
===
PCA
===
scikit-learn의 PCA모형을 문자 메시지들에 적용
import pandas as pd
from nlpia.data.loaders import get_data
sms = get_data("sms-spam")
sms.head()
index = ['sms{}{}'.format(i,'!'*j)
for (i,j) in zip(range(len(sms)), sms.spam)]
sms.index = index
# 각 메시지의 TF-IDF 벡터를 계산
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.tokenize.casual import casual_tokenize
tfidf = TfidfVectorizer(tokenizer=casual_tokenize)
tfidf_docs = tfidf.fit_transform(raw_documents=sms.text).toarray()
len(tfidf.vocabulary_)
tfidf_docs = pd.DataFrame(tfidf_docs)
tfidf_docs = tfidf_docs - tfidf_docs.mean() # 평균을 뻬서 문서의 벡터 표현들을 중심화한다.
tfidf_docs.shape
from sklearn.decomposition import PCA
pca = PCA(n_components=16)
pca.fit(tfidf_docs)
pca_topic_vectors = pca.transform(tfidf_docs)
columns = ['topic{}'.format(i) for i in range(pca.n_components)]
pca_topic_vectors = pd.DataFrame(pca_topic_vectors,columns=columns,index=index)
pca_topic_vectors.round(3).head(6)
# topic0 topic1 topic2 topic3 ... topic12 topic13 topic14 topic15
# sms0 0.201 0.003 0.037 0.011 ... 0.006 -0.034 -0.016 0.023
# sms1 0.404 -0.094 -0.078 0.051 ... 0.042 -0.019 0.047 -0.045
# sms2! -0.030 -0.048 0.090 -0.067 ... 0.020 -0.023 -0.040 0.046
# sms3 0.329 -0.033 -0.035 -0.016 ... 0.072 -0.038 0.017 -0.061
# sms4 0.002 0.031 0.038 0.034 ... 0.028 0.037 -0.086 -0.031
# sms5! -0.016 0.059 0.014 -0.006 ... -0.033 0.066 0.002 0.028
spam 분류 메시지 PCA 분석을 진행했다.
pca_topic_vectors는 각 주제에 단어가 얼마나 "담겨 있는지"를 보면 즉 그 주제에 대한 각 단어의 가중치를 보면 짐작할 수있다.
PCA 변환의 모든 차원에 단어들을 배정
tfidf.vocabulary_
# {'go': 3807,
# 'until': 8487,
# 'jurong': 4675,
# 'point': 6296,
# ',': 13,
# 'crazy': 2549,
# '..': 21,
# 'available': 1531,
# 'only': 5}어휘의 단어들을 빈도 순으로 정렬
columns_nums, terms = zip(*sorted(zip(tfidf.vocabulary_.values(),tfidf.vocabulary_.keys())))
terms[:5]
#terms[:5] ('!', '"', '#', '#150', '#5000')각 주제가 실제로 무엇에 관한 것인지 가중치를 봐야한다.
스팸에 해당 할 거같은 단어들을 추출해 보았다.
