
kaggle www.kaggle.com/c/quora-question-pairs/submissions
Quora 질문 답변 사이트에서
같은 질문에 대한 판별 문제 column
# ['id', 'qid1', 'qid2', 'question1', 'question2', 'is_duplicate']
Quora Question Pairs
Can you identify question pairs that have the same intent?
www.kaggle.com
CNN - 합성 신경망
In deep learning, a convolutional neural network (CNN, or ConvNet) is a class of deep neural networks, most commonly applied to analyzing visual imagery.[1] They are also known as shift invariant or space invariant artificial neural networks (SIANN), based on their shared-weights architecture and translation invariance characteristics.[2][3] They have applications in image and video recognition, recommender systems,[4] image classification, Image segmentation, medical image analysis, natural language processing,[5] brain-computer interfaces,[6] and financial time series.[7]
Convolutional neural network - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Artificial neural network In deep learning, a convolutional neural network (CNN, or ConvNet) is a class of deep neural networks, most commonly applied to analyzing visual imagery.[1] T
en.wikipedia.org
Process
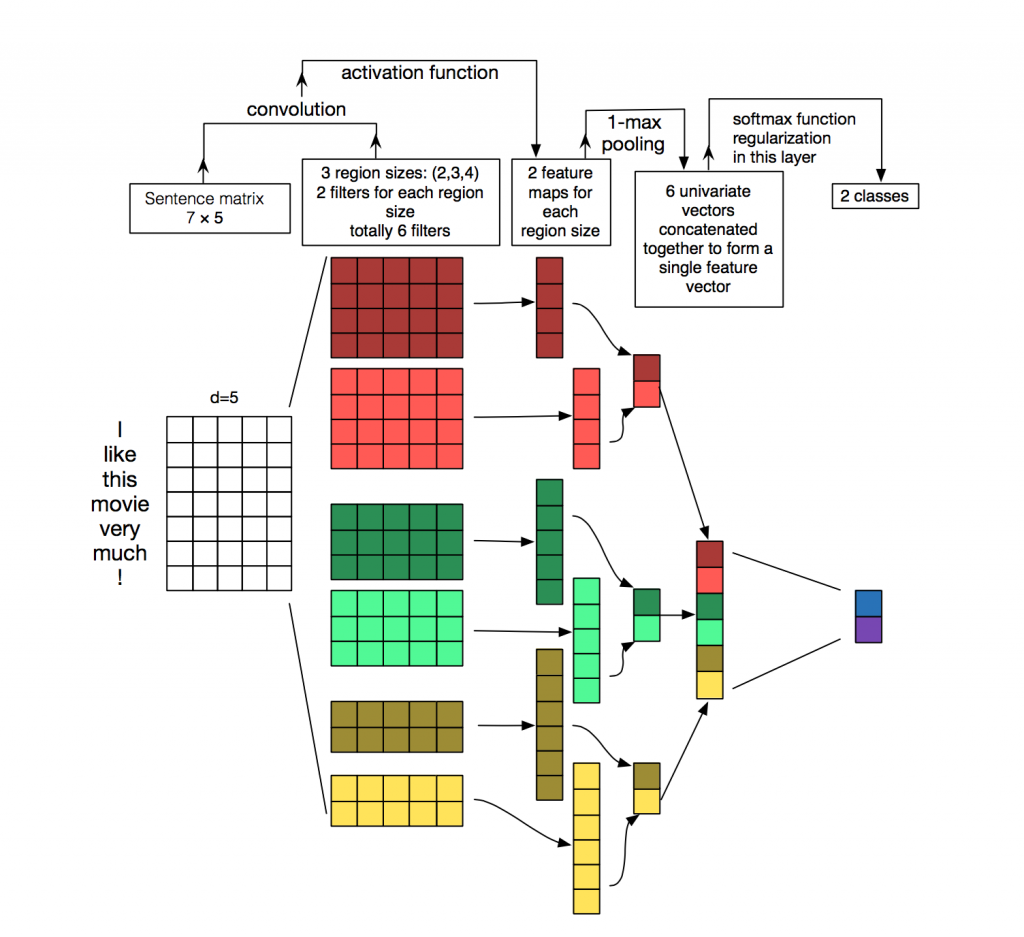
* Embedding
import tensorflow as tf
from tensorflow.keras import layers
class SentenceEmbedding(tf.keras.layers):
def __init__(self,**kwargs):
super(SentenceEmbedding,self).__init__()
self.conv = layers.Conv1D(kargs['conv_num_filters'],kargs['conv_window_size'],
activation=tf.keras.activations.relu,
padding='same')
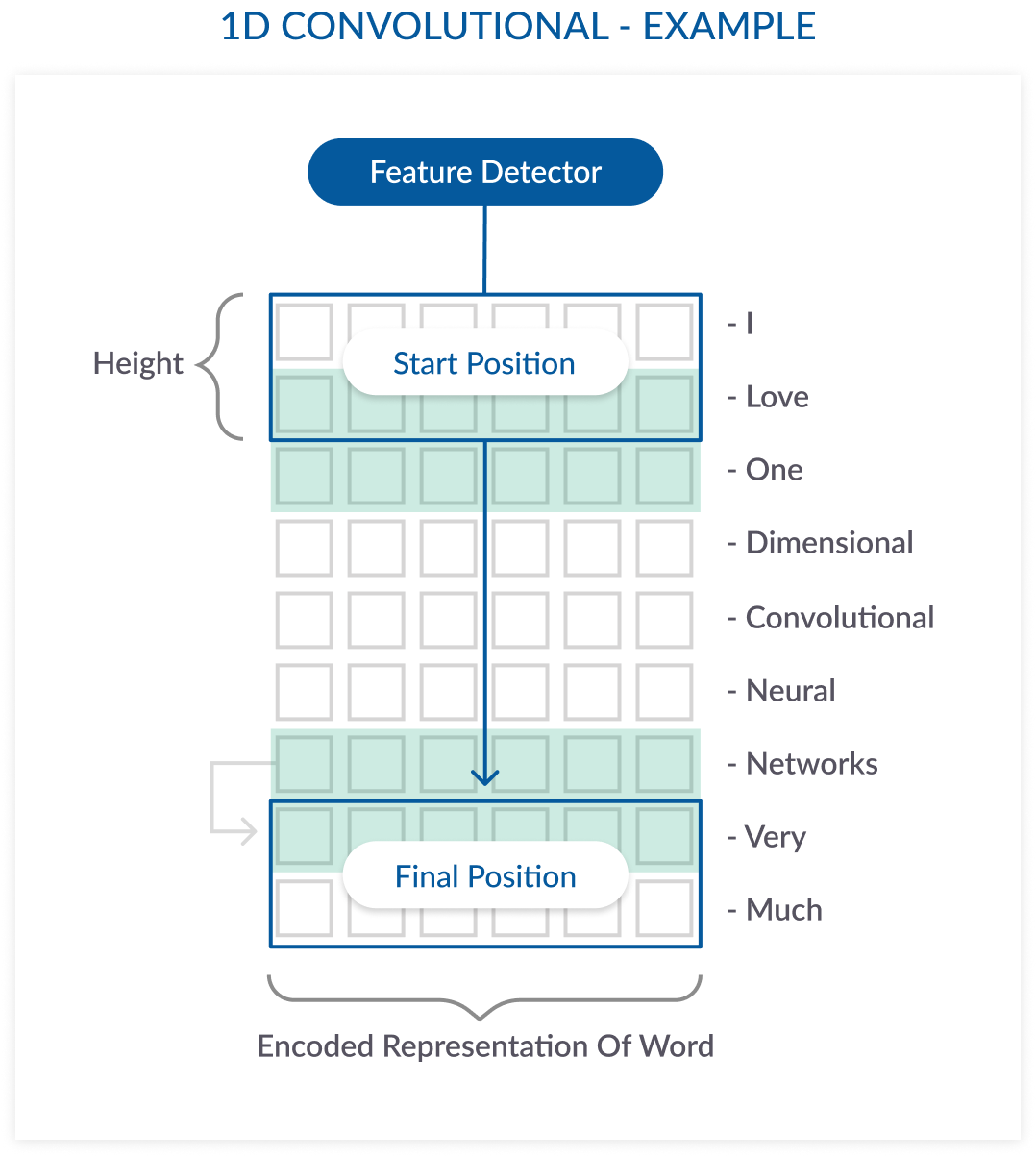
- filters: 가중치, (NLP-단어의 수,Image-이미지의 특징)
- kernel_size: filter 행렬의 크기
- activation: 목표 수치로 변환 해주는 함수
gelu(...): Applies the Gaussian error linear unit (GELU) activation function.
linear(...): Linear activation function (pass-through).
relu(...): Applies the rectified linear unit activation function.
sigmoid(...): Sigmoid activation function, sigmoid(x) = 1 / (1 + exp(-x)).
