
LDiA
대부분 주제 모형화나 의미 검색, 내용 기반 추천 엔진에서 가장 먼저 선택해야 할 기법은 LSA이다. 내용 기반 영화추천 알고리즘에 의하면 LSA가 LDiA 보다 약 두배로 정확하다. LSA에 깔린 수학은 간단하고 효율적이다.
NLP의 맥락에서 LDiA는 LSA처럼 하나의 주제 모형을 산출한다. LDiA는 이번 장 도입부에서 했던 사고 실험과 비슷한 방식으로 의미 벡터 공간(주제 벡터들의 공간)을 산출한다.
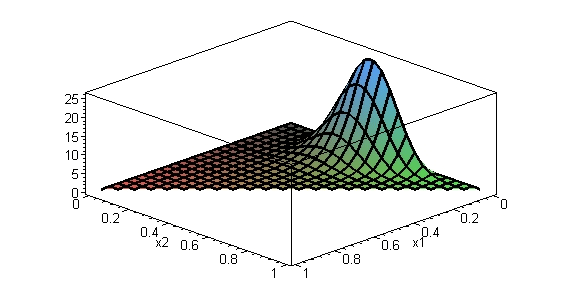
LDiA가 LSA와 다른 점은 단어 빈도들이 디리클레 분포를 따른다고 가정한다. LSA의 모형보다 LDiA의 디리클레 분포가 단어 빈도들의 분포를 잘 표현한다.
LDiA는 의미 벡터 공간을 산출한다. 사고 실험에서 특정 단어들이 같은 문서에 함께 등장하는 횟수에 기초해서 단어들을 주제들에 직접 배정했다. 한 문서에 대한 각 단어의 주제 점수들을 이용해 문서에 배정하는 접근 방식을 따르기 때문에 LSA보다 이해하기 쉽다.
LDiA는 각 문서를 임의의 개수의 주제들의 혼합으로 간주한다. 주제 개수는 LDiA 모형을 훈련하기 전에 개발자가 미리 정한다. LDiA는 또한 각 주제를 단어 출현 횟수들의 분포로 표현할 수 있다고 가정한다. LDiA는 또한 각 주제를 단어 출현 횟수들의 분포로 표현할 수 있다고 가정한다. (사전(prior) 확률분포)
LDiA의 기초
디리클레 분포에 기초한 분석 방법은 유전자 서열에서 집단 구조(population structure)를 추론하기 위해 고안했다.
LDiA에 기초한 문서 생성기는 다음 두가지를 나수로 결정한다.
- 문서를 위해 생성할 단어들의 수(포아송 분포)
- 문서를 위해 혼합할 주제들의 수(디리클레 분포)
문서의 단어 수를 결정하는 데 쓰이는 포아송 분포는 평균 문서 길이라는 매개 변수 하나로 정의된다. 주제 개수를 결정하는 데 쓰이는 디리클레 분포는 그보다 두개 많은 세개의 매개 변수로 정의된다. 두 수치를 결정한 후에는 문서에 사용할 모든 주제의 용어-주제 행렬만 있으면 간단한 절차로 새로운 문서들을 생성할 수 있다.
통계학적으로 분석하면 두 난수 발생 확률 분포의 매개 변수들을 구할 수 있음을 깨달았다. 1번 수치, 즉 문서의 단어 수를 결정하기 위해서는 해당 포아송 분포를 정해야한다. 이를 위한 평균은 말뭉치의 모든 문서에 대한 단어 모음들의 평균 단어 수(평균 n-gram 수)로 설정하면 된다.
포아송 분포 함수 $f(x) = \frac{e^{-\lambda}\lambda^x}{x!}$
평균($u$) = ${\lambda}$ = mean_document_len
total_corpus_len = 0
for document_text in sms.text:
total_corpus_len += len(casual_tokenize(document_text))
mean_document_len = total_corpus_len / len(sms)
round(mean_document_len,2) # 21.35이 통계량은 반드시 BOW들에서 직접계산해야한다. 불용어 필터링이나 기타 정규화를 적용한 문서들을 토큰화하고 벡터화한 단어들의 수를 세어야한다.(단어 사전의 길이)
2번 수치, 즉 주제의 수는 실제로 단어들을 주제들에 배정해 보기 전까지는 알수 없다. 이는 K-NN이나 K-means
clustering 군집화와 같은 군집화 알고리즘들처럼 먼저 k를 결정해야 다음 단계로 나아갈 수 있는 것과 비슷한 상황이다.
