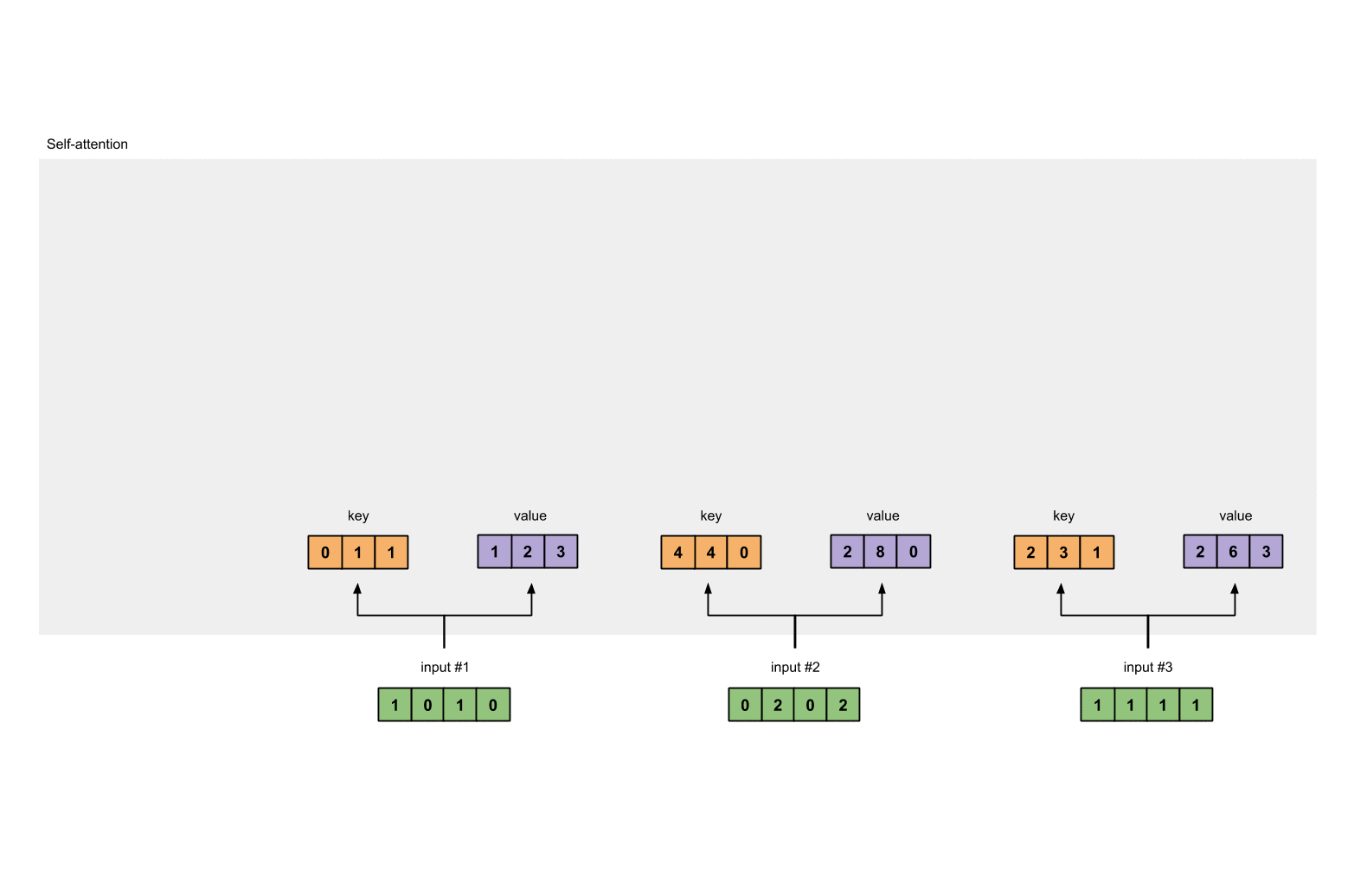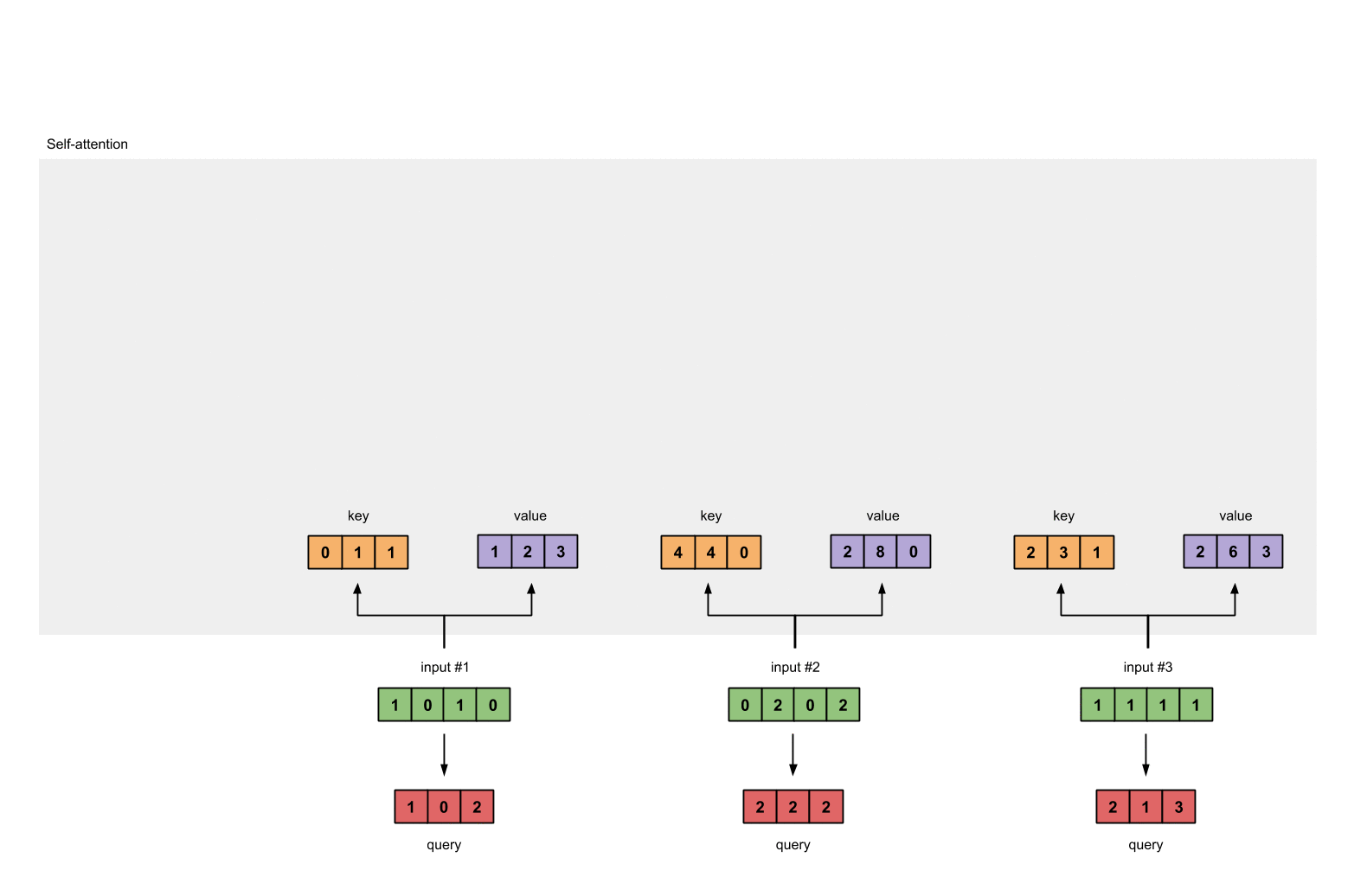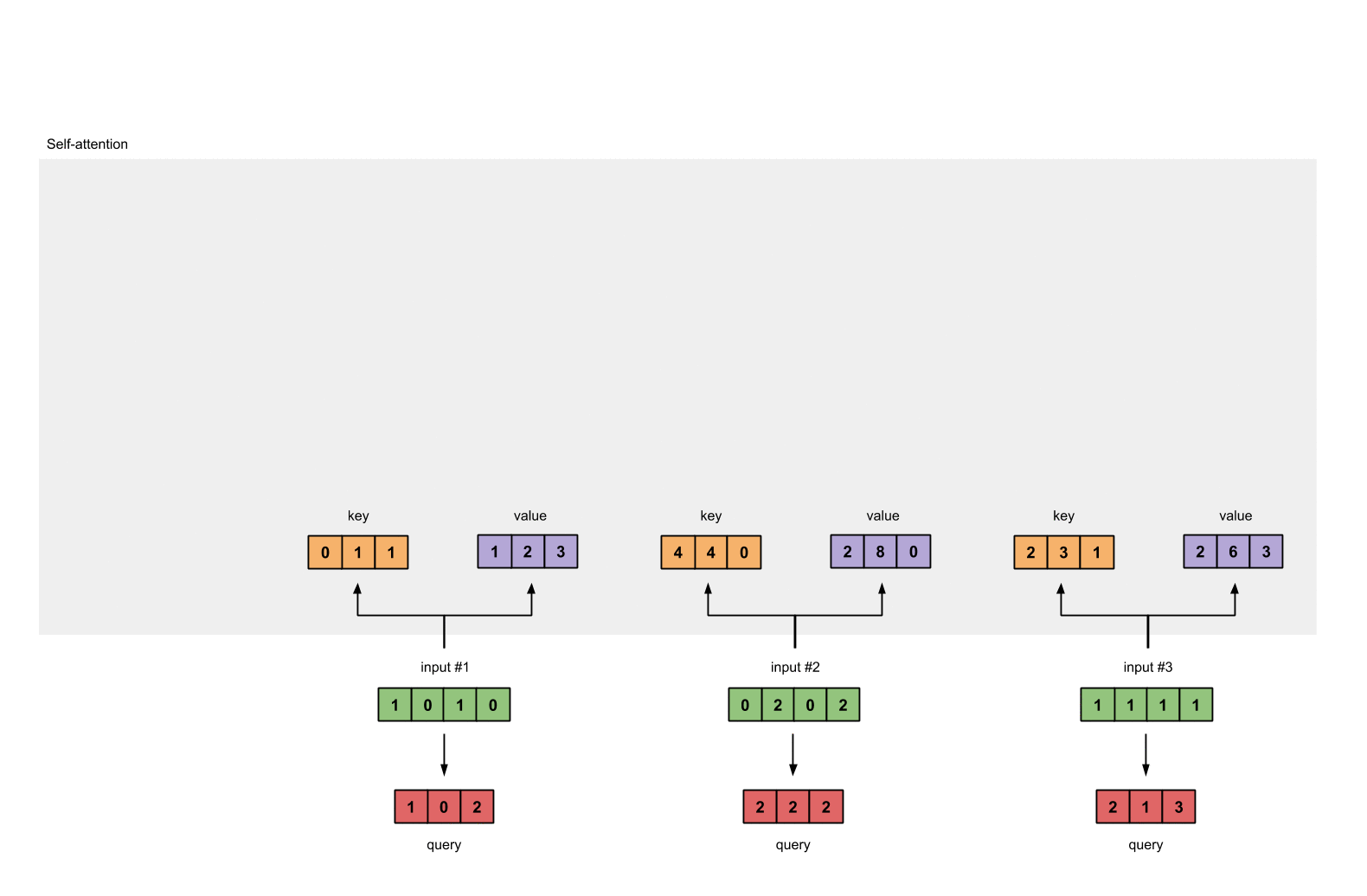
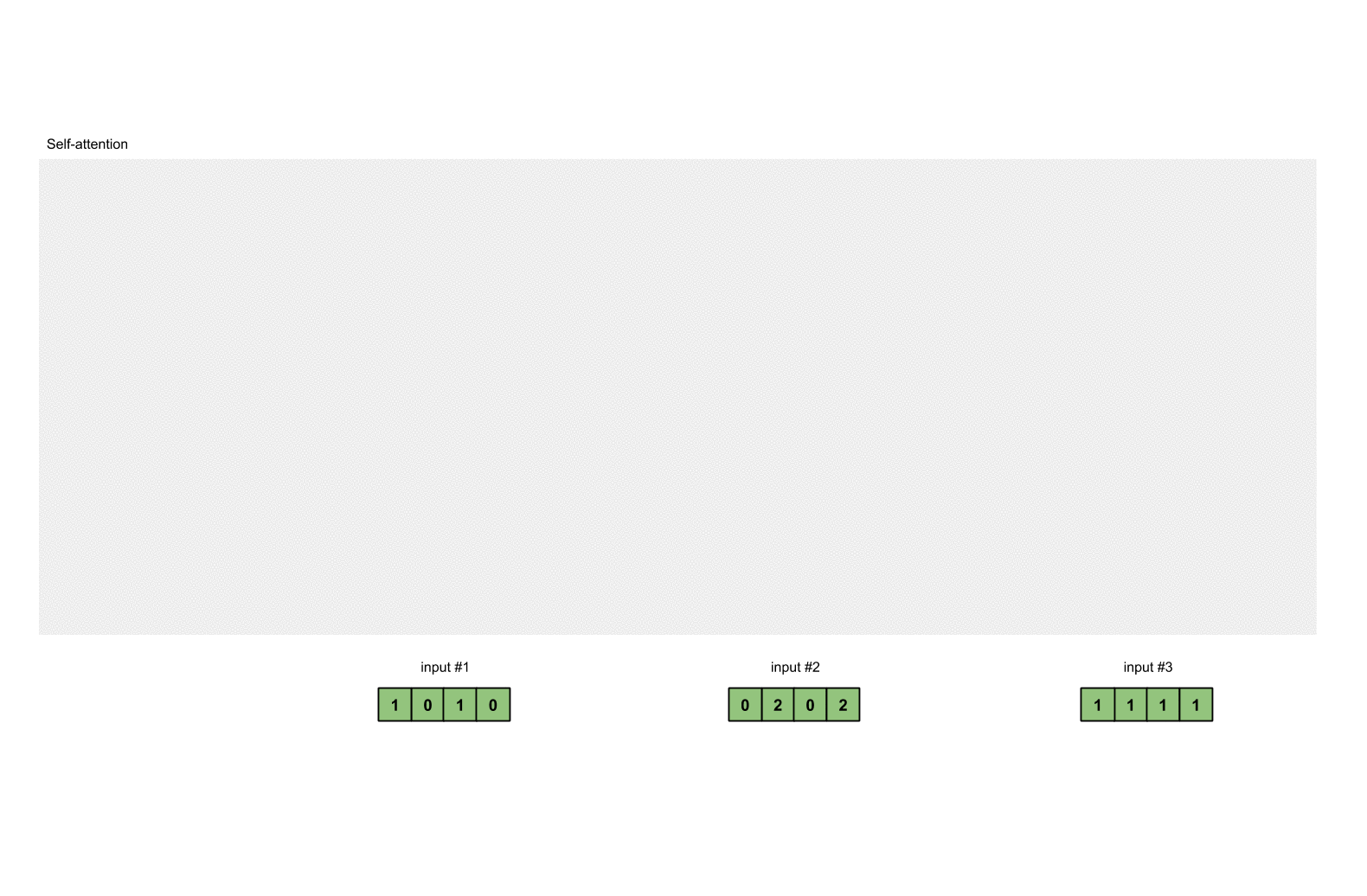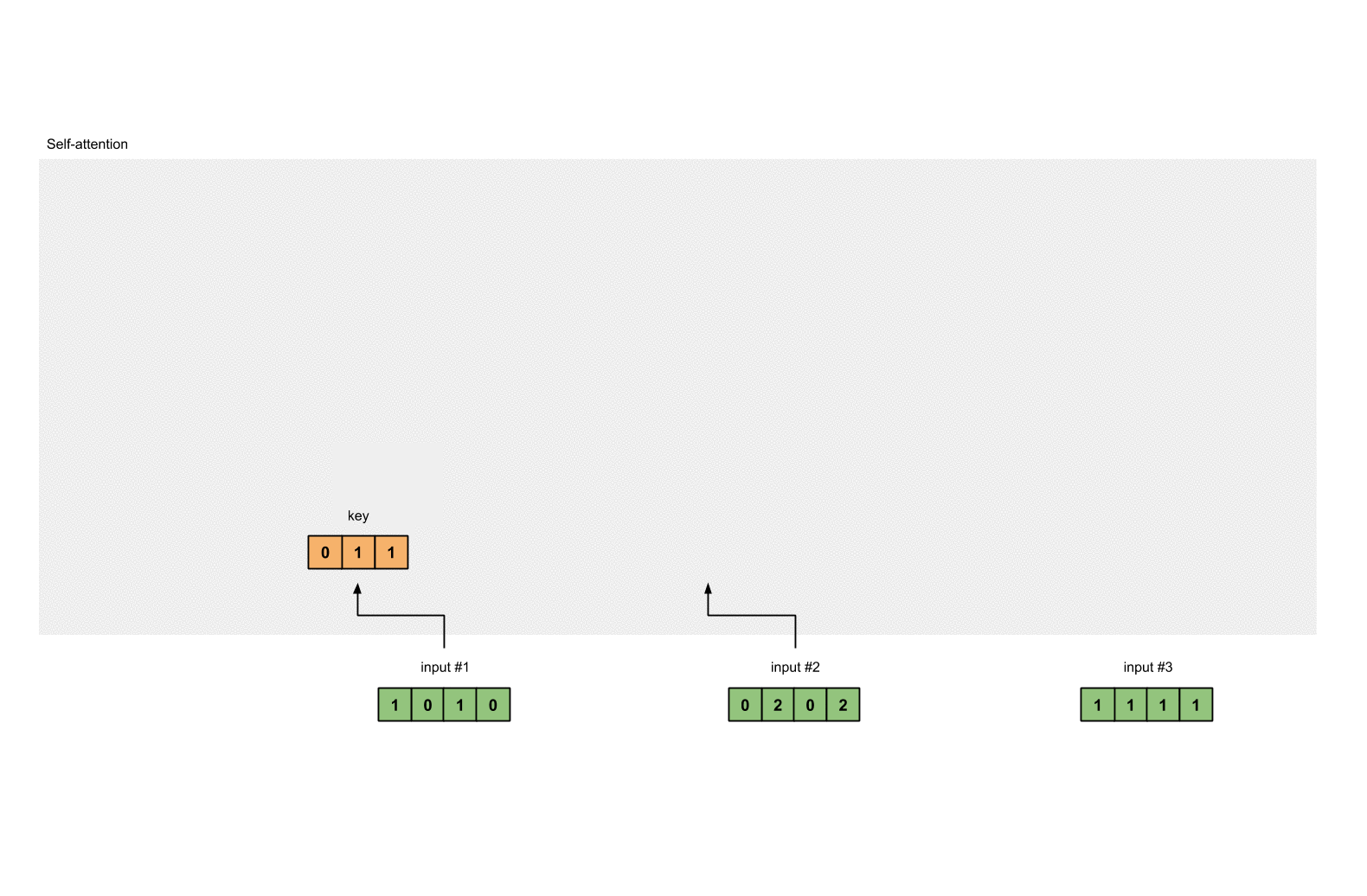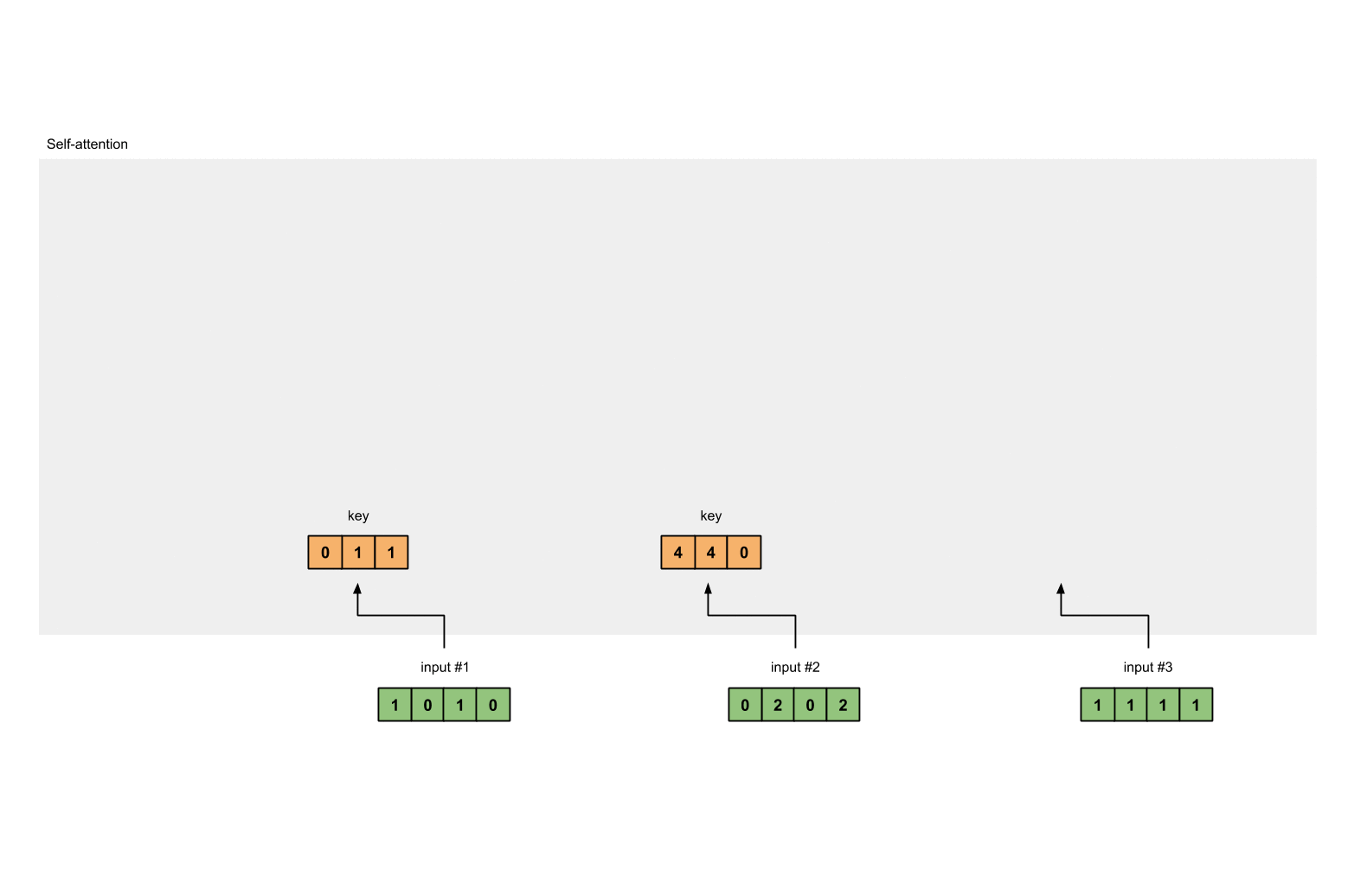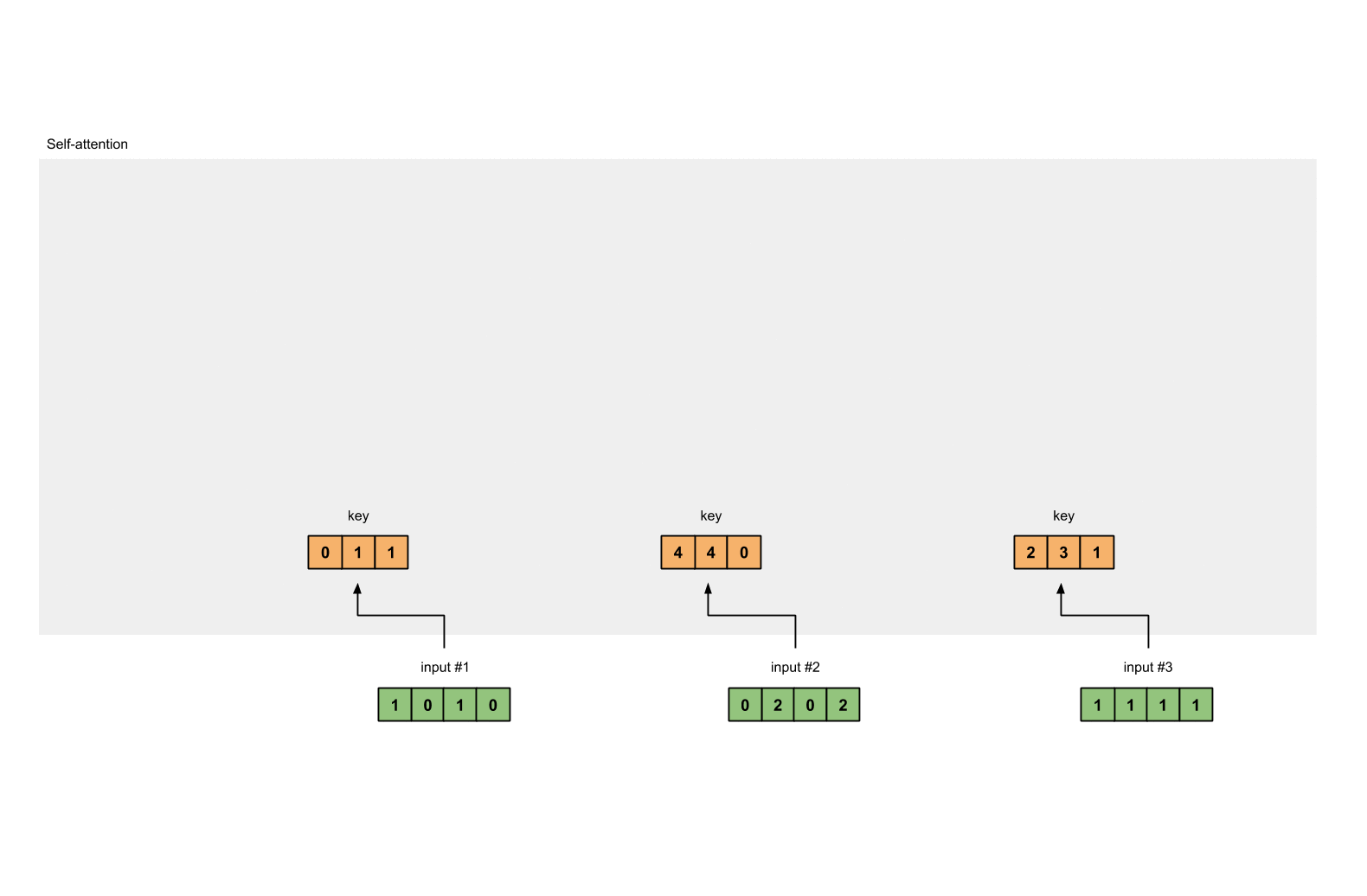
Step 3: Derive key, query and value
내적 연산을
Input #1 : [1, 0, 1, 0]
[0, 0, 1]