weights = pd.DataFrame(pca.components_,columns=terms,index=['topic{}'.format(i) for i in range(pca.n_components)])
pd.options.display.max_columns = 12
weights.head(4).round(3)
deals = weights['! ;) :) half off free crazy deal only $ 80 %'.split()].round(3)*100
deals
# ! ;) :) half off free crazy deal only $ 80 %
# topic0 -7.1 0.1 -0.5 -0.0 -0.4 -2.0 -0.0 -0.1 -2.2 0.3 -0.0 -0.0
# topic1 6.3 0.0 7.4 0.1 0.4 -2.3 -0.2 -0.1 -3.8 -0.1 -0.0 -0.2
# topic2 7.1 0.2 -0.1 0.0 0.3 4.4 0.1 -0.1 0.7 0.0 0.0 0.1
# topic3 -5.9 -0.3 -7.1 0.2 0.3 -0.2 0.0 0.1 -2.3 0.1 -0.1 -0.3
# topic4 38.1 -0.1 -12.5 -0.1 -0.2 9.9 0.1 -0.2 3.0 0.3 0.1 -0.1
# topic5 -26.5 0.1 -1.6 -0.3 -0.7 -1.3 -0.6 -0.2 -1.8 -0.9 0.0 0.0
# topic6 -10.9 -0.5 19.9 -0.4 -0.9 -0.6 -0.2 -0.1 -1.4 -0.0 -0.0 -0.1
# topic7 16.1 0.1 -18.0 0.8 0.8 -2.9 0.0 0.1 -1.8 -0.3 0.0 -0.1
# topic8 34.2 0.1 5.0 -0.5 -0.5 -0.3 -0.4 -0.4 3.4 -0.6 -0.0 -0.2
# topic9 7.2 -0.3 16.6 1.4 -0.9 6.2 -0.5 -0.4 3.1 -0.4 -0.0 0.0
# topic10 -32.3 -0.2 -10.0 0.1 0.1 12.8 0.1 -0.0 0.5 -0.0 -0.0 -0.2
# topic11 21.5 0.4 31.8 0.4 1.5 -4.1 0.0 0.1 -0.1 -0.4 -0.0 -0.3
# topic12 -23.5 -0.2 39.2 -0.3 0.1 -4.0 -0.5 0.1 3.6 0.3 -0.0 0.3
# topic13 11.8 -0.3 29.1 -0.4 0.5 4.9 0.4 0.1 -1.7 -0.4 0.0 -0.2
# topic14 -0.5 -0.1 13.9 -0.1 -1.0 5.1 0.1 -0.1 3.9 -0.0 0.0 -0.5
# topic15 6.6 -0.5 1.0 -0.5 -1.4 -5.1 -0.8 0.5 0.3 -0.5 0.1 0.0가중치를 합해서 주제별 가장 높은 수치를 확인
deals와 유사한 주제는 4, 8, 9임을 알 수 있다. 0, 3, 5 는 deals와 상반된 의미임을 가중치를 통해 알 수 있다.
deals.T.sum()
# topic0 -11.9
# topic1 7.5
# topic2 12.7
# topic3 -15.5
# topic4 38.3
# topic5 -33.8
# topic6 4.8
# topic7 -5.2
# topic8 39.8
# topic9 32.0
# topic10 -29.1
# topic11 50.8
# topic12 15.1
# topic13 43.8
# topic14 20.7
# topic15 -0.3
# dtype: float64이 처럼 차원이 의미하는 것을 아는 것은 어렵다. LSA의 단점 중 하나이다. LSA는 단어들 사이의 일차 관계만 허용한다.또한 사람이 의미를 파악하기 어려운 단어 조합들도 많이 나온다. PCA는 단어 빈도들의 분산이 가장 커지는 조합을 찾을뿐이다. 따라서 사람이 보기에는 전혀 다른 주제의 여러 단어가 하나의 차원으로 합쳐지는 일이 발생한다.
===
SVD
===
scikit-learn의 TruncatedSVD 모형은 LSA에 대한 좀 더 직접적인 접근 방식이다. 이 모형에서는 scikit-learn PCA 모형이 숨겼던 세부 사항을 어느 정도 직접 살펴 볼 수 있다. 자료 모형이 클 경우에는 TruncatedSVD 대신 PCA를 사용하는 것이 더 빠르다. Truncated의 SVD부분은 TF-IDF 행렬을 세 개의 행렬로 분할한다. TF-IDF 행렬에 관한 정보가 적은 차원들은 폐기한다. 폐기된 차원들은 말뭉치의 문서들 전체에서 그 분산이 작은 '주제'에 해당한다. 이런 차원은 의미에 큰 작용하지 않는다. 이런 주제들은 문서에서 영양가 없는 단어들이다. 불용어, 조사 등이 해당된다.