softmax(...): Softmax converts a real vector to a vector of categorical probabilities.
tanh(...): Hyperbolic tangent activation function. - padding:
same: input size와 output size가 같다.
valid: "패딩 없음"을 의미
casual: input_size보다 큰(팽창한) output_size
self.max_pool = layers.MaxPool1D(karg['max_pool_seq_len'],1)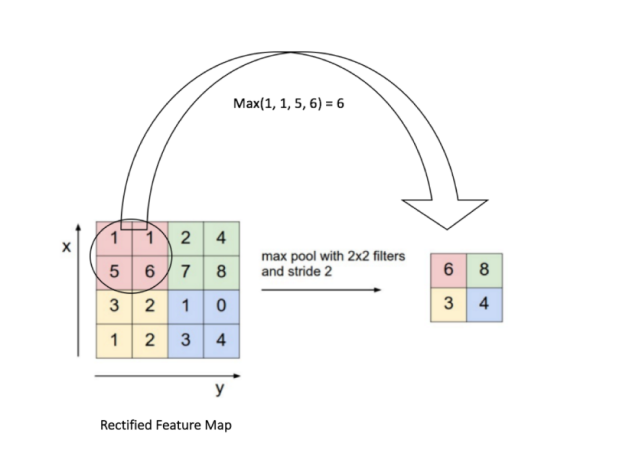
- pool_size:(int) maxpool 사이즈
- strides: pool 이동 간격
- padding: 사이즈 변경
max_pool input의 특징 추출
self.dense = layers.Dense(kargs['sent_embedding_dimension'],
activation=tf.keras.activation.relu)
units: output dimension
# activation으로 output의 크기를 정한다.
def call(self,x):
x = self.conv(x)
x = self.maxpool(x)
x = self.dense(x)
return tf.squeeze(x)# tf.squeeze(x) 불필요한 차원 제거
# SimilarityModel (본 모델)
class SentenceSimilarityModel(tf.keras.Model):
def __init__(self,**kargs):
super(SentenceSimilarityModel, self).__init__(name=kargs['model_name'])
self.word_embedding = layers.Embedding(kargs['vocab_size'],kargs['word_embedding_dimension'])
self.base_encoder = SentenceEmbedding(**kargs) # 문장1 임베딩
self.hypo_encoder = SentenceEmbedding(**kargs) # 문장2 임베딩
self.dense = layers.Dense(kargs['hidden_dimension'],
activation=tf.keras.activations.relu)
self.logit = layers.Dense(1,activation=tf.keras.activations.sigmoid)
self.dropout = layers.Dropout(kargs['dropout_rate'])
def call(self,x):
x1, x2 = x
b_x = self.word_embedding(x1)
h_x = self.word_embedding(x2)
b_x = self.dropout(b_x)
h_x = self.dropout(h_x)
b_x = self.base_encoder(b_x)
h_x = self.hypo_encoder(h_x)
e_x = tf.concat([b_x,h_x],-1)
e_x = self.dense(e_x)
e_x = self.dropout(e_x)
return self.logit(e_x) # 0~1로 변환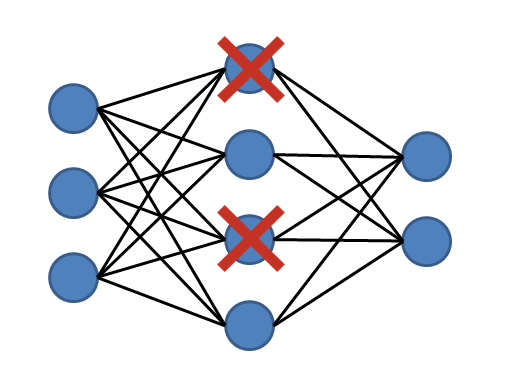
- tf.keras.layers.Dropout(
rate,
noise_shape=None,
seed=None,
**kwargs)
rate: (Float) 0~1 Fraction of the input units to drop.
Bayesian 신경망을 통해 해당 뉴런에 대한 학습이 무의미 할 경우 다른 뉴런에 학습을 중점으로 둔다.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| MaLSTM (0) | 2021.02.13 |
|---|---|
| [Kaggle] 네이버 영화 리뷰 분류(1) (0) | 2021.02.12 |
| PCA, SVD 잠재 의미 분석 (0) | 2021.02.11 |
| KoNLPy 종류 (0) | 2021.02.06 |
| SVD(singular value decomposition) VS SVM(support vector machine) (0) | 2021.02.05 |