주제의 개수를 임의로 정하고 개선해 나가는 방법을 사용한다. 일단 주제 개수를 지정해 주면 LDiA는 각 주제에 대해 목적함수가 최적값이 되는 단어들의 혼합을 찾아낸다.
LDiA를 반복하면서 k를 조율하면 최적의 k에 도달할 수 있다. 이런 최적화 과정을 자동화할 수있다. LDiA 언어 모형의 품질을 평가하는 방법이 필요하다. LDiA의 결과가 말뭉치에 있는 어떤 부류 또는 회귀문제에 적용해서 그 결과와 정답의 오차를 측정하는 것이다. 이는 비용함수(cost function)를 평가하는 것에 해당한다. 정답으로 분류명(감정, 키워드, 주제)이 붙은 문서들로 LDiA 모형을 실행해서 오차를 측정하면 된다.
문자 메시지 말뭉치에 대한 LDiA 주제 모형
LDiA가 산출한 주제는 사람이 이해하기 좀 더 쉽낟. LSA가 떨어저 있는 단어들을 더 떨어뜨린다면 LDiA는 가깝게 생각하는 단어들을 더 가깝게 만든다.
LDiA는 공간을 비선형적인 방식으로 비틀고 일그러 뜨린다. 원래의 공간이 3차원이고 이를 2차원으로 투영하는 방법이 아닌한 시각화하기 어렵다.
# 메세지 스팸 문제에 대입
사용할 주제의 수는 16. 주제의 수를 낮게 유지하면 과대적합(overfitting)을 줄이는데 도움이 된다.
from sklearn.feature_extraction.text import CountVectorizer
from nltk.tokenize import casual_tokenize
import numpy as np
np.random.seed(42) #LDiA는 난수를 이용한다.
# 불용어 제거 + 토큰화된 BOW 단어들을 사용
counter = CountVectorizer(tokenizer=casual_tokenize)
bow_docs = pd.DataFrame(counter.fit_transform(raw_documents=sms.text).toarray(),index=index)
bow_docs.head()
# 0 1 2 3 4 5 ... 9226 9227 9228 9229 9230 9231
# sms0 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms1 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms2! 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms3 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms4 0 0 0 0 0 0 ... 0 0 0 0 0 0
column_nums, terms = zip(*sorted(zip(counter.vocabulary_.values(),counter.vocabulary_.keys())))
bow_docs.columns = terms
첫 문자 메시지 sms0읜 단어 모음
sms.loc['sms0'].text
# 'Go until jurong point, crazy.. Available only in bugis n great world la e buffet..
bow_docs.loc['sms0'][bow_docs.loc['sms0'] > 0].head()
# , 1
# .. 1
# 2
# amore 1
# available 1
# Name: sms0, dtype: int64
LDiA 적용 후 주제 벡터들을 산출
from sklearn.decomposition import LatentDirichletAllocation as LDiA
ldia = LDiA(n_components=16, learning_method='batch') # 주제 수 16
ldia = ldia.fit(bow_docs) # bow_docs.shape (4837, 9232)
ldia.components_.shape # (16, 9232)
9232개의 단어를 16개의 주제로 압축했다. 성분 확인(component)
가장 많이 사용된 문자는 !이고 LDiA에서 topic4에 가장 많은 점수를 할당했다.
ldia = ldia.fit(bow_docs) # bow_docs.shape (4837, 9232)
ldia.components_.shape # (16, 9232)
columns = ["topic{}".format(i) for i in range(1,17)]
components = pd.DataFrame(ldia.components_.T,index=terms,columns=columns)
components.round(2).head(3)
# topic1 topic2 topic3 topic4 ... topic13 topic14 topic15 topic16
# ! 184.03 15.00 72.22 394.95 ... 64.40 297.29 41.16 11.70
# " 0.68 4.22 2.41 0.06 ... 0.07 62.72 12.27 0.06
# # 0.06 0.06 0.06 0.06 ... 1.07 4.05 0.06 0.06
# [3 rows x 16 columns]
topic4는 다른 감정 표현보다 !에 많이 점수를 준것으로보아 강한 강조일 가능성이 크다.
components.topic4.sort_values(ascending=False)[:20]
# ! 394.952246
# . 218.049724
# to 119.533134
# u 118.857546
# call 111.948541
# £ 107.358914
# , 96.954384
# * 90.314783
# your 90.215961
# is 75.750037
# the 73.335877
# a 62.456249
# on 61.814983
# claim 57.013114
# from 56.541578
# prize 54.284250
# mobile 50.273584
# urgent 49.659121
# & 47.490745
# now 47.419239
# Name: topic4, dtype: float64
LSA와 다르게 직관적으로 판별할 수 있다.
