
728x90
##############
MaLSTM 모델
##############
LSTM계열을 활용해 문장의 유사도를 구한다. MaLSTM 모델은 2016년 MIT에서 조나스 뮐러(Jonas Mueller)의 논문에서 처음 소개 되었다. 문자의 Sequence 형태로 학습 시키고 기존 RNN보다 장기적인 학습에 효과적인 성늘을 보여줬다.
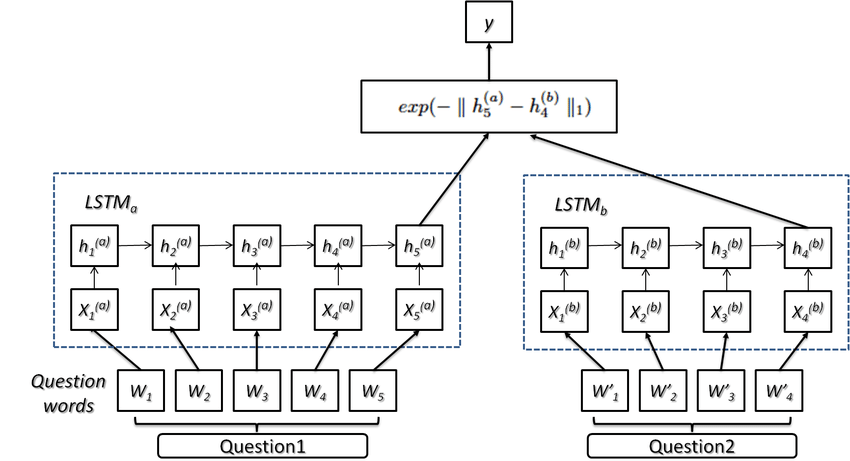
MaLSTM이란 맨하탄 거리(Manhattan Distance) + LSTM의 줄임말이다. 코사인 유사인 유사도를 대신해 맨하탄 거리(L1)을 이용한다.
LSTM의 마지막 스텝인 $LSTM_a$의 $h_5^{a}$ 값과 $LSTM_b$의 $h_4^{b}$ 값이 은닉 상태 벡터로 사용된다. 이 값은 문장의 모든 단어에 대한 정보가 반영된 값으로 전체 문장을 대표하는 벡터가 된다. 이렇게 뽑은 두 벡터에 대해 맨하탄 거리를 계산해서 두 문장 사이의 유사도를 측정한다. 이 유사도를 실제 라벨과 비교하는 학습 방식이다.
# 모델
# 모델 구현
import tensorflow as tf
from tensorflow.keras import layers
class Model(tf.keras.Model):
def __init__(self,**kargs):
super(Model,self).__init__(name=model_name)
self.embedding = layers.Embedding(input_dim=kargs['vocab_size'],
output_dim=kargs['embedding_dimension'])
self.lstm = layers.LSTM(units=kargs['lstm_dimension'])
def call(self,x):
x1, x2 = x
x1 = self.embedding(x1)
x2 = self.embedding(x2)
x1 = self.lstm(x1)
x2 = self.lstm(x2)
x = tf.exp(-tf.reduce_sum(tf.abs(x1-x2),axis=1))
return x
반응형
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [Kaggle] 네이버 영화 리뷰 분류(2) (0) | 2021.02.17 |
|---|---|
| 챗 봇 만들기(1) (0) | 2021.02.13 |
| [Kaggle] 네이버 영화 리뷰 분류(1) (0) | 2021.02.12 |
| PCA, SVD 잠재 의미 분석 (0) | 2021.02.11 |
| CNN 텍스트 유사도 분석(Feat. Quora pairs) (0) | 2021.02.10 |