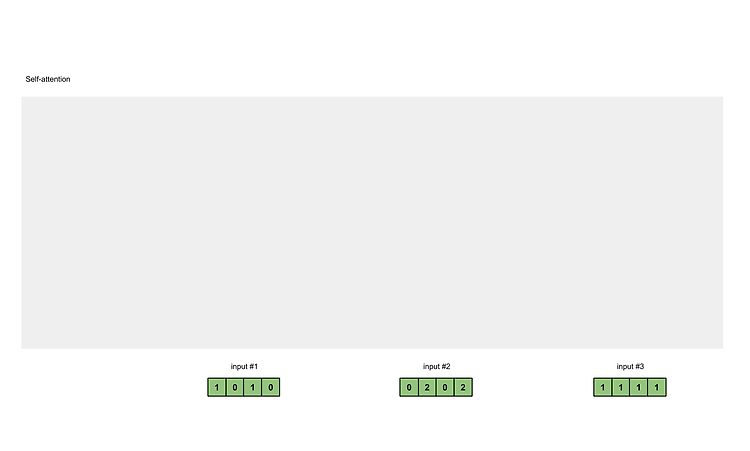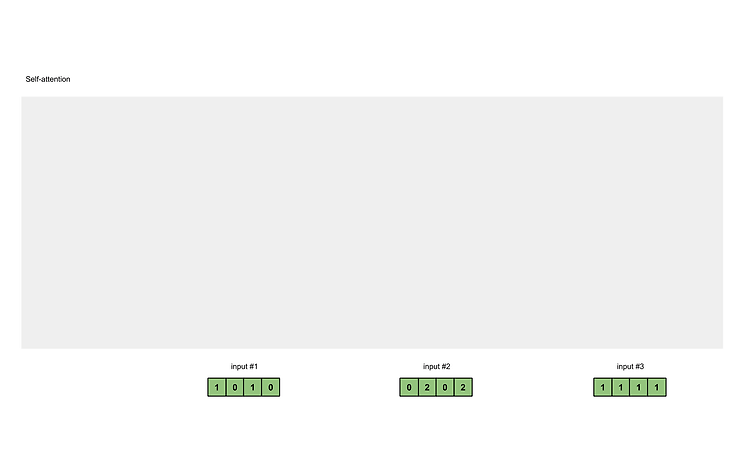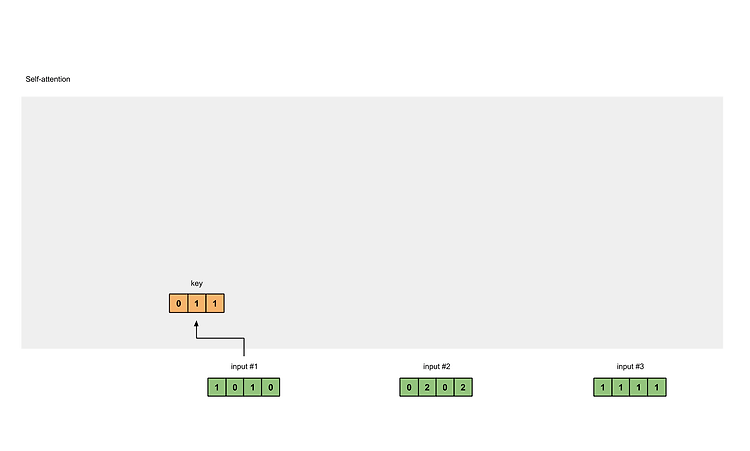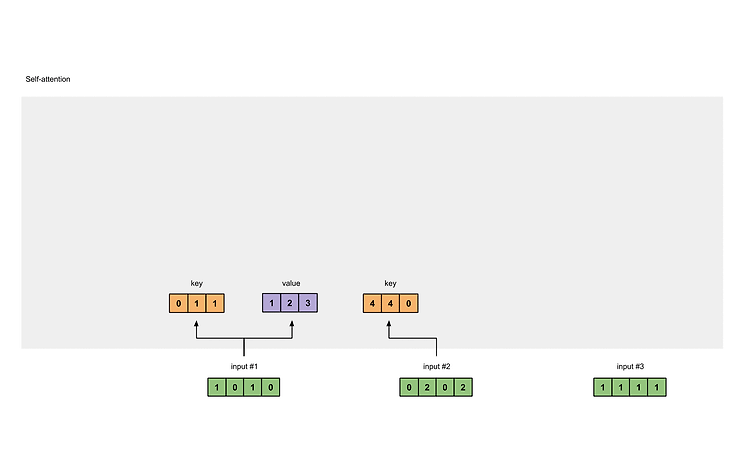
[Transformer] Position-wise Feed-Forward Networks (2)
·
👾 Deep Learning
nlp.seas.harvard.edu/2018/04/01/attention.html#position-wise-feed-forward-networks The Annotated Transformer The recent Transformer architecture from “Attention is All You Need” @ NIPS 2017 has been instantly impactful as a new method for machine translation. It also offers a new general architecture for many NLP tasks. The paper itself is very clearly writte nlp.seas.harvard.edu FFN(x)=max( 0, ..