[1, 0, 1, 0] X [1, 1, 0] = [0, 1, 1]
[0, 1, 0]
[1, 1, 0]
input #2 : [0, 2, 0, 2]
[0, 0, 1]
[0, 2, 0, 2] x [1, 1, 0] = [4, 4, 0]
[0, 1, 0]
[1, 1, 0]
# key :
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
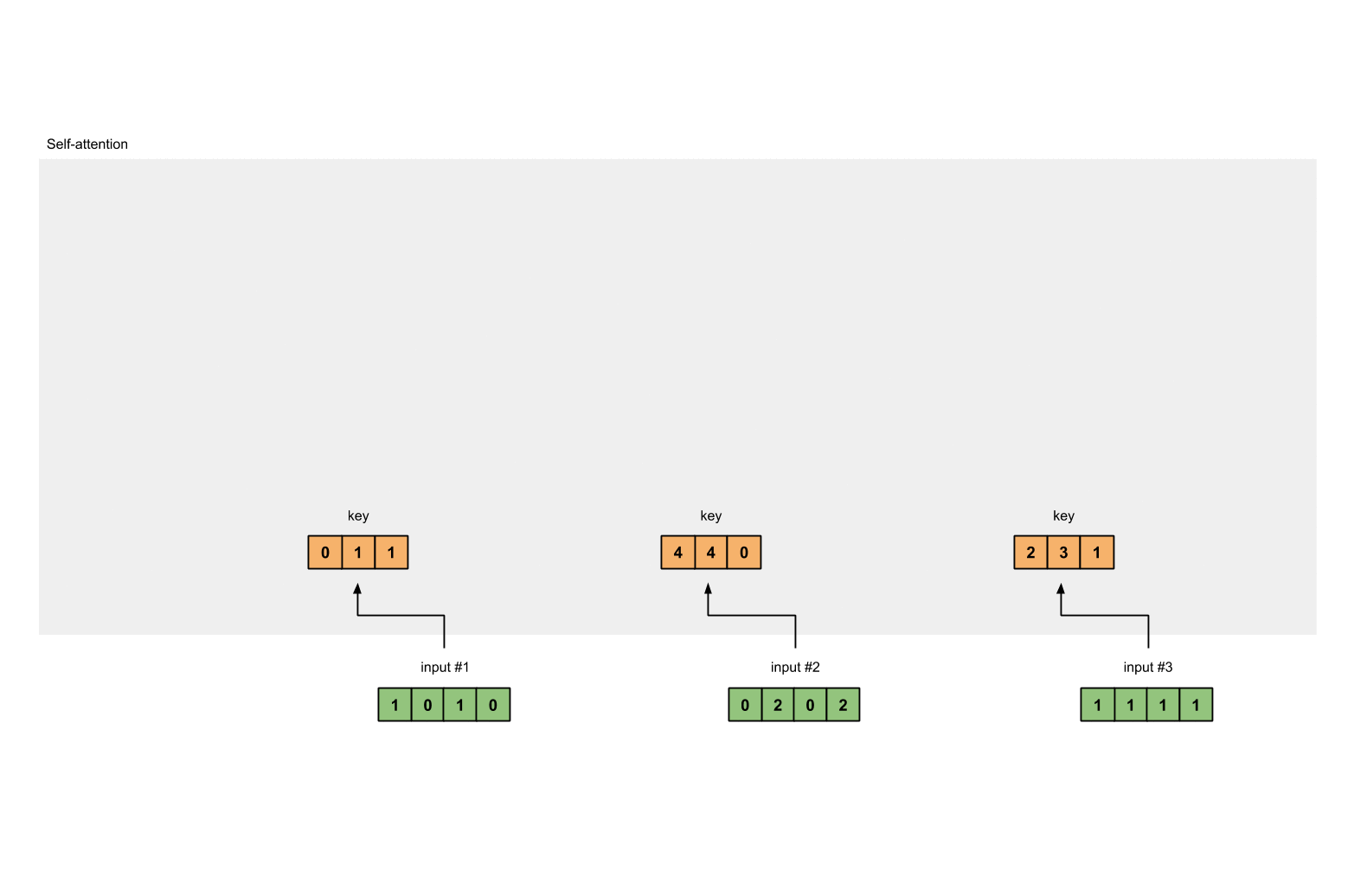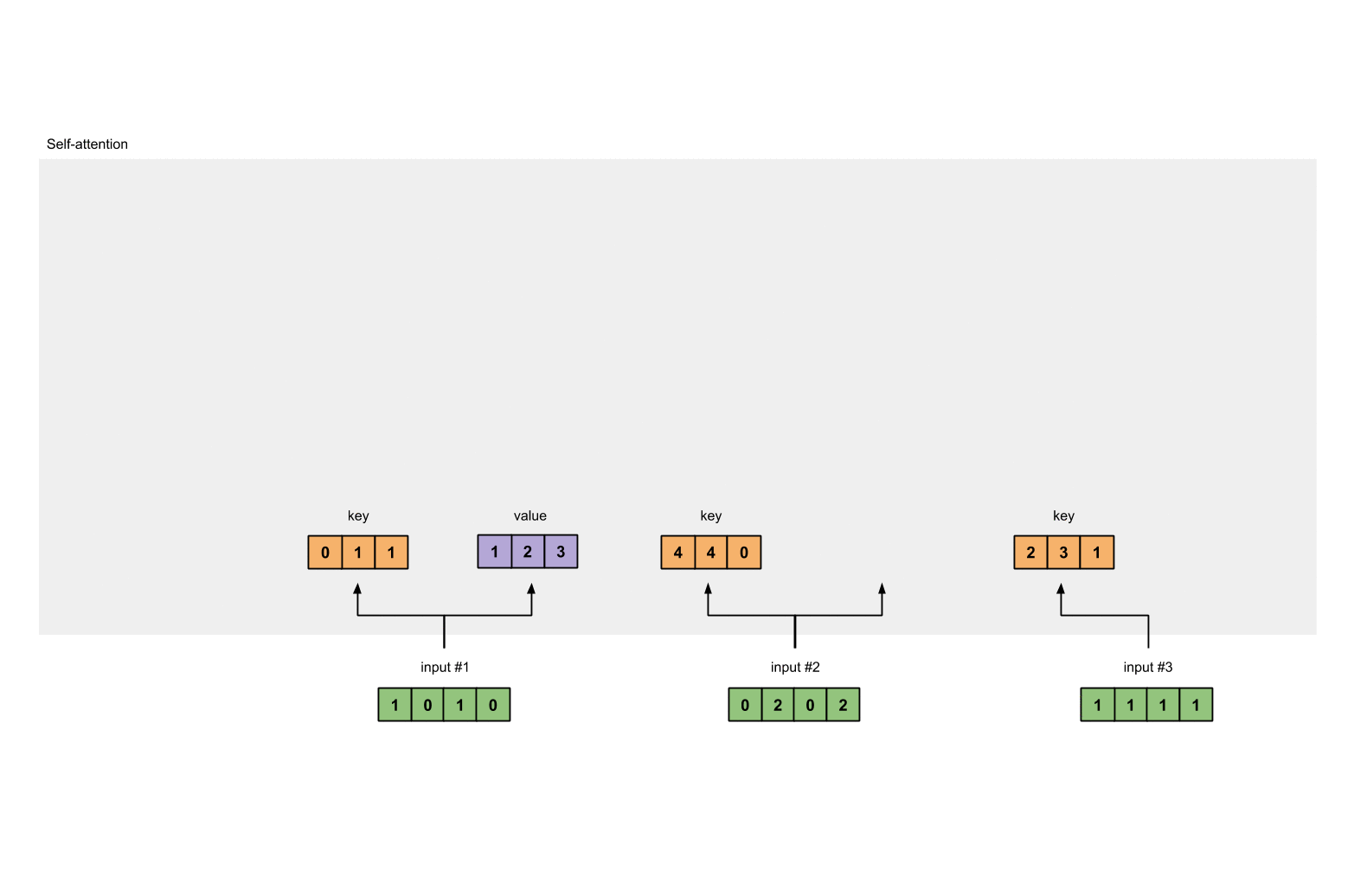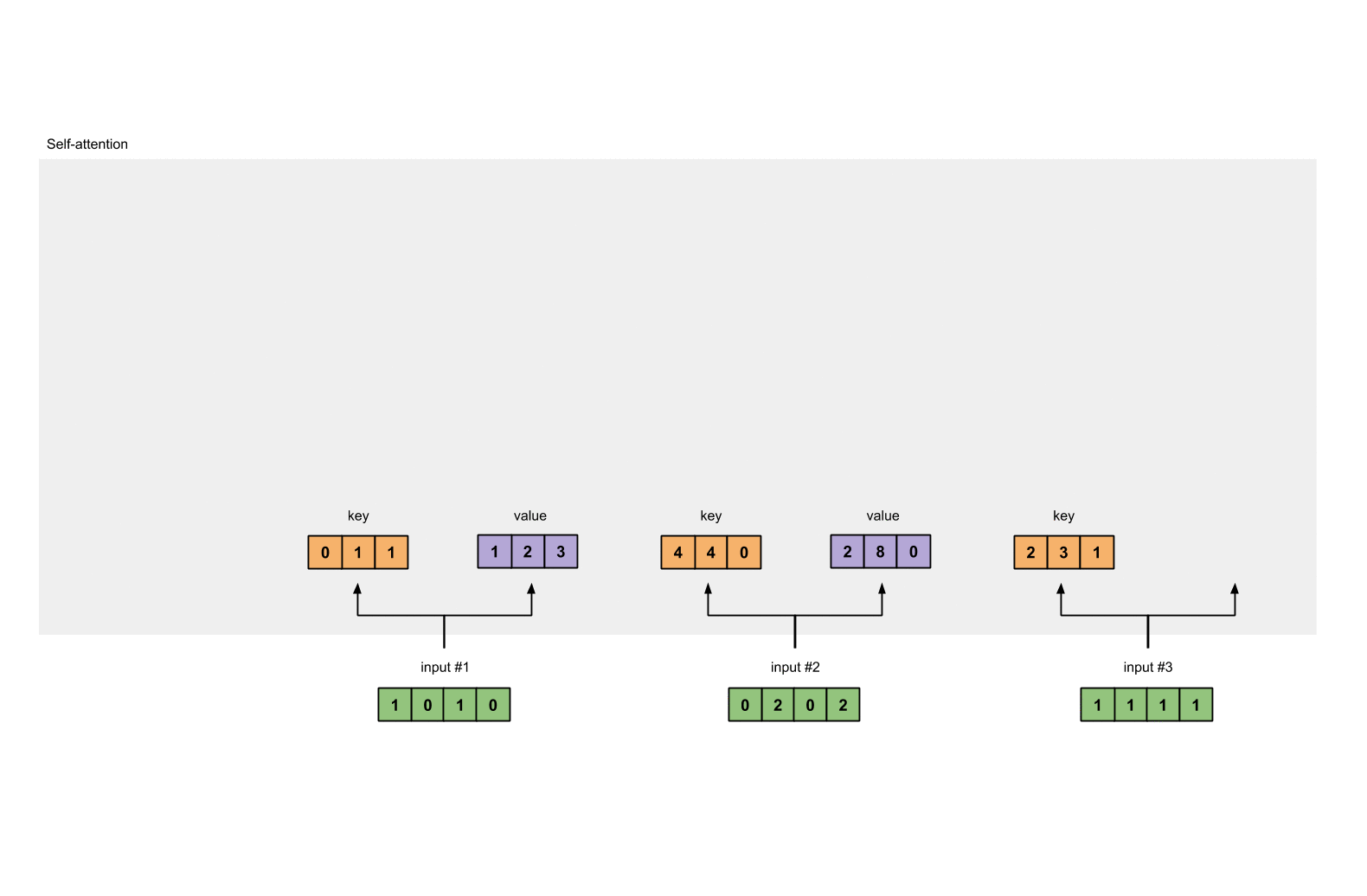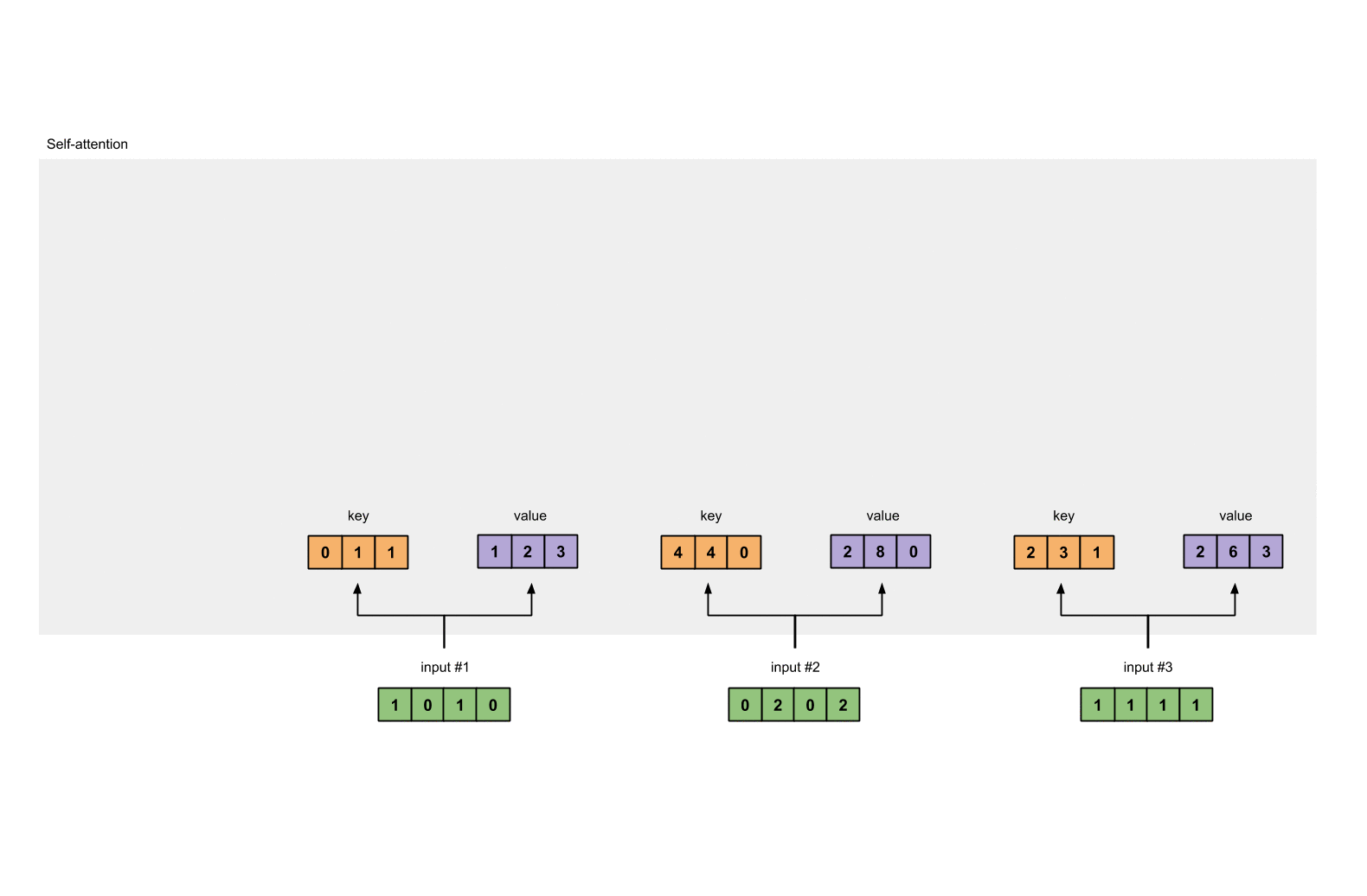