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=16,n_iter=100)
svd_topic_vectors = svd.fit_transform(tfidf_docs.values)
svd_topic_vectors = pd.DataFrame(svd_topic_vectors,columns=columns,index=index)
svd_topic_vectors.round(3).head(3)
# topic0 topic1 topic2 topic3 topic4 topic5 ... topic10 topic11 topic12 topic13 topic14 topic15
# sms0 0.201 0.003 0.037 0.011 -0.019 -0.053 ... 0.007 -0.007 0.002 -0.036 -0.014 0.037
# sms1 0.404 -0.094 -0.078 0.051 0.100 0.047 ... -0.004 0.036 0.043 -0.021 0.051 -0.042
# sms2! -0.030 -0.048 0.090 -0.067 0.091 -0.043 ... 0.125 0.023 0.026 -0.020 -0.042 0.052# TruncatedSVD가 산출한 주제 벡터들이 PCA모형이 산출한 것들과 정확히 일치하다. n_iter를 기본보다 훨씬 크게 잡았고 각 단어의 TF-IDF 빈도들을 0에 대해 중심화한 덕분이다.
PCA의 경우처럼 각 주제의 의미를 알려면 단어 가중치들을 살펴봐야한다. sms! 느낌표가 스팸 메일 구분자이다. 해당 열의 점수가 가장 높은 것을 보면 topic11에 대한 pca차원이 스팸 메일을 구분 짓는 단어의 주제일 확률이 크다. 이 주제를 비교하면 스팸인지 아닌 지를 알 수 있다.
* 스팸 분류에 대한 LSA의 정확도
import numpy as np
svd_topic_vectors = (svd_topic_vectors.T/np.linalg.norm(svd_topic_vectors,axis=1)).T
svd_topic_vectors.iloc[:10].dot(svd_topic_vectors.iloc[:10].T).round(1)
# sms0 sms1 sms2! sms3 sms4 sms5! sms6 sms7 sms8! sms9!
# sms0 1.0 0.6 -0.1 0.6 -0.0 -0.3 -0.3 -0.1 -0.3 -0.3
# sms1 0.6 1.0 -0.2 0.8 -0.2 0.0 -0.2 -0.2 -0.1 -0.1
# sms2! -0.1 -0.2 1.0 -0.2 0.1 0.4 0.0 0.3 0.5 0.4
# sms3 0.6 0.8 -0.2 1.0 -0.2 -0.3 -0.1 -0.3 -0.2 -0.1
# sms4 -0.0 -0.2 0.1 -0.2 1.0 0.2 0.0 0.1 -0.4 -0.2
# sms5! -0.3 0.0 0.4 -0.3 0.2 1.0 -0.1 0.1 0.3 0.4
# sms6 -0.3 -0.2 0.0 -0.1 0.0 -0.1 1.0 0.1 -0.2 -0.2
# sms7 -0.1 -0.2 0.3 -0.3 0.1 0.1 0.1 1.0 0.1 0.4
# sms8! -0.3 -0.1 0.5 -0.2 -0.4 0.3 -0.2 0.1 1.0 0.3
# sms9! -0.3 -0.1 0.4 -0.1 -0.2 0.4 -0.2 0.4 0.3 1.0 svd_topic_vectors의 코사인 유사도를 보면 sms0인 정상 메일을 보면 sms 2 5 6 8 9와 거리가 먼 것으로 스팸 메일과 다르다는 것을 알 수 있다.
* Cosine similarity : 주제 벡터와 해당 벡터와의 관계를 벡터에서 스칼라 값으로 알려준다.
