
728x90
DFC615K
DFC615 Natural Language Processing Task 1
www.kaggle.com
NSMC 네이버 영화 리뷰에 달린 별점을 긍정/부정으로 변환한 binary-class 데이터 셋
# kaggle-nsmc
import os
import zipfile
def extractall(path,s_path,info=None,f_type=None):
file_list = os.listdir(path)
for file in file_list:
try:
if file.split('.')[1] in "zip":
zipRef = zipfile.ZipFile(path + file, 'r')
zipRef.extractall(s_path) # 압축 풀기
zipRef.close()
except IndexError:
continue
if info:
file_list=os.listdir(s_path)
for f in file_list:
if f_type in f and 'zip' not in f:
print(f.ljust(30) + str(round(os.path.getsize(s_path + f) / 1000000,2)) + 'MB')
FILE_PATH = 'C:/Users/admin/Desktop/nsmc/'
# Data 폴더 생성
DATA_FOLDER_NAME ='data/'
os.makedirs(FILE_PATH+DATA_FOLDER_NAME)
# 압축 해제 후 data folder에 저장
extractall(path=FILE_PATH,s_path=FILE_PATH+DATA_FOLDER_NAME,info=True,f_type='csv')
# ko_data.csv 0.62MB
file = os.listdir(FILE_PATH+DATA_FOLDER_NAME)
# 데이터 확인
for f in file:
print(f.ljust(30) + str(round(os.path.getsize(FILE_PATH + DATA_FOLDER_NAME + f) / 1000000,2)) + 'MB')
# ko_data.csv 0.62MB
# ratings.txt 19.52MB
# ratings_test.txt 4.89MB
# ratings_train.txt 14.63MB
Train_data 확인
import numpy as np
import pandas as pd
FILE = 'ratings_train.txt'
train_data = pd.read_csv(FILE_PATH+DATA_FOLDER_NAME+FILE,sep='\t',quoting=3)
train_data.columns # 'id', 'document', 'label'
train_data.head()
# id document label
# 0 9976970 아 더빙.. 진짜 짜증나네요 목소리 0
# 1 3819312 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 1
# 2 10265843 너무재밓었다그래서보는것을추천한다 0
# 3 9045019 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 0
# 4 6483659 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 ... 1
train_data.info()
# Data columns (total 3 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 id 150000 non-null int64
# 1 document 149995 non-null object
# 2 label 150000 non-null int64
# dtypes: int64(2), object(1)
# memory usage: 3.4+ MB
Train_data의 label 비율 확인
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.bar(train_data['label'].value_counts().index,train_data['label'].value_counts(),color=['red','blue'])
plt.title("Value Count")
plt.xlabel("Count 0 1 ")

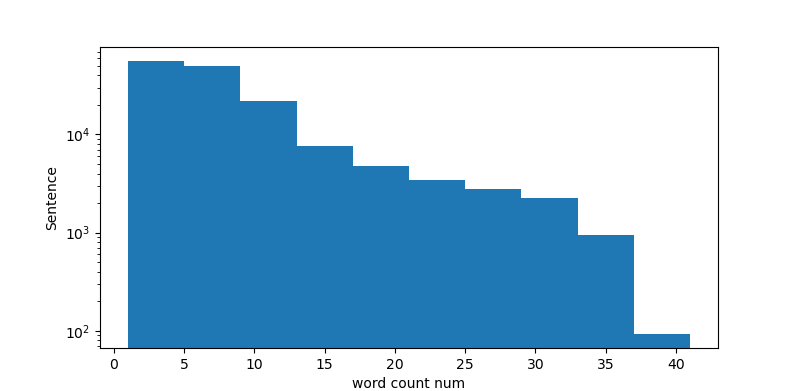
문장 당 단어 수 비율 확인
sentence_word = train_data['document'].astype(str).apply(lambda x: x.split())
sentence_word_len = sentence_word.apply(lambda x: len(x))
plt.figure(figsize=(10,5))
plt.hist(sentence_word_len,bins=10,log=True)
plt.xlabel('word count num')
plt.ylabel('Sentence')
* Preprocessing
# 특수 문자 제거
# preprocessing
# 특수 문자나 기호 제거
import re
rm = re.compile('[:;\'\"\[\]\(\)\.,@]')
rm_train = train_data['document'].astype(str).apply(lambda x: re.sub(rm,'',x))
# 불용어 제거
# 토큰화 + 불용어 제거
# https://bab2min.tistory.com/544 사용
import numpy as np
stopword_100 = pd.read_csv('한국어불용어100.txt',sep='\t',header=None)
stopword_list = stopword_100[0].to_numpy()
from konlpy.tag import Okt
okt=Okt()
okt_rm_train = rm_train.astype(str).apply(lambda x: str(okt.morphs(x,stem=True)))
# 0 [아, 더빙, 진짜, 짜증나다, 목소리]
# 1 [흠, 포스터, 보고, 초딩, 영화, 줄, 오버, 연기, 조차, 가볍다, 않다]
# 2 [너, 무재, 밓었, 다그, 래서, 보다, 추천, 한, 다]
# 3 [교도소, 이야기, 구먼, 솔직하다, 재미, 는, 없다, 평점, 조정]
# 4 [사이, 몬페, 그, 의, 익살스럽다, 연기, 가, 돋보이다, 영화, !, 스파이더...
# 5 [막, 걸음, 마, 떼다, 3, 세, 부터, 초등학교, 1, 학년, 생인, 8, 살...
# 6 [원작, 의, 긴장감, 을, 제대로, 살리다, 하다]
# 7 [별, 반개, 도, 아깝다, 욕, 나오다, 이응경, 길용우, 연, 기, 생활, 이,...
# 8 [액션, 이, 없다, 재미, 있다, 몇, 안되다, 영화]
# 9 [왜케, 평점, 이, 낮다, ?, 꽤, 볼, 만, 한, 데, 헐리우드, 식, 화려하...
# Name: document, dtype: object
len(okt_rm_train)
okt_rm_train = okt_rm_train.apply(lambda x: [str(word) for word in x])
rmstop_okt_rm_train = []
for word in okt_rm_train:
if word not in stopword_list:
rmstop_okt_rm_train.append(word)
else:
rmstop_okt_rm_train.append([])
반응형
'🗣️ Natural Language Processing' 카테고리의 다른 글
| 챗 봇 만들기(1) (0) | 2021.02.13 |
|---|---|
| MaLSTM (0) | 2021.02.13 |
| PCA, SVD 잠재 의미 분석 (0) | 2021.02.11 |
| CNN 텍스트 유사도 분석(Feat. Quora pairs) (0) | 2021.02.10 |
| KoNLPy 종류 (0) | 2021.02.06 |