Value :
[0, 2, 0]
[1, 0, 1, 0] [0, 3, 0] [1, 2, 3]
[0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 6, 3]
query :
[1, 0, 1]
[1, 0, 1, 0] [1, 0, 0] [1, 0, 2]
[0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2]
[1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
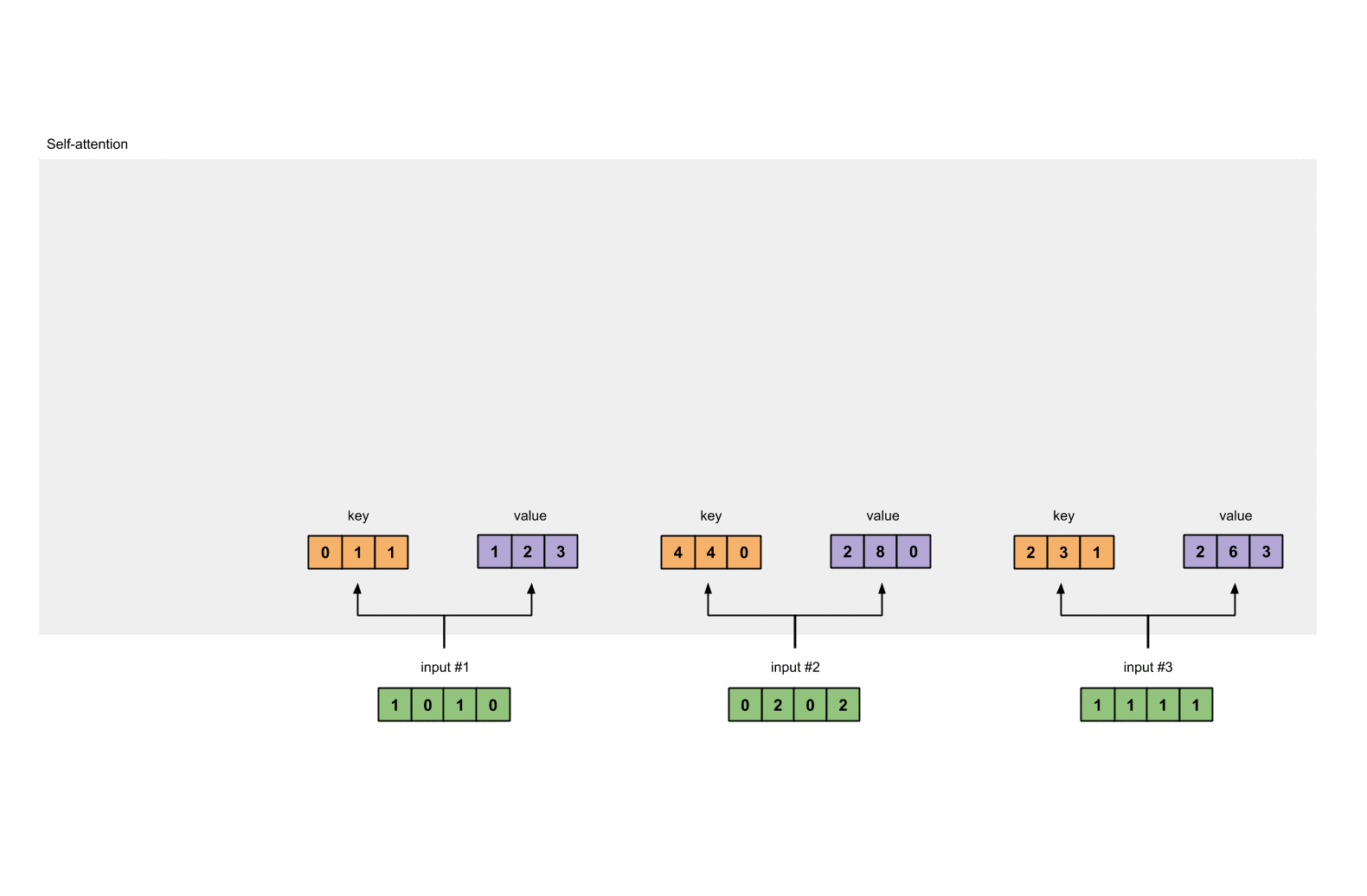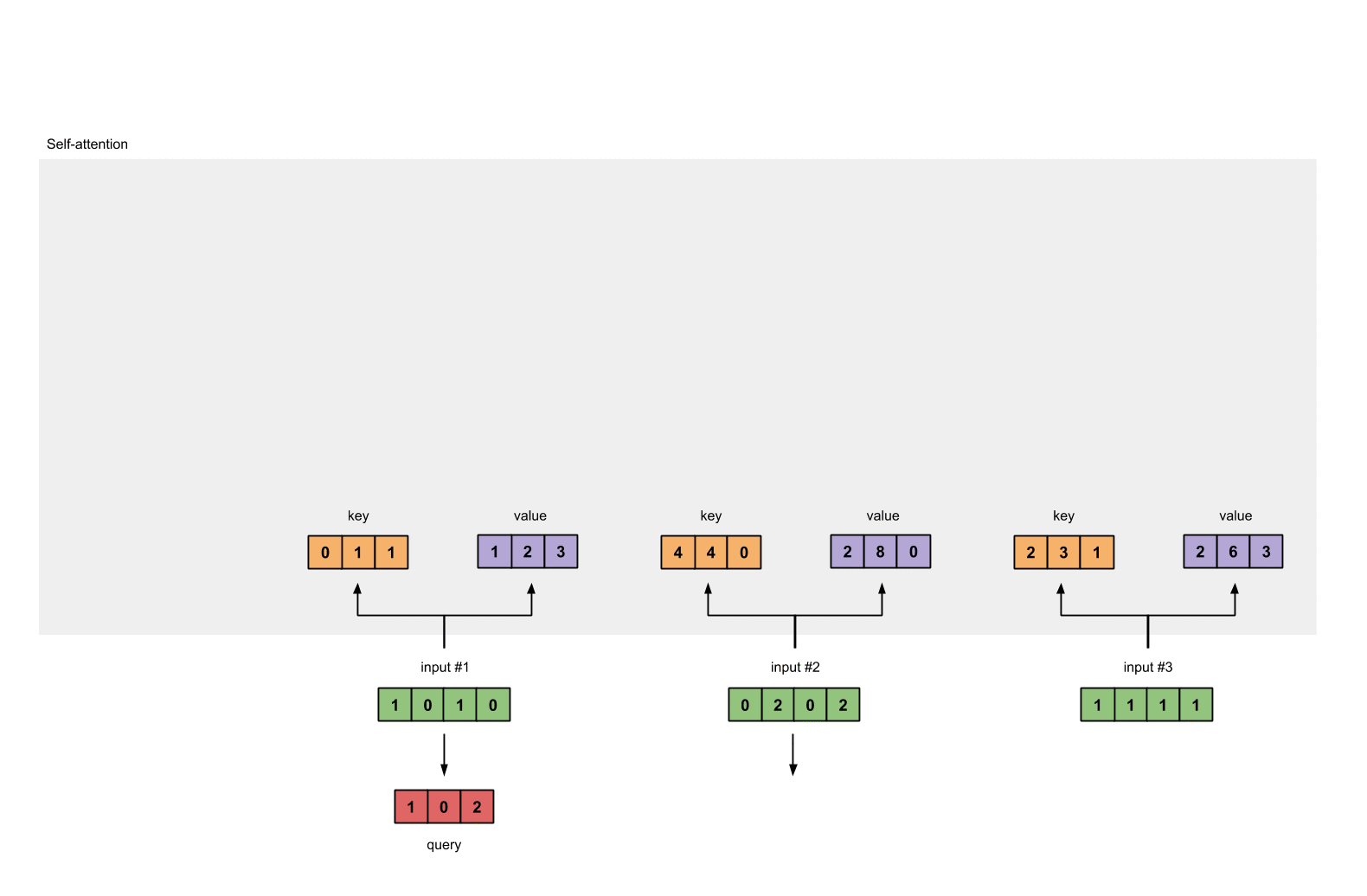