문자 메시지를 스팸 또는 비스팸으로 분류하기 위해 LDiA 주제 벡터들을 계산한 다음 LDA(선형 판별 분석)에 적용한다.
0인 것이 많은 것은 잘 분류한 것이다. 0은 주제와 상관없다는 의미이다. LDiA 파이프라인을 기초해 사업상의 결정을 내릴 때 이는 중요한 장점이다.
ldia16_topic_vectors = ldia.transform(bow_docs)
ldia16_topic_vectors = pd.DataFrame(ldia16_topic_vectors,index = index, columns = columns)
ldia16_topic_vectors.round(2).head()
# topic1 topic2 topic3 topic4 ... topic13 topic14 topic15 topic16
# sms0 0.62 0.00 0.00 0.00 ... 0.00 0.00 0.00 NaN
# sms1 0.01 0.01 0.01 0.01 ... 0.01 0.01 0.01 NaN
# sms2! 0.00 0.00 0.00 0.00 ... 0.00 0.00 0.00 NaN
# sms3 0.00 0.00 0.00 0.09 ... 0.00 0.00 0.00 NaN
# sms4 0.00 0.33 0.00 0.00 ... 0.00 0.00 0.00 NaN
# [5 rows x 16 columns]
LDiA + LDA 스팸 분류기
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
X_train,X_test,y_train,y_test = train_test_split(ldia16_topic_vectors,sms.spam,test_size=0.5)
X_train['topic16'] = np.zeros(len(X_train['topic16'])).T # NaN 값 -> 0
lda = LDA(n_components=1)
lda = lda.fit(X_train,y_train)
sms['lda16_spam'] = lda.predict(ldia16_topic_vectors)
X_test['topic16'] = np.zeros(len(X_test['topic16'])).T # NaN 값 -> 0
y_test['topic16'] = np.zeros(len(y_test['topic16'])).T # NaN 값 -> 0
round(float(lda.score(X_test,y_test)),2) # 0.93 정확도
차원이 16->32일 때 LDiA 비교
ldia32 = LDiA(n_components=32,learning_method='batch')
ldia32 = ldia32.fit(bow_docs)
ldia32.components_.shape # (32, 9232)
ldia32_topic_vectors = ldia32.transform(bow_docs)
columns32 = ['topic{}'.format(i) for i in range(ldia32.n_components)]
ldia32_topic_vectors = pd.DataFrame(ldia32_topic_vectors, index=index,columns=columns32)
ldia32_topic_vectors.round(2).head()
# topic0 topic1 topic2 topic3 topic4 topic5 ... topic26 \
# sms0 0.0 0.0 0.0 0.24 0.0 0.00 ... 0.00
# sms1 0.0 0.0 0.0 0.00 0.0 0.00 ... 0.12
# sms2! 0.0 0.0 0.0 0.00 0.0 0.00 ... 0.00
# sms3 0.0 0.0 0.0 0.93 0.0 0.00 ... 0.00
# sms4 0.0 0.0 0.0 0.00 0.0 0.24 ... 0.00
# topic27 topic28 topic29 topic30 topic31
# sms0 0.0 0.0 0.00 0.00 0.0
# sms1 0.0 0.0 0.00 0.00 0.0
# sms2! 0.0 0.0 0.98 0.00 0.0
# sms3 0.0 0.0 0.00 0.00 0.0
# sms4 0.0 0.0 0.00 0.14 0.0
# [5 rows x 32 columns]0이 많은 것으로 보아 깔끔하게 분리되었다는 것을 알 수 있다.
정확도 측정
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
X_train,X_test,y_train,y_test = train_test_split(ldia32_topic_vectors,sms.spam,test_size=0.5)
lda = LDA(n_components=1)
lda = lda.fit(X_train,y_train)
sms['lda_32_spam'] = lda.predict(ldia32_topic_vectors)
X_train.shape # (2418, 32)
round(float(lda.score(X_train,y_train)),3) #0.927주제의 수를 늘려 좀 더 명확한 분리를 했다. 정확도가 아직까지 PCA + LDA를 넘지는 못했다.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| LSA 거리와 유사도 (0) | 2021.02.21 |
|---|---|
| [Transformer] Multi-Head Attention (1) (0) | 2021.02.20 |
| [Kaggle] 네이버 영화 리뷰 분류(2) (0) | 2021.02.17 |
| 챗 봇 만들기(1) (0) | 2021.02.13 |
| MaLSTM (0) | 2021.02.13 |
LDiA
대부분 주제 모형화나 의미 검색, 내용 기반 추천 엔진에서 가장 먼저 선택해야 할 기법은 LSA이다. 내용 기반 영화추천 알고리즘에 의하면 LSA가 LDiA 보다 약 두배로 정확하다. LSA에 깔린 수학은 간단하고 효율적이다.