Heatmap
svd_topic_vectors_heatmap = svd_topic_vectors.iloc[:10].dot(svd_topic_vectors.iloc[:10].T).round(1)
import seaborn as sns
sns.heatmap(svd_topic_vectors_heatmap,cmap='YlGnBu')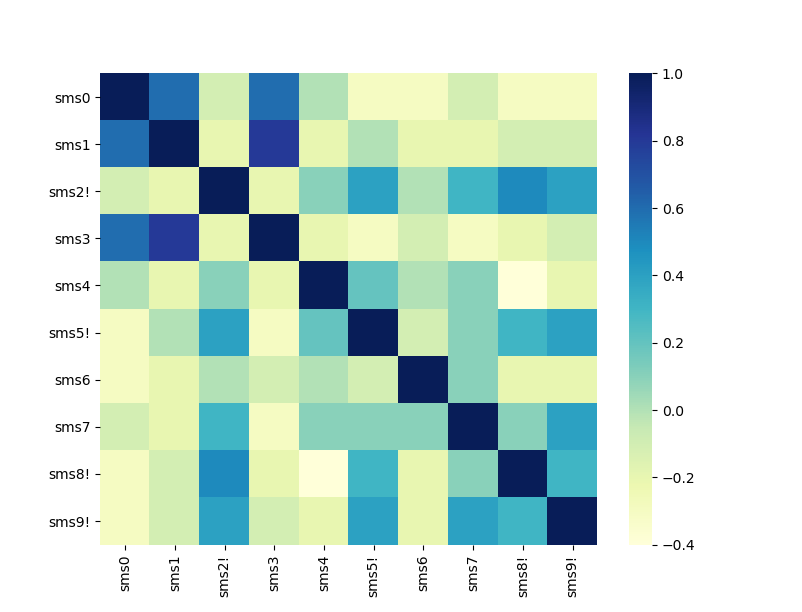
다만 위의 유사도를 보면 알 수 있듯이 스팸성있는 메일을 하나를 기준으로 다른 스팸을 분류하기에는 오류가 있다. ex) sms9! - sms7
이러한 방식으로 분류 기준을 기계가 학습을 하게 한다면 스팸과 비스팸 메일의 경계선을 알 수 있을 것이다.
절단된 SVD를 사용할 때는 주제 벡터들을 계산하기에 앞서 특잇값들을 폐기할 필요가 있다.
- 방법 1: TF-IDF 벡터들을 해당 길이(L2-norm)으로 정규화
- 방법 2: 각 TF-IDF 용어 빈도에서 평균 빈도를 빼서 빈도들을 중심화
SVD는 TF-IDF 벡터들을 변환하는 행렬의 회전 성분들만 처리하게 된다. 이처럼 고윳값(eigenvalue)들을 무시하는 것은 주제 벡터 공간을 경계 짓는 초입방체(hypercube)를 "바로 세우는(square up)" 것에 해당한다. scikit-learn의 PCA구현은 자료를 '중심화','백화'함으로써 정규화를 수행한다.
############
LSA와 LSD 개선
############
의미 분석과 차원 축소에 특잇값 분해가 유용하다는 점이 밝혀지면서 연구자들은 특잇값 분해 알고리즘을 더욱 확장하고 개선했다.
의미 분석 파이프라인 개선안
- 이차 판별 분석(quadratic discriminant analysis, QDA)
- 무작위 투영(random projection)
- 비음수 행렬 인수분해(nonnegative matrix factorization, NFM; 또는 음수 미포함 행렬 분해)
QDA는 LDA의 한 대안이다. QDA는 선형 변환이 아니라 이차 다항식 변환 행렬을 산출한다. 이 변환 행렬이 정의하는 벡터 공간을 이용해서 벡터들을 여러 부류로 나눈다.
무작위 투영은 SVD와 비슷한 행렬 분해 및 변환 접근 방식이지만, 알고리즘이 확률적이기 때문에 실행할 때마다 다른 해답이 나온다. 그렇지만 이런 확률적 성격 덕분에 알고리즘을 여러 대의 컴퓨터에서 병렬로 수행하기가 쉽다. 그리고 이 알고리즘을 여러 번 실행하면 SVD의 결과보다 나은 결과가 나오기도 한다. 그러나 NLP문제에는 무작위 투영을 거의 안쓴다. 그래서 패키지가 적어 구현을 사용자가 직접해야한다.
대부분의 경우 이런 개선안들보다는 효과가 이미 검증된 SVD알고리즘에 기초한 LSA를 사용하는 것이 낫다.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| MaLSTM (0) | 2021.02.13 |
|---|---|
| [Kaggle] 네이버 영화 리뷰 분류(1) (0) | 2021.02.12 |
| CNN 텍스트 유사도 분석(Feat. Quora pairs) (0) | 2021.02.10 |
| KoNLPy 종류 (0) | 2021.02.06 |
| SVD(singular value decomposition) VS SVM(support vector machine) (0) | 2021.02.05 |