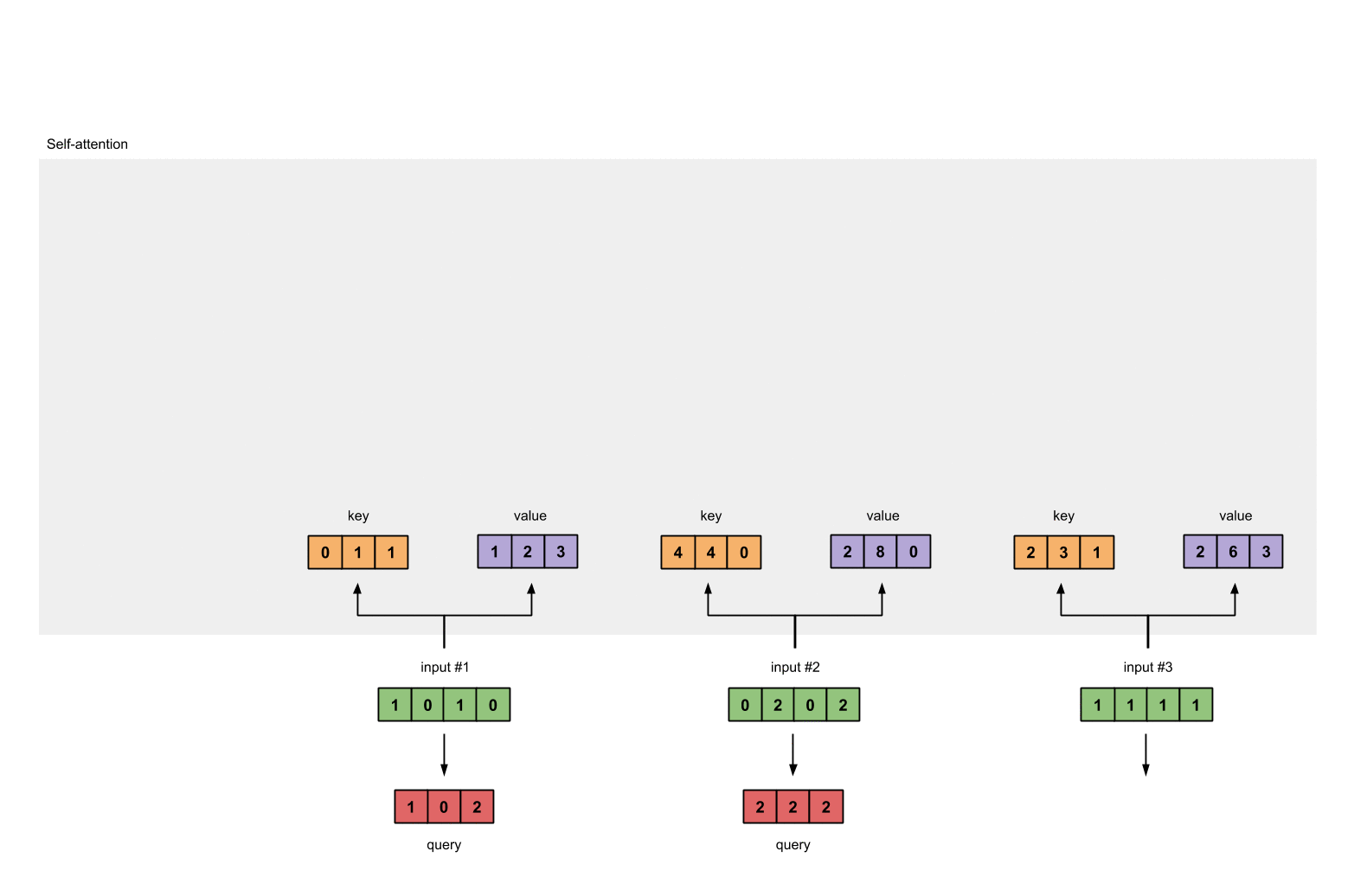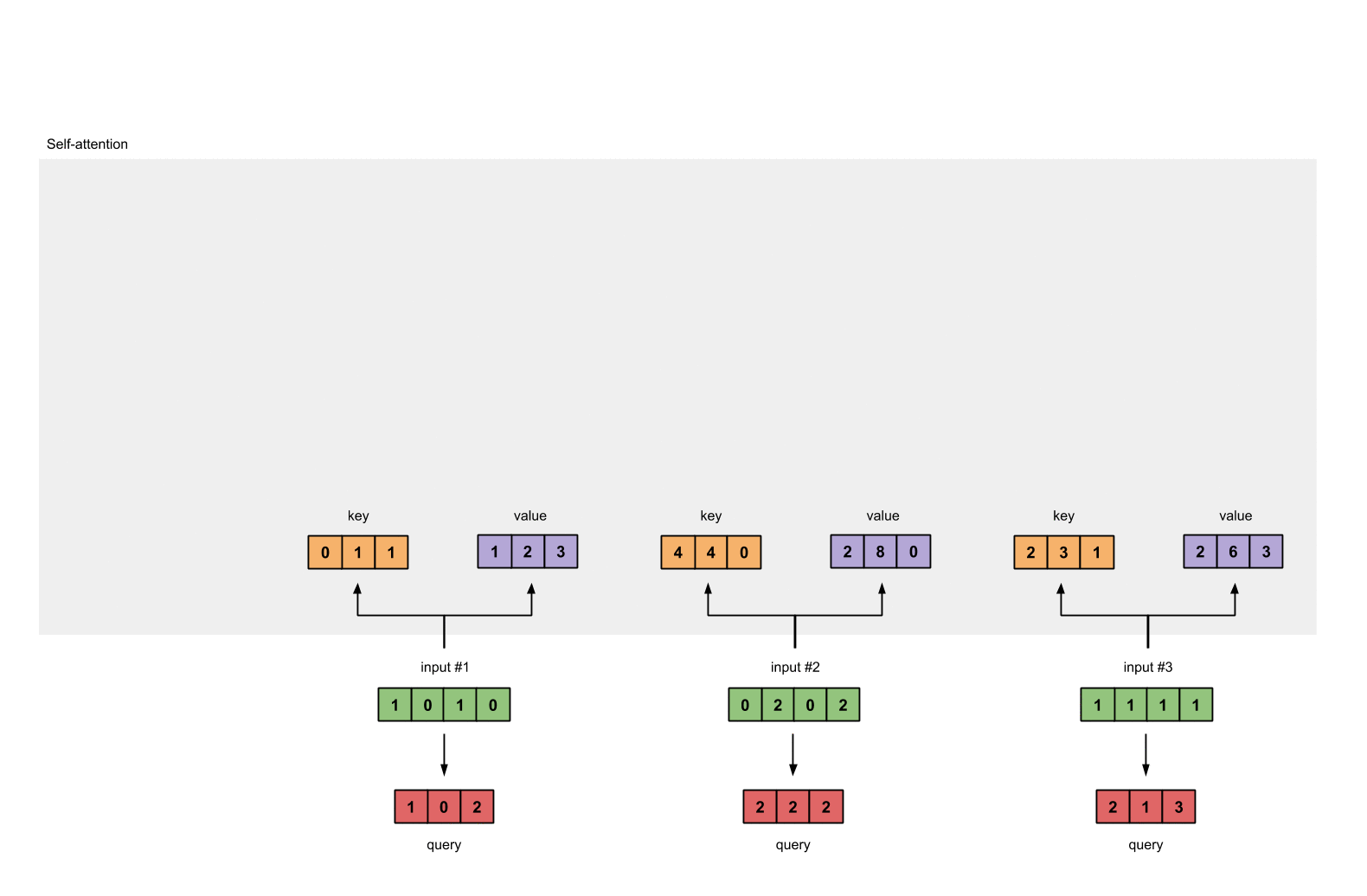
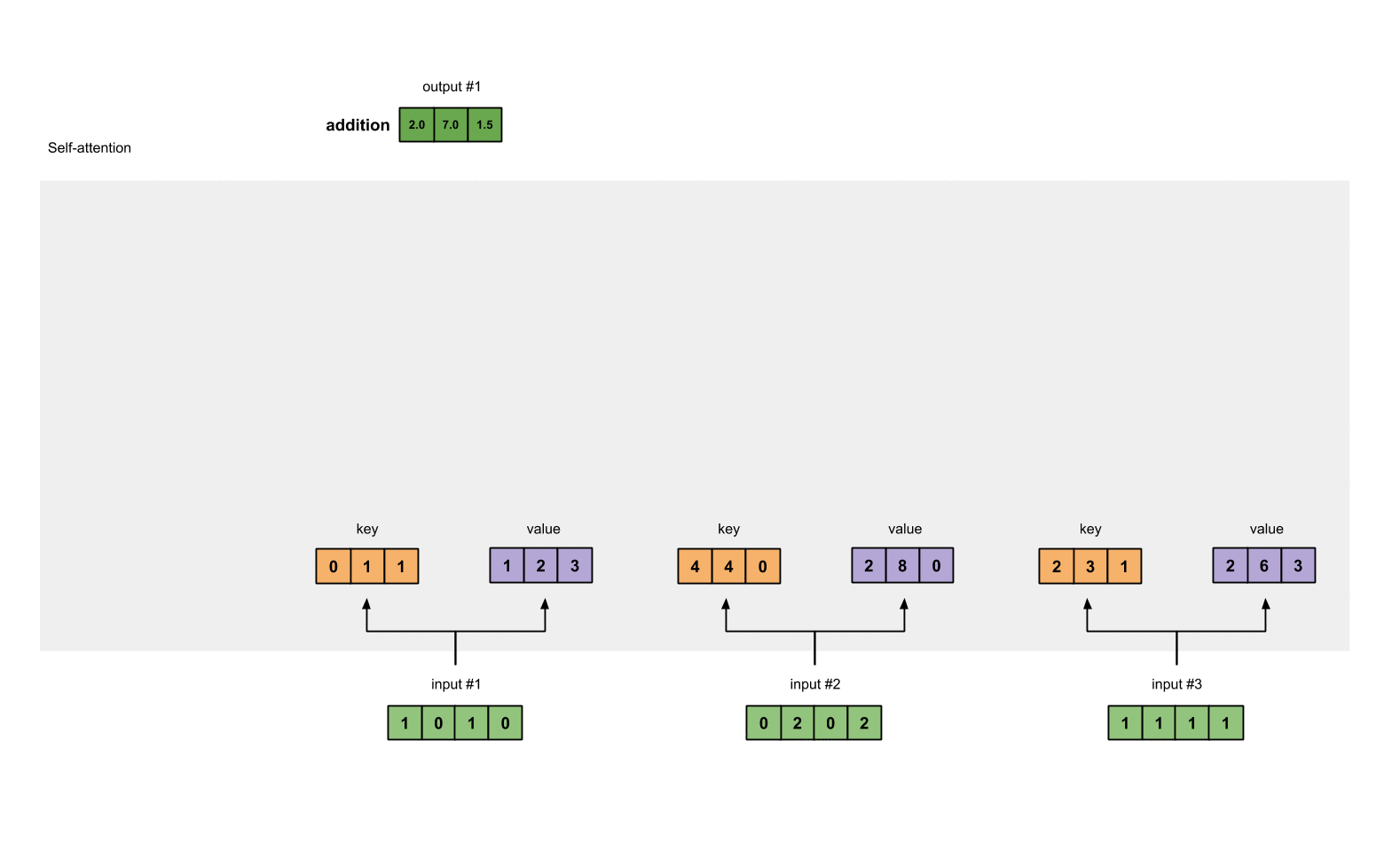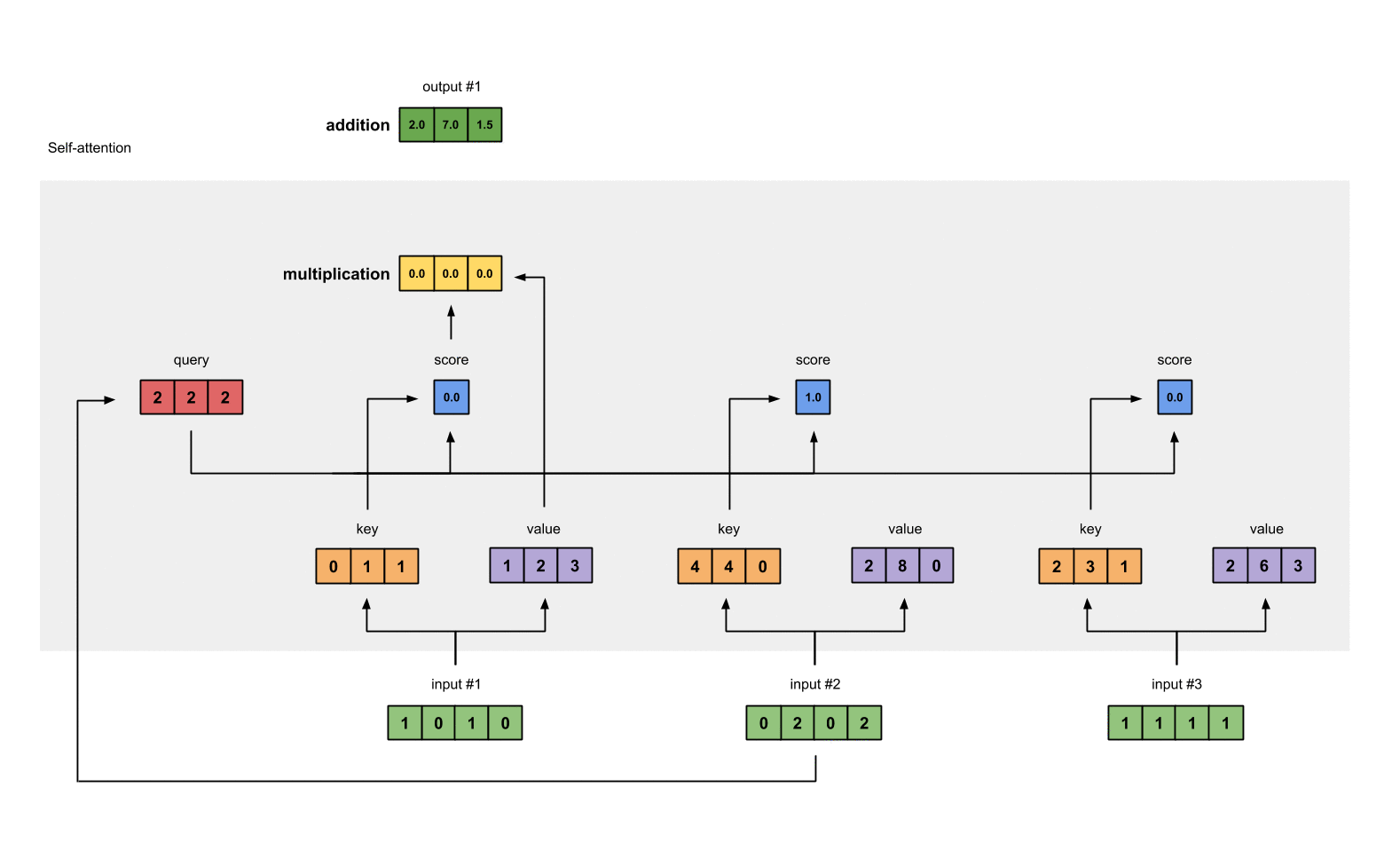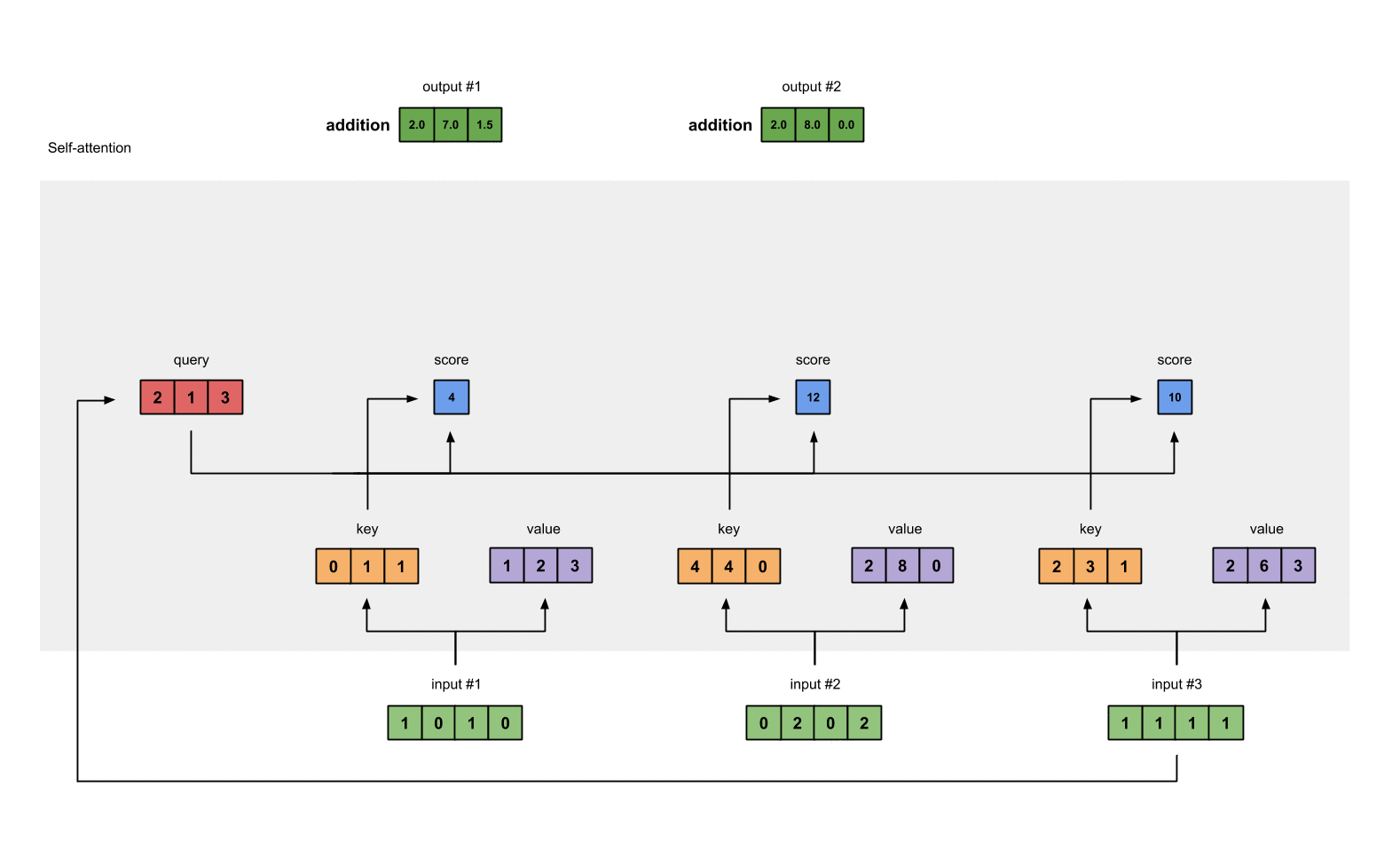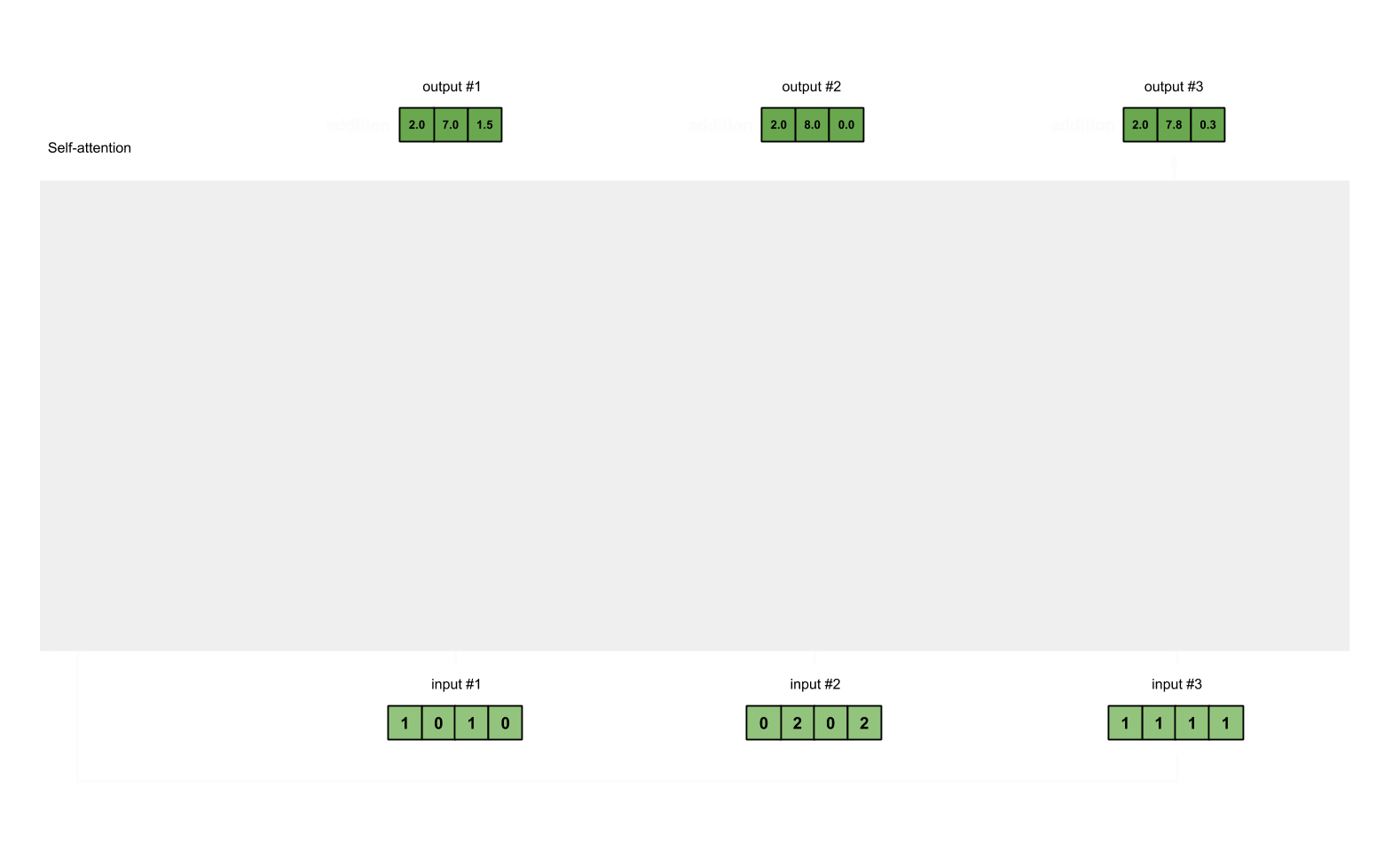
Step 4: Calculate attention scores for Input 1
attention scores 구하기, query(red)와 모든 keys(orange)와 내적한다.