NLP의 맥락에서 LDiA는 LSA처럼 하나의 주제 모형을 산출한다. LDiA는 이번 장 도입부에서 했던 사고 실험과 비슷한 방식으로 의미 벡터 공간(주제 벡터들의 공간)을 산출한다.
LDiA가 LSA와 다른 점은 단어 빈도들이 디리클레 분포를 따른다고 가정한다. LSA의 모형보다 LDiA의 디리클레 분포가 단어 빈도들의 분포를 잘 표현한다.
LDiA는 의미 벡터 공간을 산출한다. 사고 실험에서 특정 단어들이 같은 문서에 함께 등장하는 횟수에 기초해서 단어들을 주제들에 직접 배정했다. 한 문서에 대한 각 단어의 주제 점수들을 이용해 문서에 배정하는 접근 방식을 따르기 때문에 LSA보다 이해하기 쉽다.
LDiA는 각 문서를 임의의 개수의 주제들의 혼합으로 간주한다. 주제 개수는 LDiA 모형을 훈련하기 전에 개발자가 미리 정한다. LDiA는 또한 각 주제를 단어 출현 횟수들의 분포로 표현할 수 있다고 가정한다. LDiA는 또한 각 주제를 단어 출현 횟수들의 분포로 표현할 수 있다고 가정한다. (사전(prior) 확률분포)
LDiA의 기초
디리클레 분포에 기초한 분석 방법은 유전자 서열에서 집단 구조(population structure)를 추론하기 위해 고안했다.
LDiA에 기초한 문서 생성기는 다음 두가지를 나수로 결정한다.
- 문서를 위해 생성할 단어들의 수(포아송 분포)
- 문서를 위해 혼합할 주제들의 수(디리클레 분포)
문서의 단어 수를 결정하는 데 쓰이는 포아송 분포는 평균 문서 길이라는 매개 변수 하나로 정의된다. 주제 개수를 결정하는 데 쓰이는 디리클레 분포는 그보다 두개 많은 세개의 매개 변수로 정의된다. 두 수치를 결정한 후에는 문서에 사용할 모든 주제의 용어-주제 행렬만 있으면 간단한 절차로 새로운 문서들을 생성할 수 있다.
통계학적으로 분석하면 두 난수 발생 확률 분포의 매개 변수들을 구할 수 있음을 깨달았다. 1번 수치, 즉 문서의 단어 수를 결정하기 위해서는 해당 포아송 분포를 정해야한다. 이를 위한 평균은 말뭉치의 모든 문서에 대한 단어 모음들의 평균 단어 수(평균 n-gram 수)로 설정하면 된다.
포아송 분포 함수 $f(x) = \frac{e^{-\lambda}\lambda^x}{x!}$
평균($u$) = ${\lambda}$ = mean_document_len
total_corpus_len = 0
for document_text in sms.text:
total_corpus_len += len(casual_tokenize(document_text))
mean_document_len = total_corpus_len / len(sms)
round(mean_document_len,2) # 21.35이 통계량은 반드시 BOW들에서 직접계산해야한다. 불용어 필터링이나 기타 정규화를 적용한 문서들을 토큰화하고 벡터화한 단어들의 수를 세어야한다.(단어 사전의 길이)
2번 수치, 즉 주제의 수는 실제로 단어들을 주제들에 배정해 보기 전까지는 알수 없다. 이는 K-NN이나 K-means
clustering 군집화와 같은 군집화 알고리즘들처럼 먼저 k를 결정해야 다음 단계로 나아갈 수 있는 것과 비슷한 상황이다.
주제의 개수를 임의로 정하고 개선해 나가는 방법을 사용한다. 일단 주제 개수를 지정해 주면 LDiA는 각 주제에 대해 목적함수가 최적값이 되는 단어들의 혼합을 찾아낸다.