query $\odot$ keys = attention scores
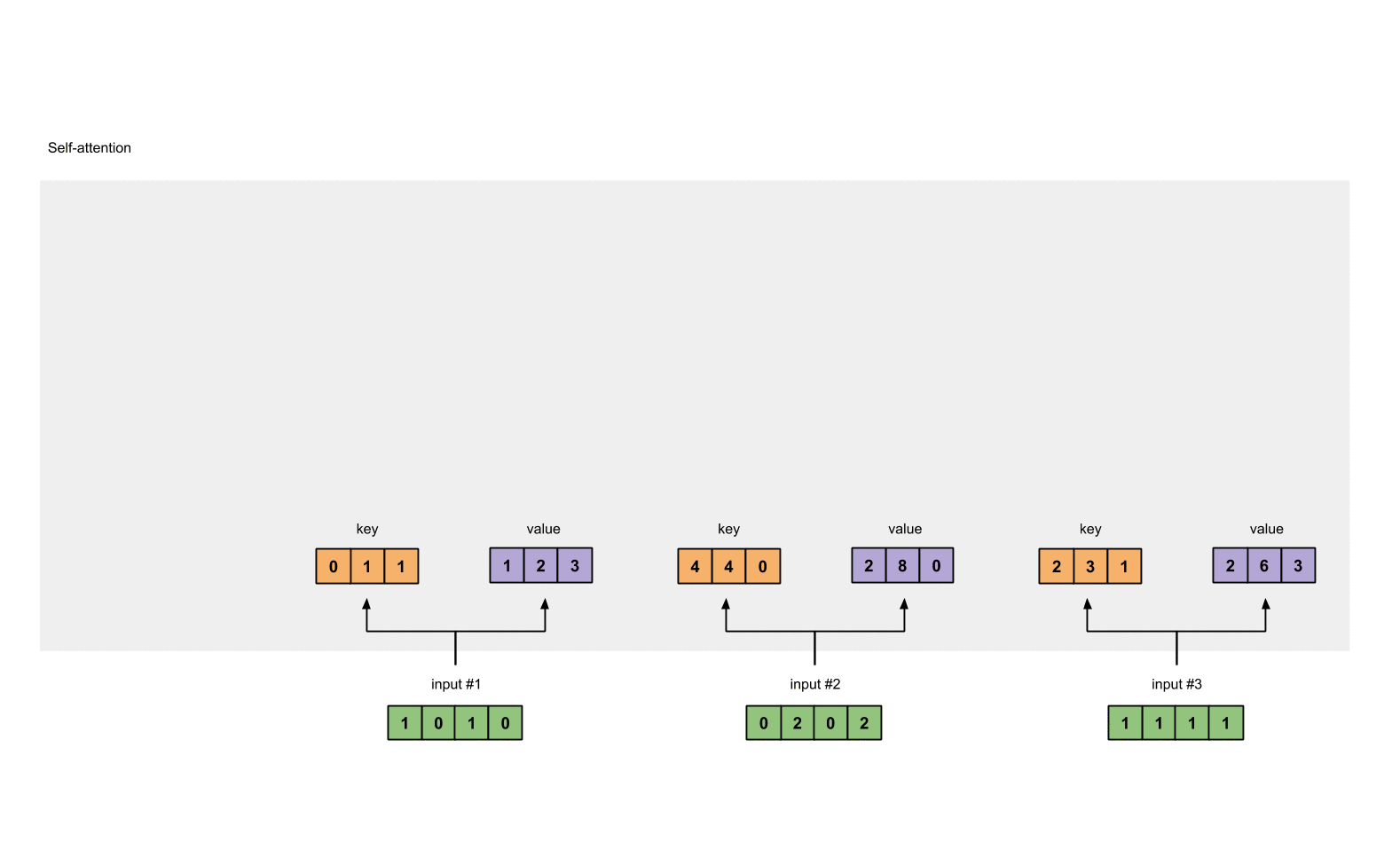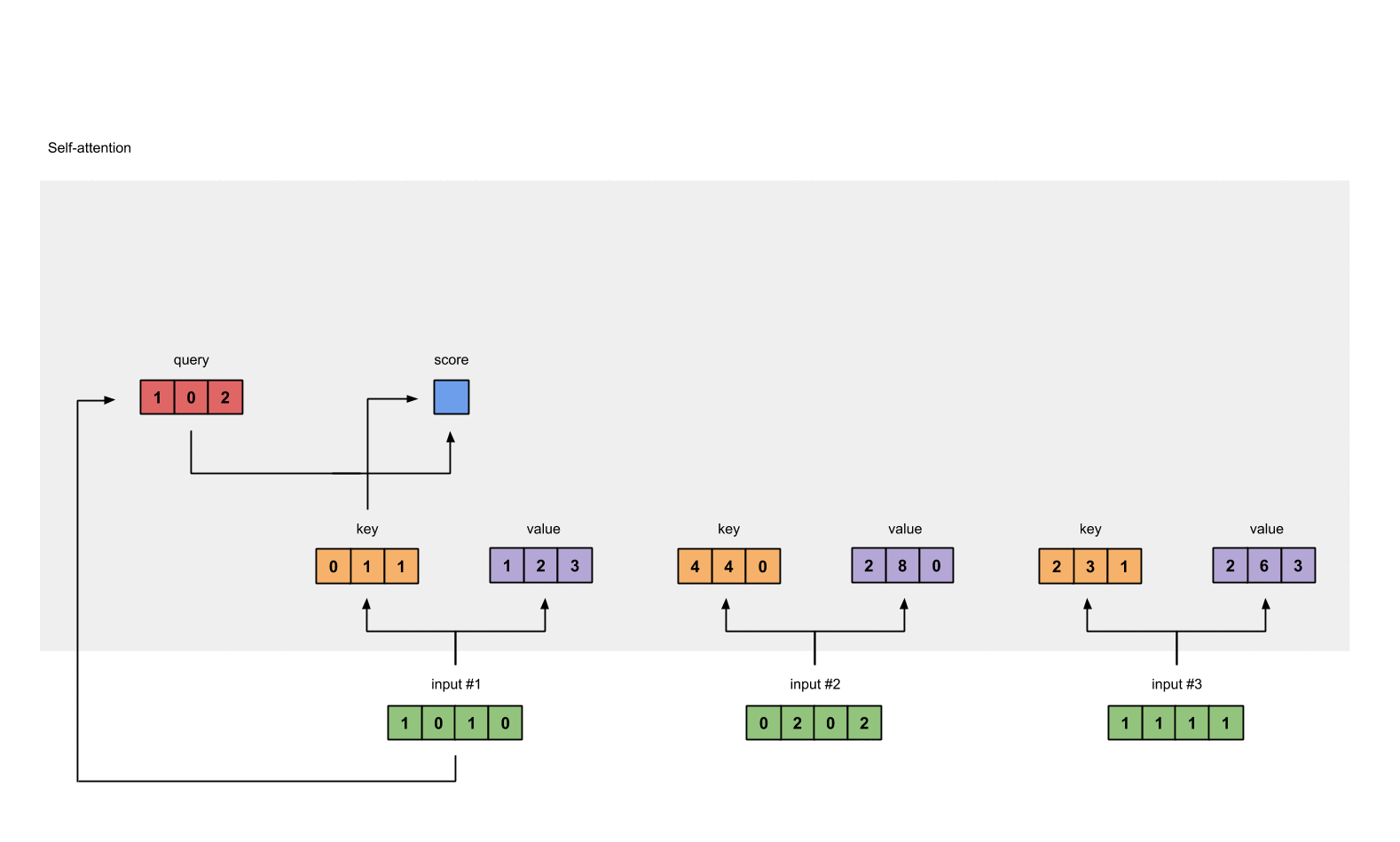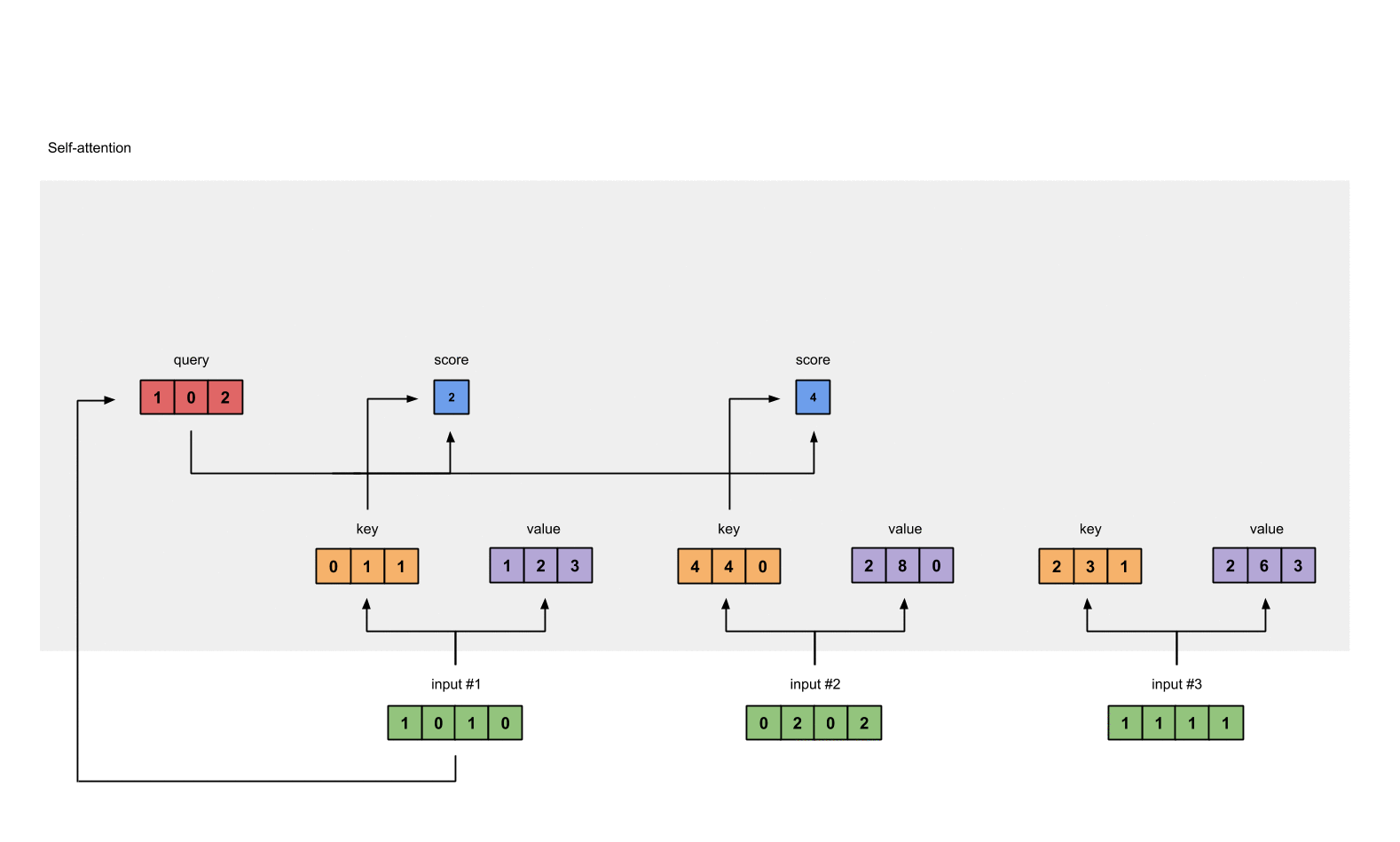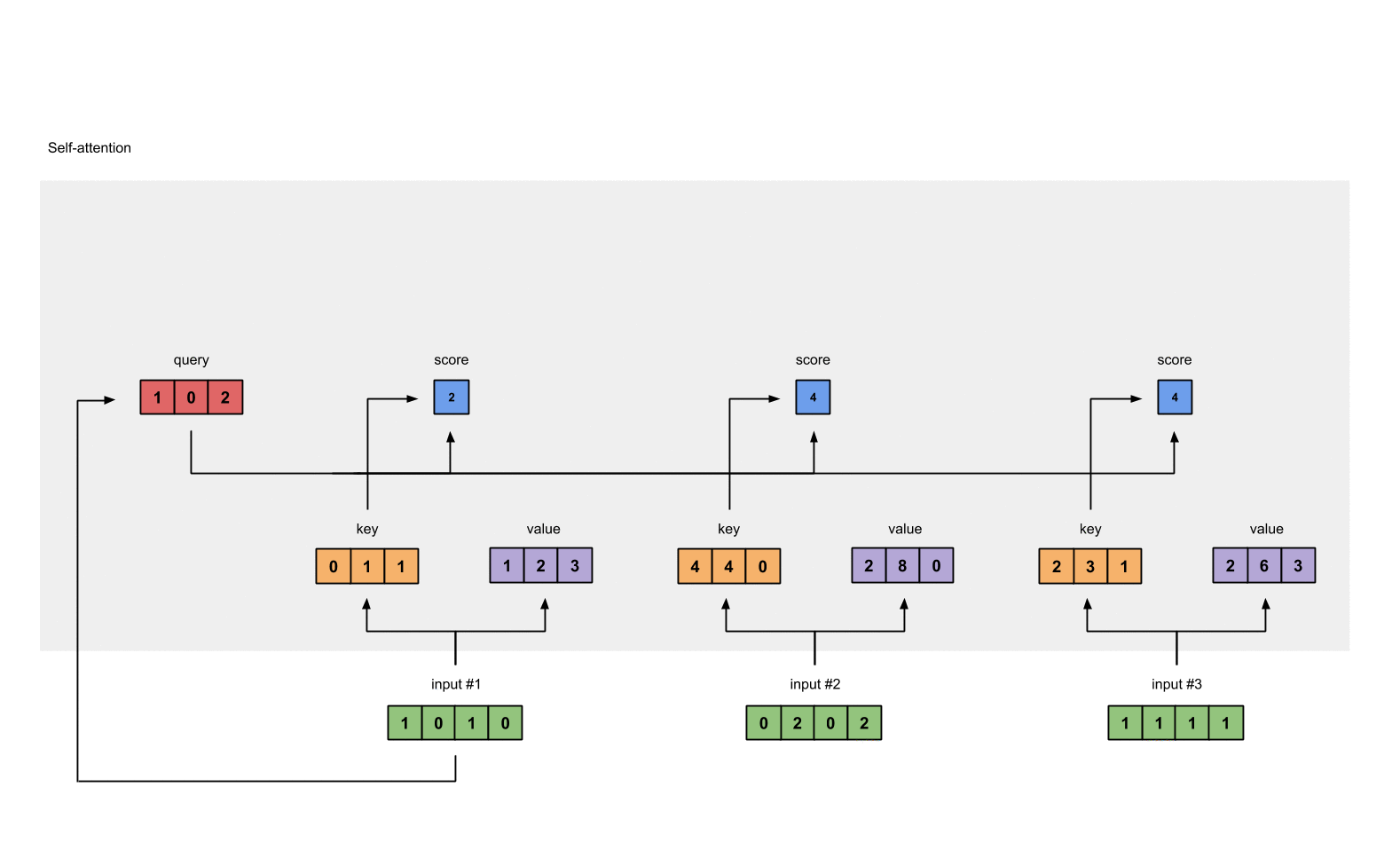
#1 attention scores :
#input 1 query & #1 key = 2
#input 1 query & #2 key = 4
#input 1 query & #3 key = 4
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]
Step 5: Calculate softmax
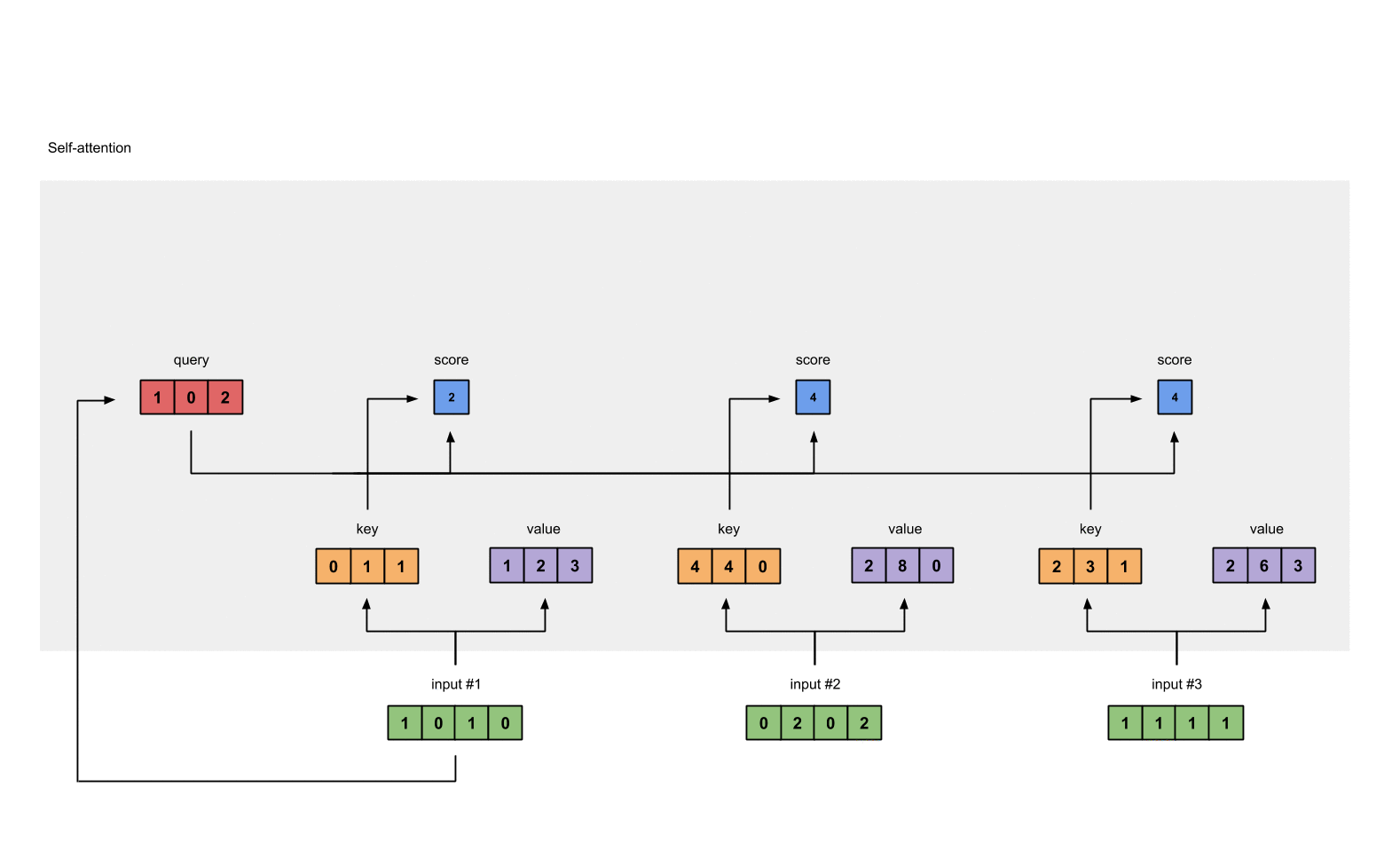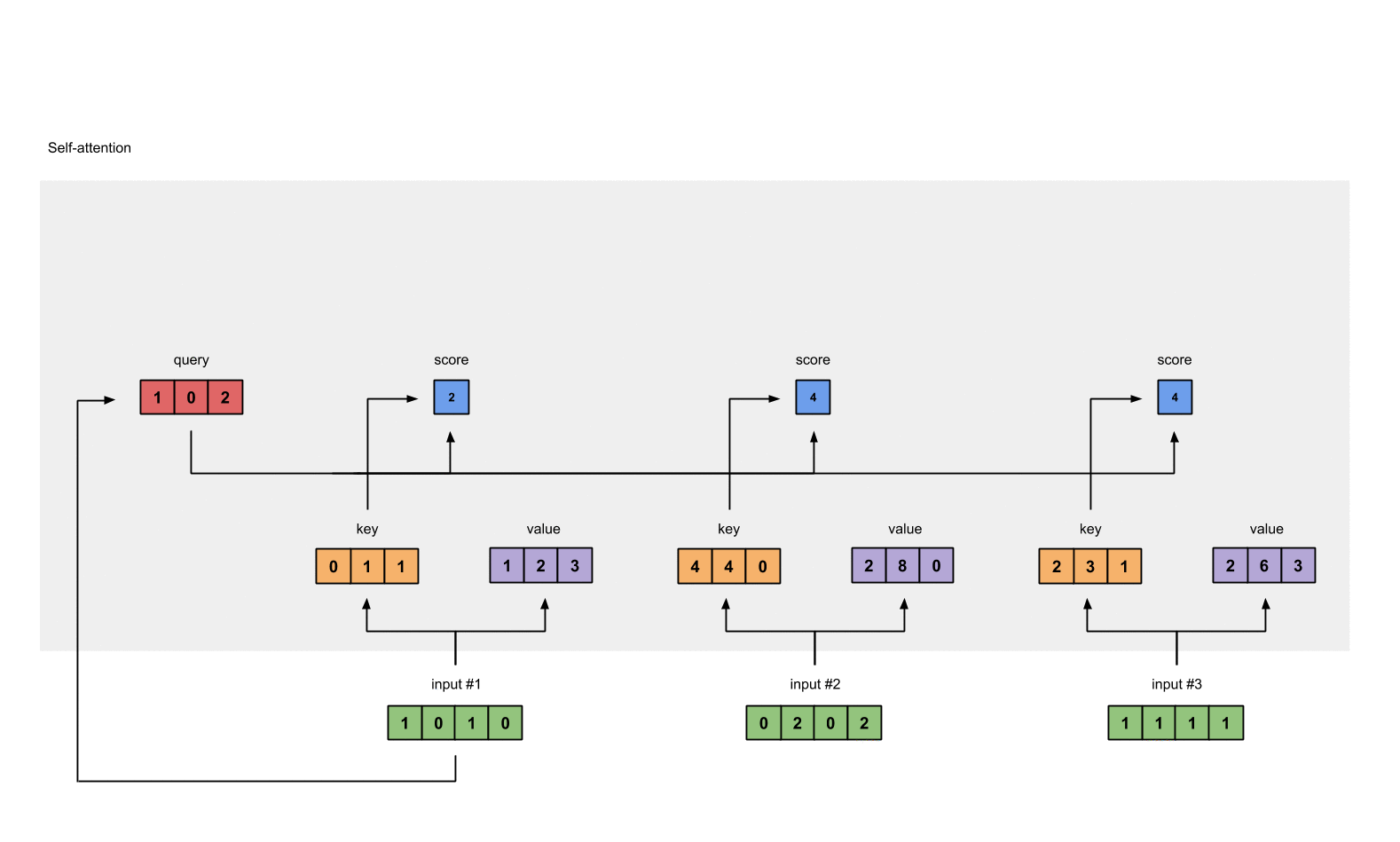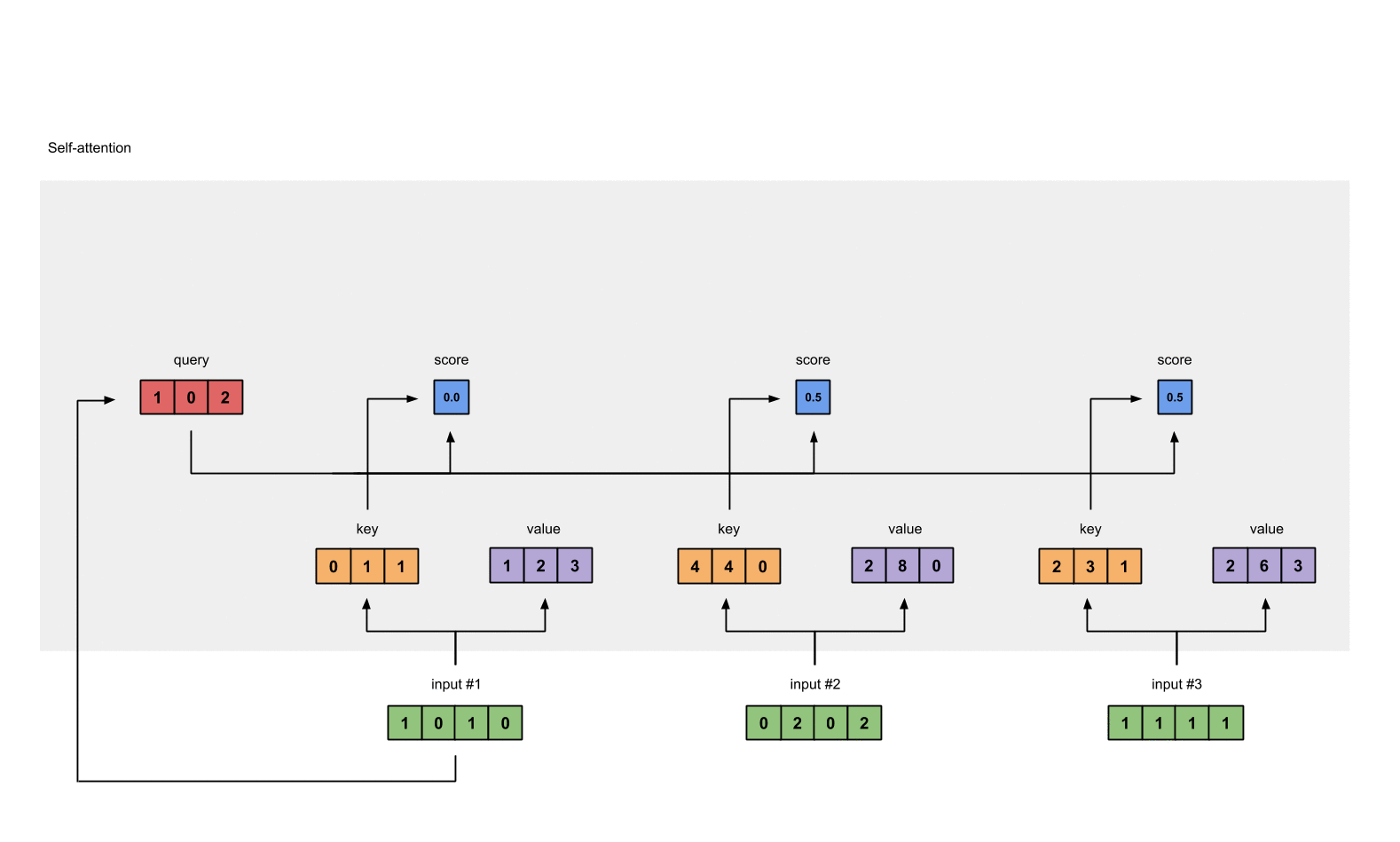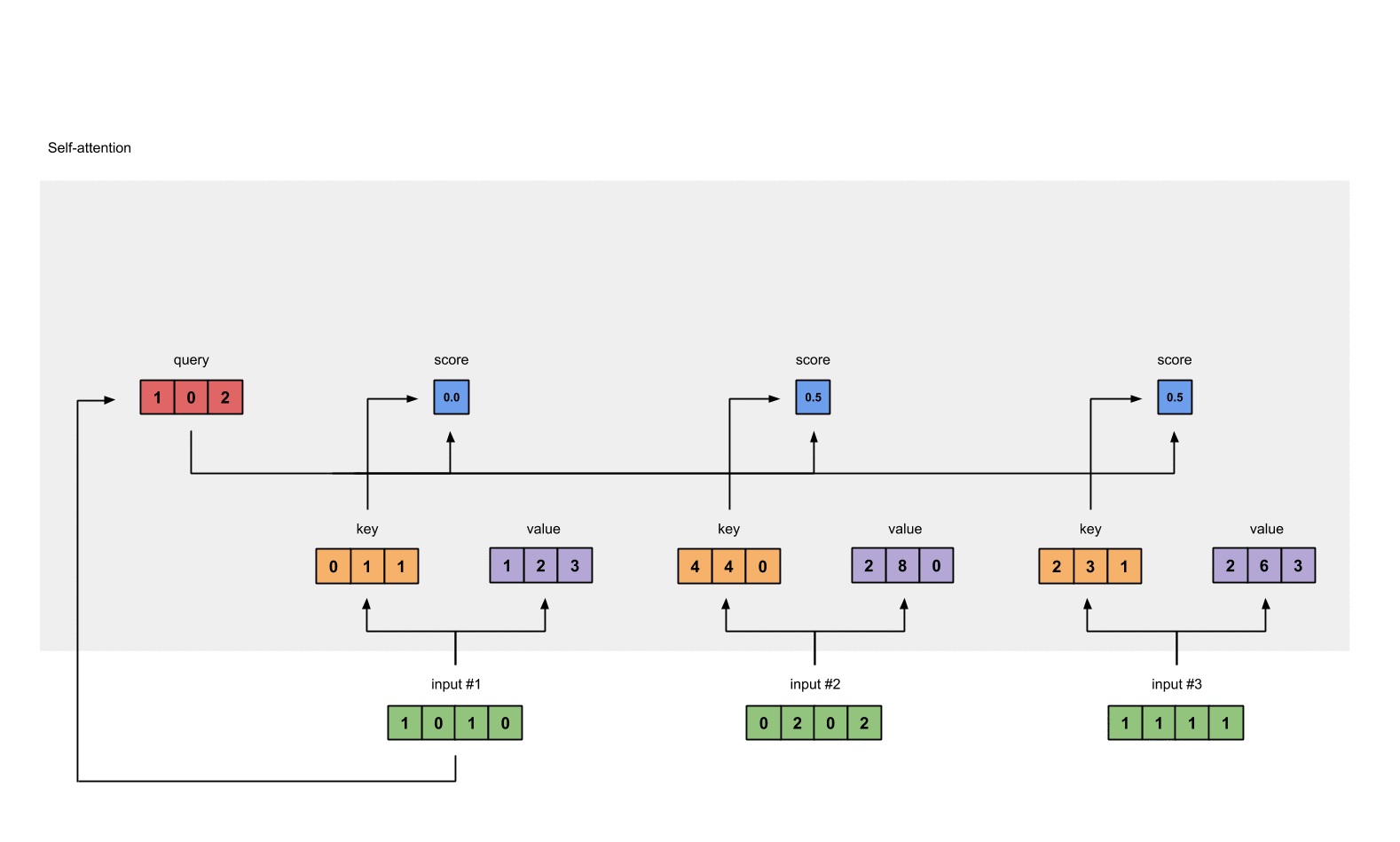
attention scores 값을 softmax로 0~1로 확률값으로 변형한다.