LDiA를 반복하면서 k를 조율하면 최적의 k에 도달할 수 있다. 이런 최적화 과정을 자동화할 수있다. LDiA 언어 모형의 품질을 평가하는 방법이 필요하다. LDiA의 결과가 말뭉치에 있는 어떤 부류 또는 회귀문제에 적용해서 그 결과와 정답의 오차를 측정하는 것이다. 이는 비용함수(cost function)를 평가하는 것에 해당한다. 정답으로 분류명(감정, 키워드, 주제)이 붙은 문서들로 LDiA 모형을 실행해서 오차를 측정하면 된다.
문자 메시지 말뭉치에 대한 LDiA 주제 모형
LDiA가 산출한 주제는 사람이 이해하기 좀 더 쉽낟. LSA가 떨어저 있는 단어들을 더 떨어뜨린다면 LDiA는 가깝게 생각하는 단어들을 더 가깝게 만든다.
LDiA는 공간을 비선형적인 방식으로 비틀고 일그러 뜨린다. 원래의 공간이 3차원이고 이를 2차원으로 투영하는 방법이 아닌한 시각화하기 어렵다.
# 메세지 스팸 문제에 대입
사용할 주제의 수는 16. 주제의 수를 낮게 유지하면 과대적합(overfitting)을 줄이는데 도움이 된다.
from sklearn.feature_extraction.text import CountVectorizer
from nltk.tokenize import casual_tokenize
import numpy as np
np.random.seed(42) #LDiA는 난수를 이용한다.
# 불용어 제거 + 토큰화된 BOW 단어들을 사용
counter = CountVectorizer(tokenizer=casual_tokenize)
bow_docs = pd.DataFrame(counter.fit_transform(raw_documents=sms.text).toarray(),index=index)
bow_docs.head()
# 0 1 2 3 4 5 ... 9226 9227 9228 9229 9230 9231
# sms0 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms1 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms2! 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms3 0 0 0 0 0 0 ... 0 0 0 0 0 0
# sms4 0 0 0 0 0 0 ... 0 0 0 0 0 0
column_nums, terms = zip(*sorted(zip(counter.vocabulary_.values(),counter.vocabulary_.keys())))
bow_docs.columns = terms
첫 문자 메시지 sms0읜 단어 모음
sms.loc['sms0'].text
# 'Go until jurong point, crazy.. Available only in bugis n great world la e buffet..
bow_docs.loc['sms0'][bow_docs.loc['sms0'] > 0].head()
# , 1
# .. 1
# 2
# amore 1
# available 1
# Name: sms0, dtype: int64
LDiA 적용 후 주제 벡터들을 산출
from sklearn.decomposition import LatentDirichletAllocation as LDiA
ldia = LDiA(n_components=16, learning_method='batch') # 주제 수 16
ldia = ldia.fit(bow_docs) # bow_docs.shape (4837, 9232)
ldia.components_.shape # (16, 9232)
9232개의 단어를 16개의 주제로 압축했다. 성분 확인(component)
가장 많이 사용된 문자는 !이고 LDiA에서 topic4에 가장 많은 점수를 할당했다.
ldia = ldia.fit(bow_docs) # bow_docs.shape (4837, 9232)
ldia.components_.shape # (16, 9232)
columns = ["topic{}".format(i) for i in range(1,17)]
components = pd.DataFrame(ldia.components_.T,index=terms,columns=columns)
components.round(2).head(3)
# topic1 topic2 topic3 topic4 ... topic13 topic14 topic15 topic16
# ! 184.03 15.00 72.22 394.95 ... 64.40 297.29 41.16 11.70
# " 0.68 4.22 2.41 0.06 ... 0.07 62.72 12.27 0.06
# # 0.06 0.06 0.06 0.06 ... 1.07 4.05 0.06 0.06
# [3 rows x 16 columns]
topic4는 다른 감정 표현보다 !에 많이 점수를 준것으로보아 강한 강조일 가능성이 크다.
components.topic4.sort_values(ascending=False)[:20]
# ! 394.952246
# . 218.049724
# to 119.533134
# u 118.857546
# call 111.948541
# £ 107.358914
# , 96.954384
# * 90.314783
# your 90.215961
# is 75.750037
# the 73.335877
# a 62.456249
# on 61.814983
# claim 57.013114
# from 56.541578
# prize 54.284250
# mobile 50.273584
# urgent 49.659121
# & 47.490745
# now 47.419239
# Name: topic4, dtype: float64LSA와 다르게 직관적으로 판별할 수 있다.
문자 메시지를 스팸 또는 비스팸으로 분류하기 위해 LDiA 주제 벡터들을 계산한 다음 LDA(선형 판별 분석)에 적용한다.