softmax([2, 4, 4]) = [0.0, 0.5, 0.5]
Step 6: Multiply scores with values
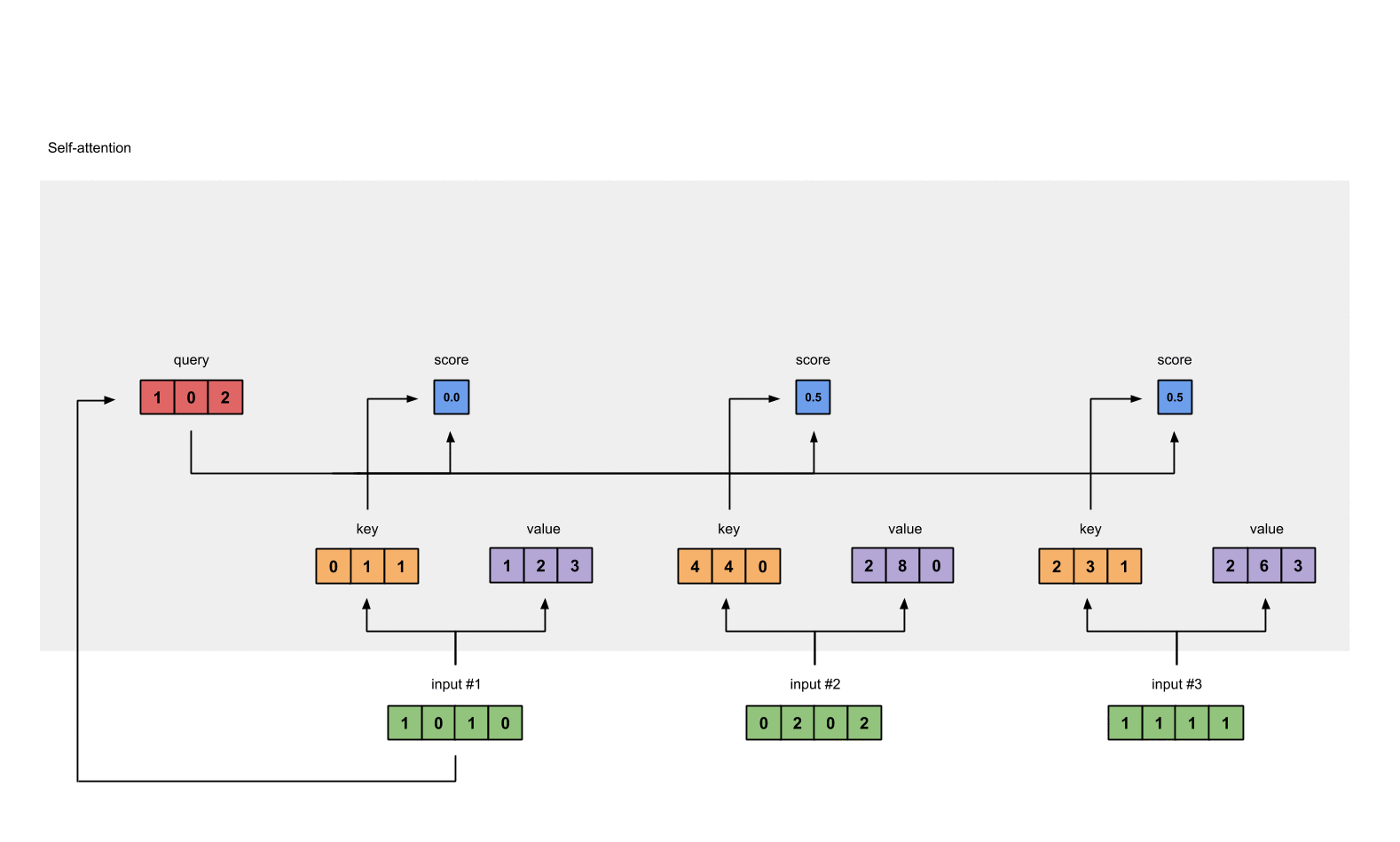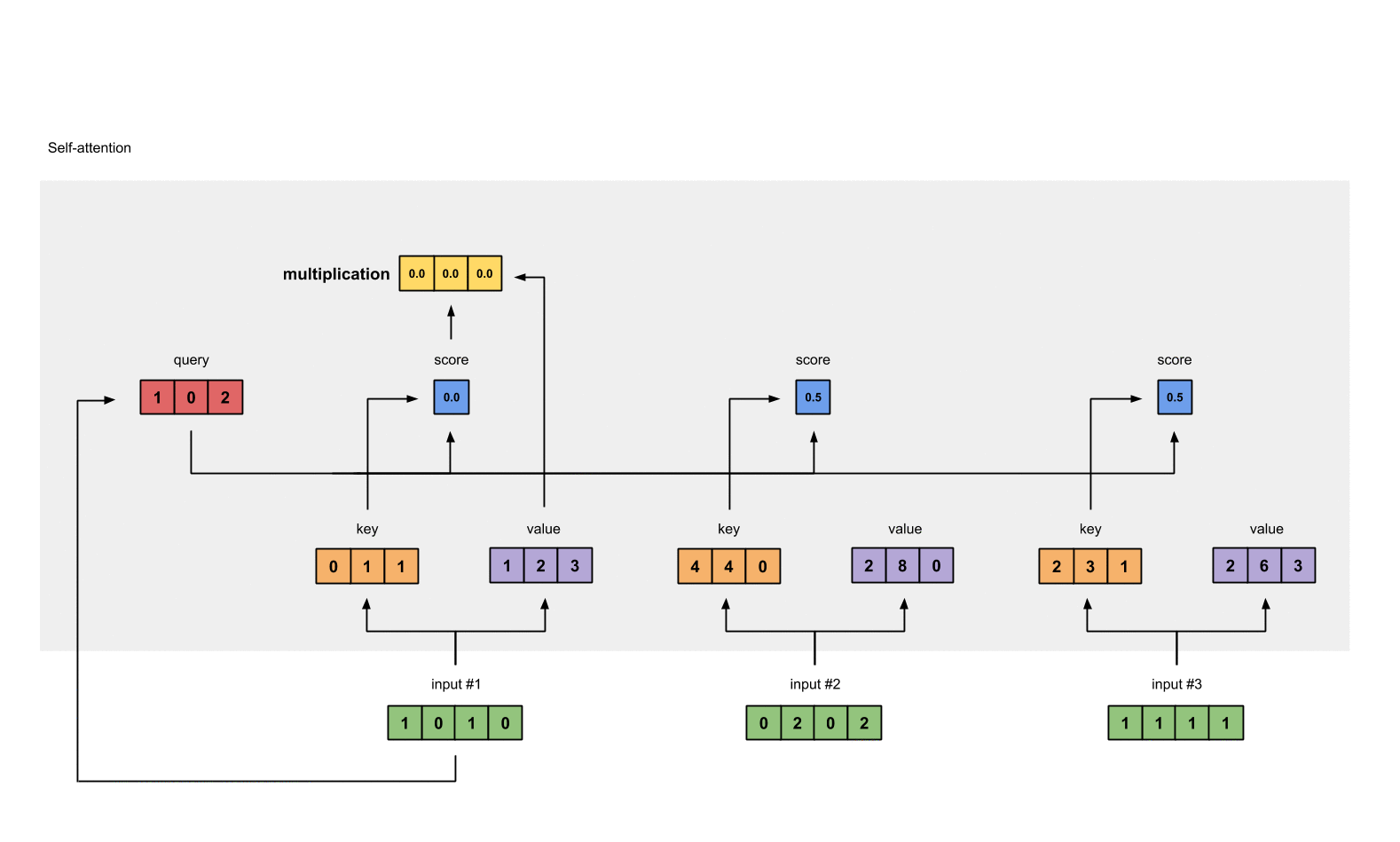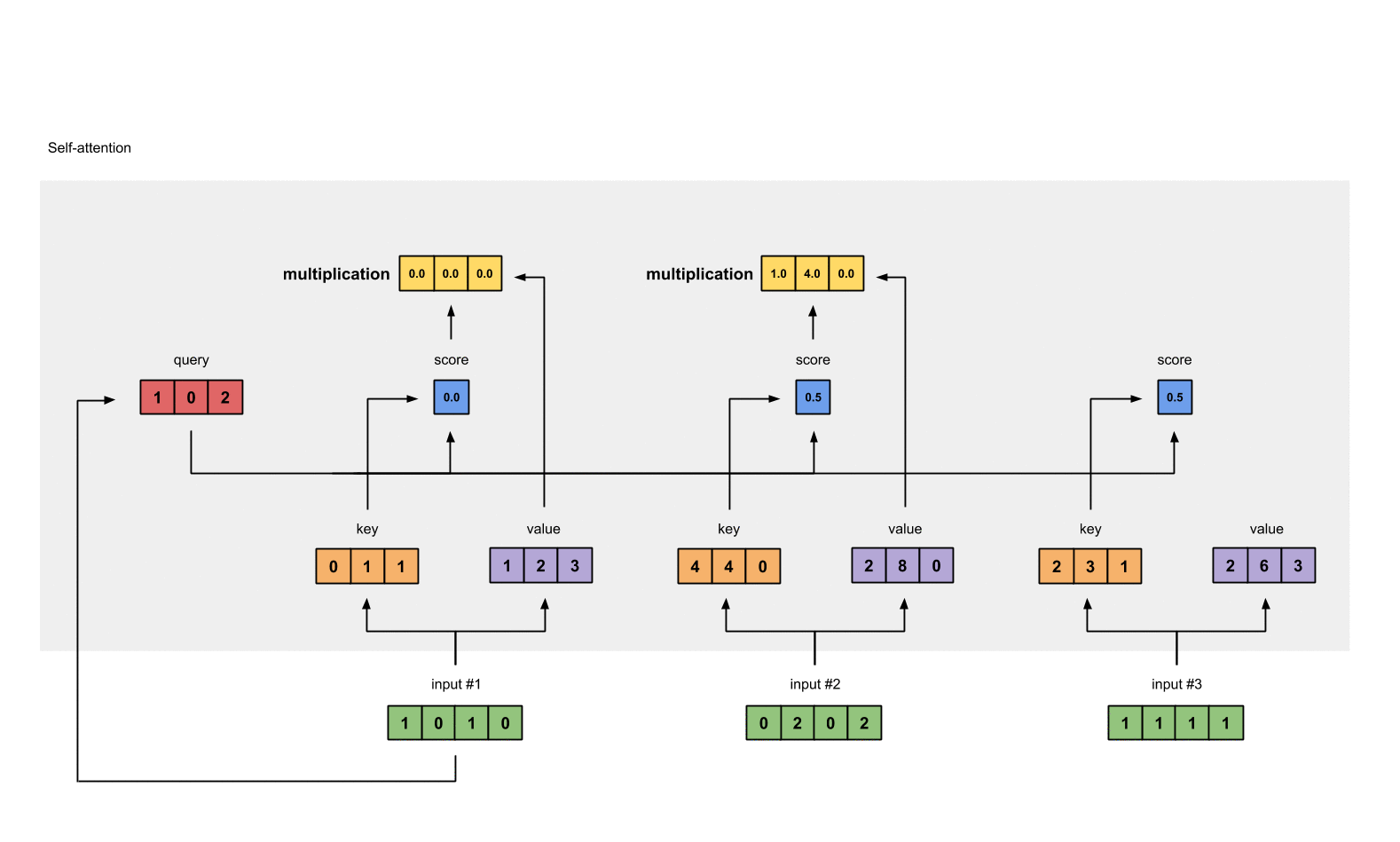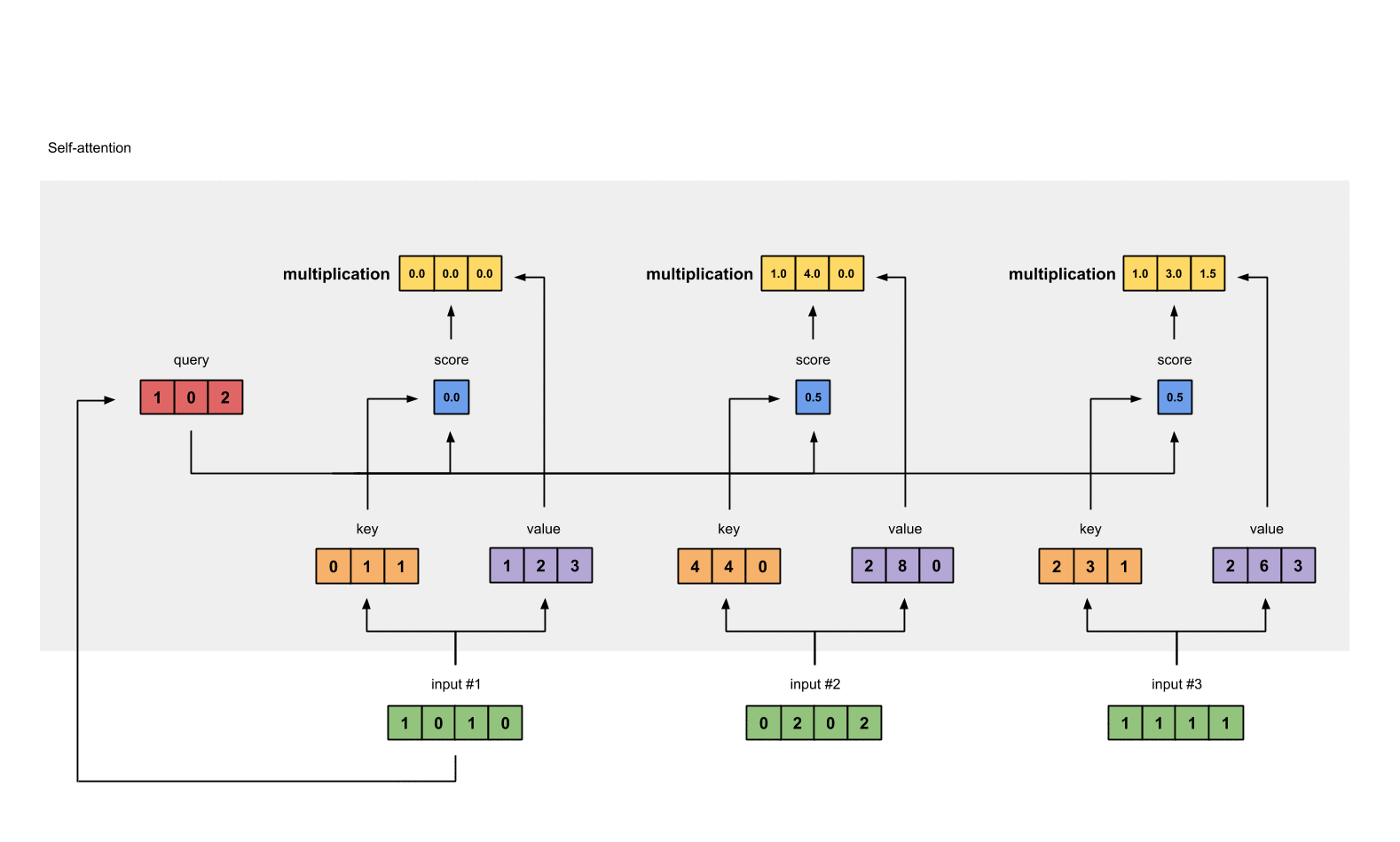
softmax([2, 4, 4]) = [0.0, 0.5, 0.5] softmax로 변환한 attention scores값을 가중치(weighted values)로 사용해 각 value와 곱한다.
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
Step 7: Sum weighted values to get Output 1
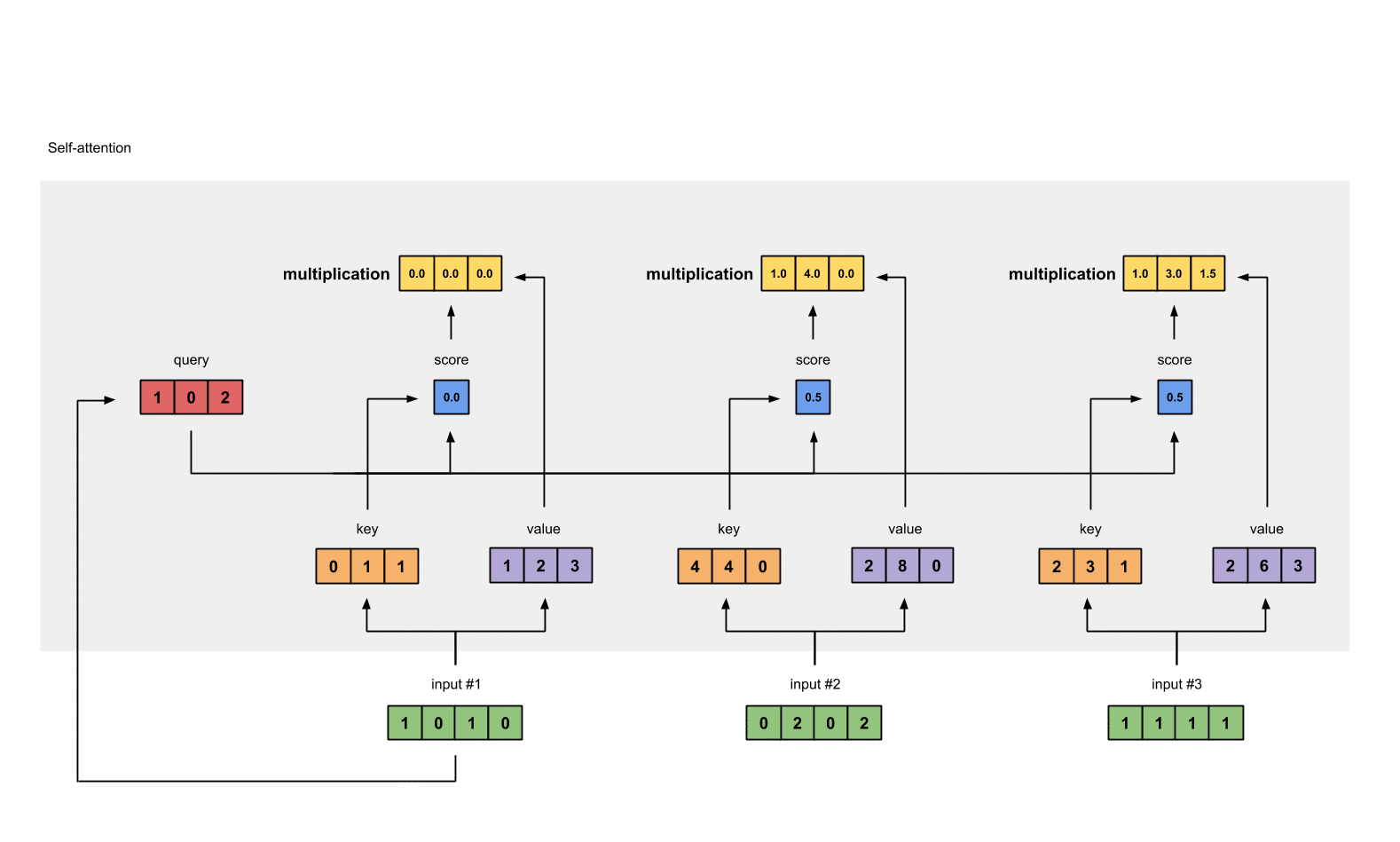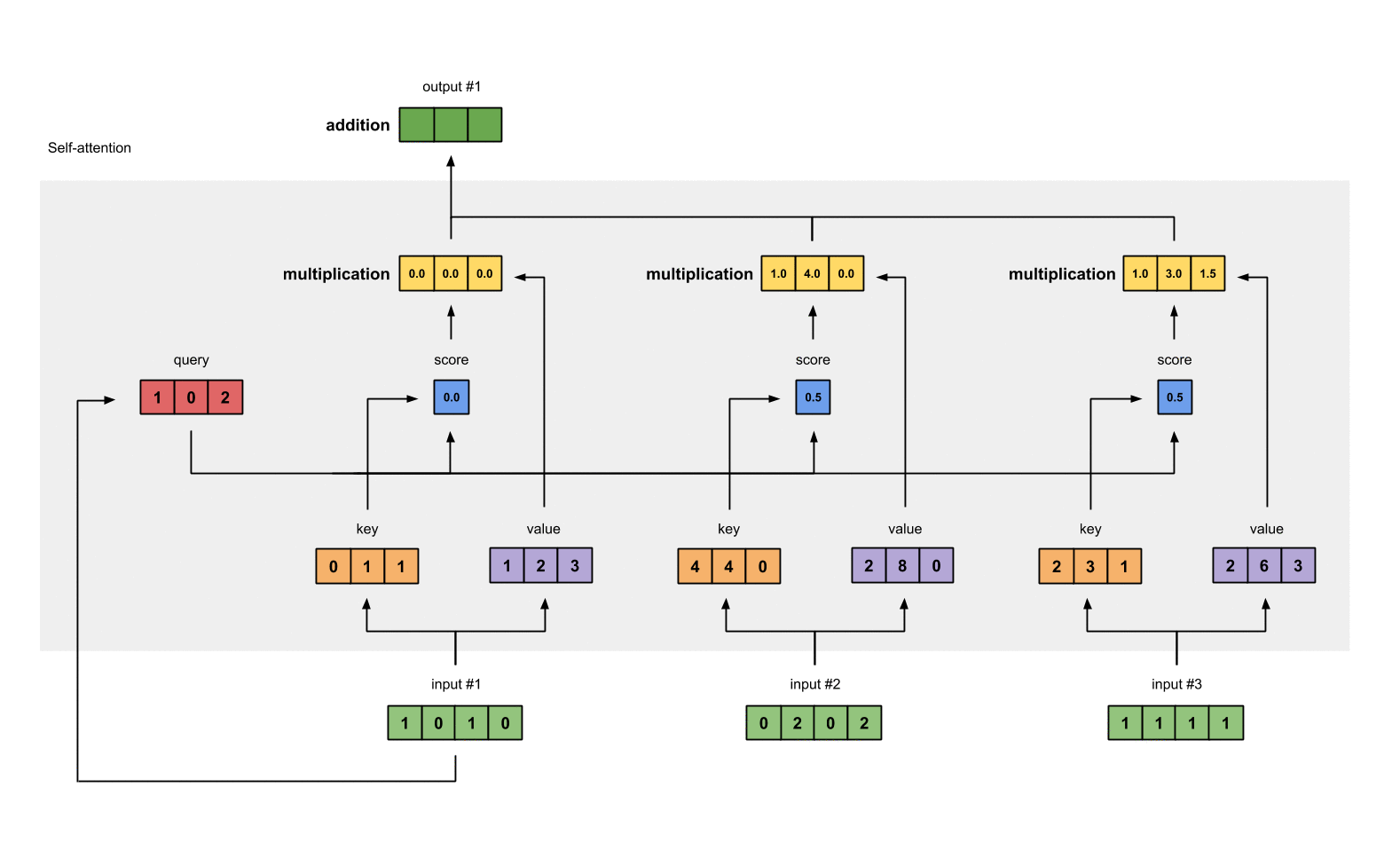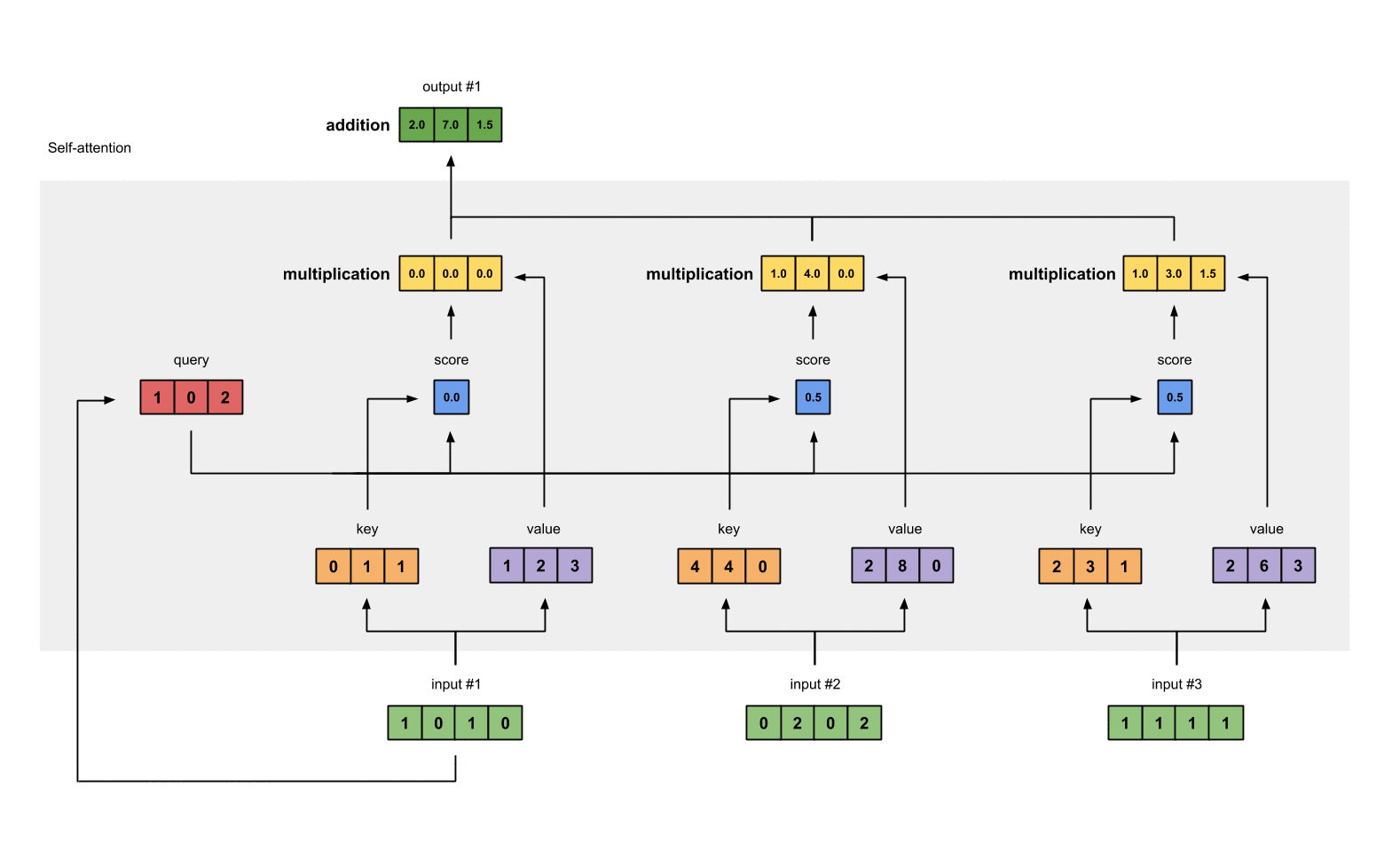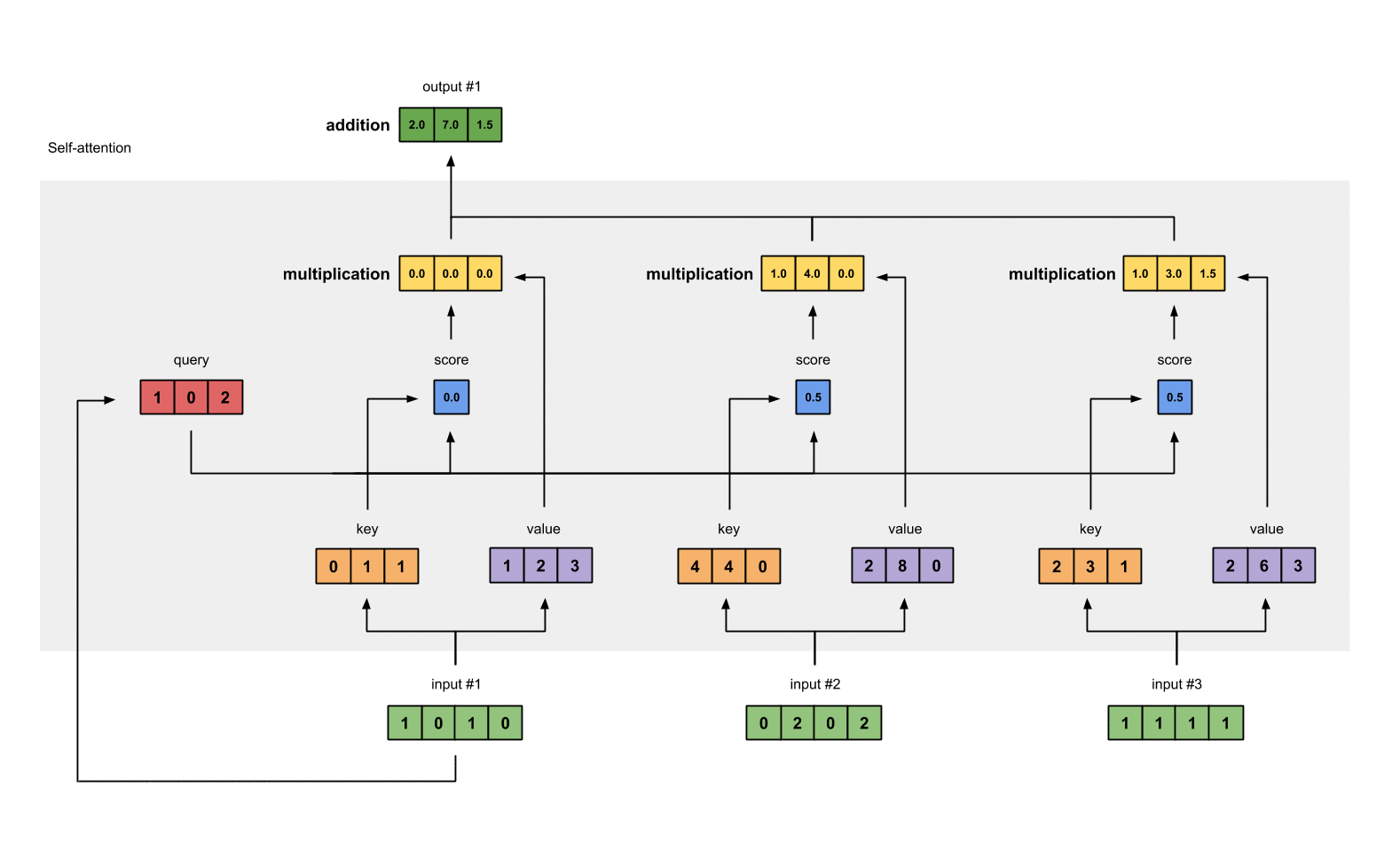
가중치 값 (weighted values (yellow))과 value 값을 곱한 값을 모두 합친다.
[0.0, 0.0, 0.0]
+ [1.0, 4.0, 0.0]
+ [1.0, 3.0, 1.5]
-----------------
= [2.0, 7.0, 1.5] <- input #1의 output
Step 8: Repeat for Input 2 & Input 3
input #2와 input #3에도 동일 연산
## query와 key의 같은 dim이어야한다. 내적을 해야하기 때문에, 그러나 value의 dim은 output의 모양에 맞추면 된다.
[출처] towardsdatascience.com/illustrated-self-attention-2d627e33b20a
NLP에 활용
'👾 Deep Learning' 카테고리의 다른 글
| [Transformer] Positional Encoding (3) (0) | 2021.02.20 |
|---|---|
| [Transformer] Position-wise Feed-Forward Networks (2) (0) | 2021.02.20 |
| VAE(Variational Autoencoder) (3) MNIST (0) | 2021.02.18 |
| Tensorflow Initializer 초기화 종류 (0) | 2021.02.18 |
| VAE(Variational Autoencoder) (2) (0) | 2021.02.18 |
input#1을 기준으로 #2, #3와의 관계를 score로 만들고 output #1을 만든다. 그리고 #2와 #1, #3와의 score를 구하고 다음 #으로 넘어가면서 score를 구한다. 이 점수 score를 모아 attention map을 만든다.
1. Illustrations
The illustrations are divided into the following steps:
- Prepare inputs
- Initialise weights
- Derive key, query and value
- Calculate attention scores for Input 1
- Calculate softmax
- Multiply scores with values
- Sum weighted values to get Output 1
- Repeat steps 4–7 for Input 2 & Input 3
Step 1: Prepare inputs
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
데이터 입력
Step 2: Initialise weights
각 인풋 값에 가중치를 부여한 뒤 값을 구한다.
신경망(neural network)은 연속확률 분포인 Gaussian, Xavier, He Kaming 분포를 이용한다. 이 초기화는 training 전에 한번 사용한다.
key: [[0, 0, 1], query: [[1, 0, 1], value: [[0, 2, 0],
[1, 1, 0], [1, 0, 0], [0, 3, 0],
[0, 1, 0], [0, 0, 1], [1, 0, 3],
[1, 1, 0]] [0, 1, 1]] [1, 1, 0]]
Step 3: Derive key, query and value
내적 연산을
Input #1 : [1, 0, 1, 0]
[0, 0, 1]
[1, 0, 1, 0] X [1, 1, 0] = [0, 1, 1]
[0, 1, 0]
[1, 1, 0]
input #2 : [0, 2, 0, 2]
[0, 0, 1]
[0, 2, 0, 2] x [1, 1, 0] = [4, 4, 0]
[0, 1, 0]
[1, 1, 0]
# key :
[0, 0, 1]
[1, 0, 1, 0] [1, 1, 0] [0, 1, 1]
[0, 2, 0, 2] x [0, 1, 0] = [4, 4, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 3, 1]
Value :
[0, 2, 0]
[1, 0, 1, 0] [0, 3, 0] [1, 2, 3]
[0, 2, 0, 2] x [1, 0, 3] = [2, 8, 0]
[1, 1, 1, 1] [1, 1, 0] [2, 6, 3]
query :
[1, 0, 1]
[1, 0, 1, 0] [1, 0, 0] [1, 0, 2]
[0, 2, 0, 2] x [0, 0, 1] = [2, 2, 2]
[1, 1, 1, 1] [0, 1, 1] [2, 1, 3]
Step 4: Calculate attention scores for Input 1
attention scores 구하기, query(red)와 모든 keys(orange)와 내적한다.
query $\odot$ keys = attention scores
#1 attention scores :
#input 1 query & #1 key = 2
#input 1 query & #2 key = 4
#input 1 query & #3 key = 4
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]
Step 5: Calculate softmax
attention scores 값을 softmax로 0~1로 확률값으로 변형한다.
softmax([2, 4, 4]) = [0.0, 0.5, 0.5]
Step 6: Multiply scores with values
softmax([2, 4, 4]) = [0.0, 0.5, 0.5] softmax로 변환한 attention scores값을 가중치(weighted values)로 사용해 각 value와 곱한다.
1: 0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
2: 0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
3: 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
Step 7: Sum weighted values to get Output 1
가중치 값 (weighted values (yellow))과 value 값을 곱한 값을 모두 합친다.
[0.0, 0.0, 0.0]
+ [1.0, 4.0, 0.0]
+ [1.0, 3.0, 1.5]
-----------------
= [2.0, 7.0, 1.5] <- input #1의 output
Step 8: Repeat for Input 2 & Input 3
input #2와 input #3에도 동일 연산
## query와 key의 같은 dim이어야한다. 내적을 해야하기 때문에, 그러나 value의 dim은 output의 모양에 맞추면 된다.
[출처] towardsdatascience.com/illustrated-self-attention-2d627e33b20a
NLP에 활용
'👾 Deep Learning' 카테고리의 다른 글
| [Transformer] Positional Encoding (3) (0) | 2021.02.20 |
|---|---|
| [Transformer] Position-wise Feed-Forward Networks (2) (0) | 2021.02.20 |
| VAE(Variational Autoencoder) (3) MNIST (0) | 2021.02.18 |
| Tensorflow Initializer 초기화 종류 (0) | 2021.02.18 |
| VAE(Variational Autoencoder) (2) (0) | 2021.02.18 |