0인 것이 많은 것은 잘 분류한 것이다. 0은 주제와 상관없다는 의미이다. LDiA 파이프라인을 기초해 사업상의 결정을 내릴 때 이는 중요한 장점이다.
ldia16_topic_vectors = ldia.transform(bow_docs)
ldia16_topic_vectors = pd.DataFrame(ldia16_topic_vectors,index = index, columns = columns)
ldia16_topic_vectors.round(2).head()
# topic1 topic2 topic3 topic4 ... topic13 topic14 topic15 topic16
# sms0 0.62 0.00 0.00 0.00 ... 0.00 0.00 0.00 NaN
# sms1 0.01 0.01 0.01 0.01 ... 0.01 0.01 0.01 NaN
# sms2! 0.00 0.00 0.00 0.00 ... 0.00 0.00 0.00 NaN
# sms3 0.00 0.00 0.00 0.09 ... 0.00 0.00 0.00 NaN
# sms4 0.00 0.33 0.00 0.00 ... 0.00 0.00 0.00 NaN
# [5 rows x 16 columns]
LDiA + LDA 스팸 분류기
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
X_train,X_test,y_train,y_test = train_test_split(ldia16_topic_vectors,sms.spam,test_size=0.5)
X_train['topic16'] = np.zeros(len(X_train['topic16'])).T # NaN 값 -> 0
lda = LDA(n_components=1)
lda = lda.fit(X_train,y_train)
sms['lda16_spam'] = lda.predict(ldia16_topic_vectors)
X_test['topic16'] = np.zeros(len(X_test['topic16'])).T # NaN 값 -> 0
y_test['topic16'] = np.zeros(len(y_test['topic16'])).T # NaN 값 -> 0
round(float(lda.score(X_test,y_test)),2) # 0.93 정확도
차원이 16->32일 때 LDiA 비교
ldia32 = LDiA(n_components=32,learning_method='batch')
ldia32 = ldia32.fit(bow_docs)
ldia32.components_.shape # (32, 9232)
ldia32_topic_vectors = ldia32.transform(bow_docs)
columns32 = ['topic{}'.format(i) for i in range(ldia32.n_components)]
ldia32_topic_vectors = pd.DataFrame(ldia32_topic_vectors, index=index,columns=columns32)
ldia32_topic_vectors.round(2).head()
# topic0 topic1 topic2 topic3 topic4 topic5 ... topic26 \
# sms0 0.0 0.0 0.0 0.24 0.0 0.00 ... 0.00
# sms1 0.0 0.0 0.0 0.00 0.0 0.00 ... 0.12
# sms2! 0.0 0.0 0.0 0.00 0.0 0.00 ... 0.00
# sms3 0.0 0.0 0.0 0.93 0.0 0.00 ... 0.00
# sms4 0.0 0.0 0.0 0.00 0.0 0.24 ... 0.00
# topic27 topic28 topic29 topic30 topic31
# sms0 0.0 0.0 0.00 0.00 0.0
# sms1 0.0 0.0 0.00 0.00 0.0
# sms2! 0.0 0.0 0.98 0.00 0.0
# sms3 0.0 0.0 0.00 0.00 0.0
# sms4 0.0 0.0 0.00 0.14 0.0
# [5 rows x 32 columns]0이 많은 것으로 보아 깔끔하게 분리되었다는 것을 알 수 있다.
정확도 측정
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
X_train,X_test,y_train,y_test = train_test_split(ldia32_topic_vectors,sms.spam,test_size=0.5)
lda = LDA(n_components=1)
lda = lda.fit(X_train,y_train)
sms['lda_32_spam'] = lda.predict(ldia32_topic_vectors)
X_train.shape # (2418, 32)
round(float(lda.score(X_train,y_train)),3) #0.927주제의 수를 늘려 좀 더 명확한 분리를 했다. 정확도가 아직까지 PCA + LDA를 넘지는 못했다.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| LSA 거리와 유사도 (0) | 2021.02.21 |
|---|---|
| [Transformer] Multi-Head Attention (1) (0) | 2021.02.20 |
| [Kaggle] 네이버 영화 리뷰 분류(2) (0) | 2021.02.17 |
| 챗 봇 만들기(1) (0) | 2021.02.13 |
| MaLSTM (0) | 2021.02.13 |