
Conditional VAE (조건부 VAE)
조건부VAE(Conditional VAE)는 잠재 변수뿐만 아니라 레이블도 디코더에 입력하여 레이블을 지정하는 형태로 데이터를 생성한다. 필기체 숫자 이미지별로 가로와 세로의 잠재 변수 2개를 변화시키며 같은 숫자라도 필기체 숫자 이미지가 바뀌는 것을 알 수 있다.
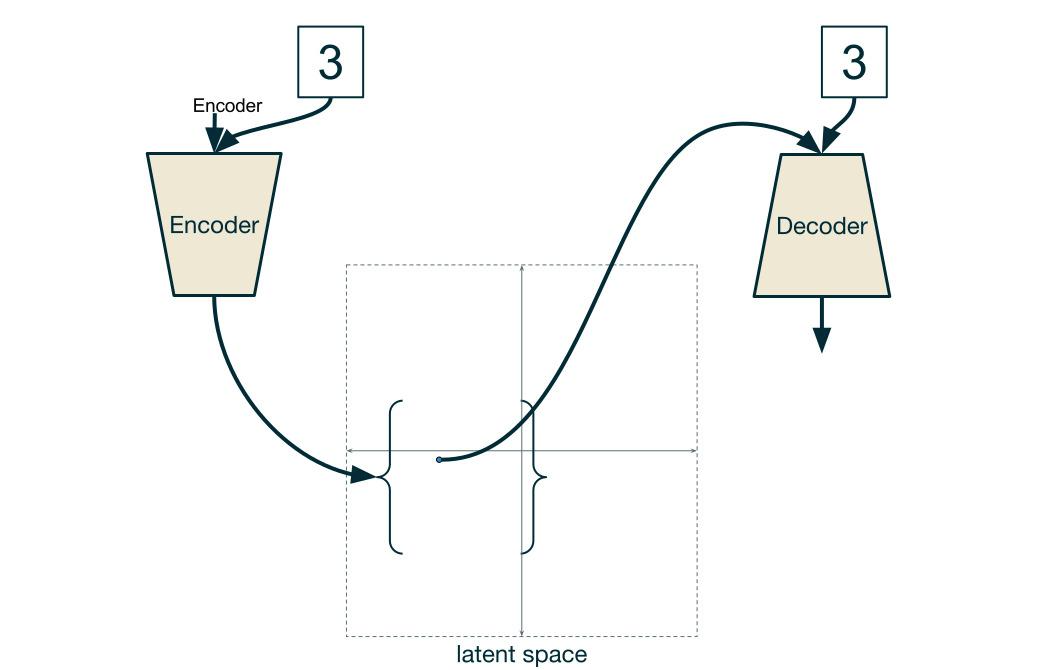
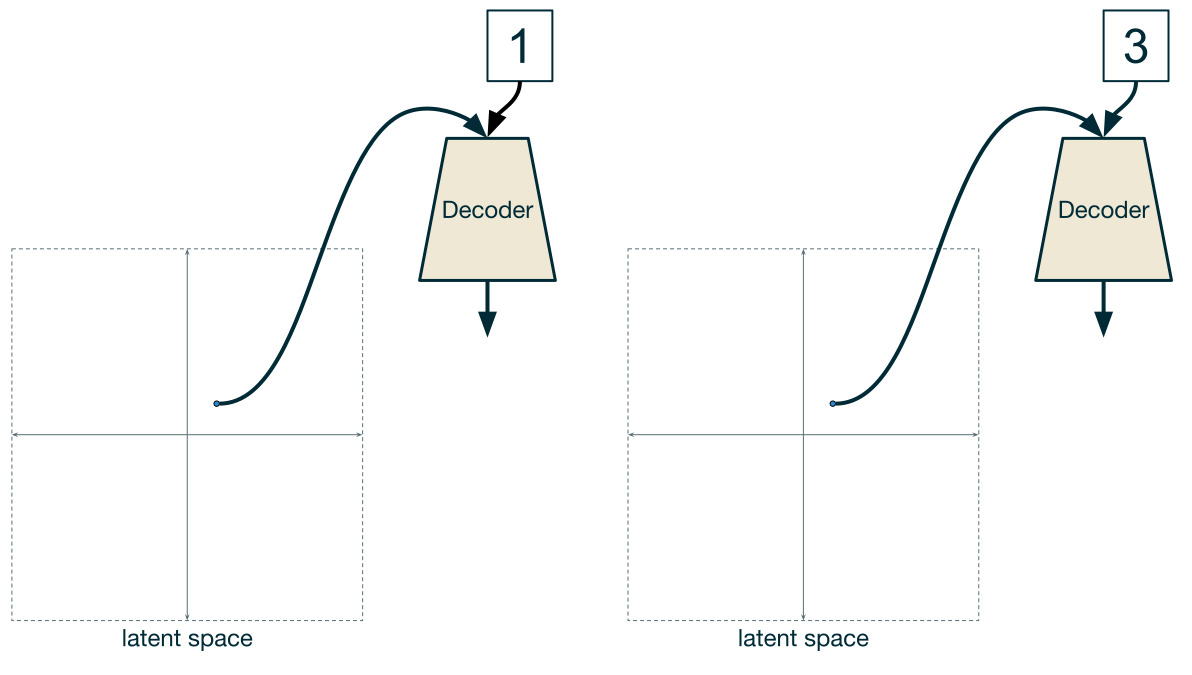

VAE는 보통 비지도학습이지만 지도학습 요소를 추가해 비지도 학습을 실행하면 복원할 데이터를 지정할 수 있다.
β-VAE
β-VAE는 이미지의 'disentanglement', 얽힌 것을 푸는 것이 특징이다. 이미지의 특징을 잠재 공간에서 분리하는 응용 기술이다. 예를 들어 얼굴 이미지는 첫 번쨰 잠재 변수에서 눈의 모양, 두 번째 잠재 변수에서 얼굴 방향의 특징을 담는다. 잠재 변수로 눈의 모양을 조정하고 두 번째 잠재 변수로 얼굴의 방향을 조정할 수 있다.

첫번째 열의 사진은 얼굴의 방향이 바뀌게 조정되어 가고있다.
두번째 열의 사진은 감정에 대한 표정이 바뀌게 조정되어 가고있다.
세번째 열의 사진은 머리 스타일이 바뀌게 조정되어 가고있다.
VAE는 표정과 얼굴의 방향이 모두 변화 한다. β-VAE는 얼굴 뱡향과 표정 이외에는 변화하는 요소가 없다. 이처럼
β-VAE는 잠재 변수를 사용해 이미지 등의 특징을 요소 기준으로 나눌 수 있는 기술이다.
VQ-VAE
VAE는 잠재 변수가 데이터의 특징을 정확하게 파악하지 못하는 '사후 붕괴(posterior collapse)'라는 현상으로 인해, 생성된 이미지가 흐릿한 문제가 있었다. 이 문제를 해결한 것이 '벡터 양자화된 변이형 오토인코더(Vector Quantised-VAE)' VQ-VAE 이다. 잠재 변수를 이산 값 즉 0,1,2 등 연속되지 않은 값으로 변환한다. 이는 이미지를 인코더에 입력하고 출력인 잠재 변수의 벡터를 코드북에 mapping해 구현한다.
VQ-VAE-2
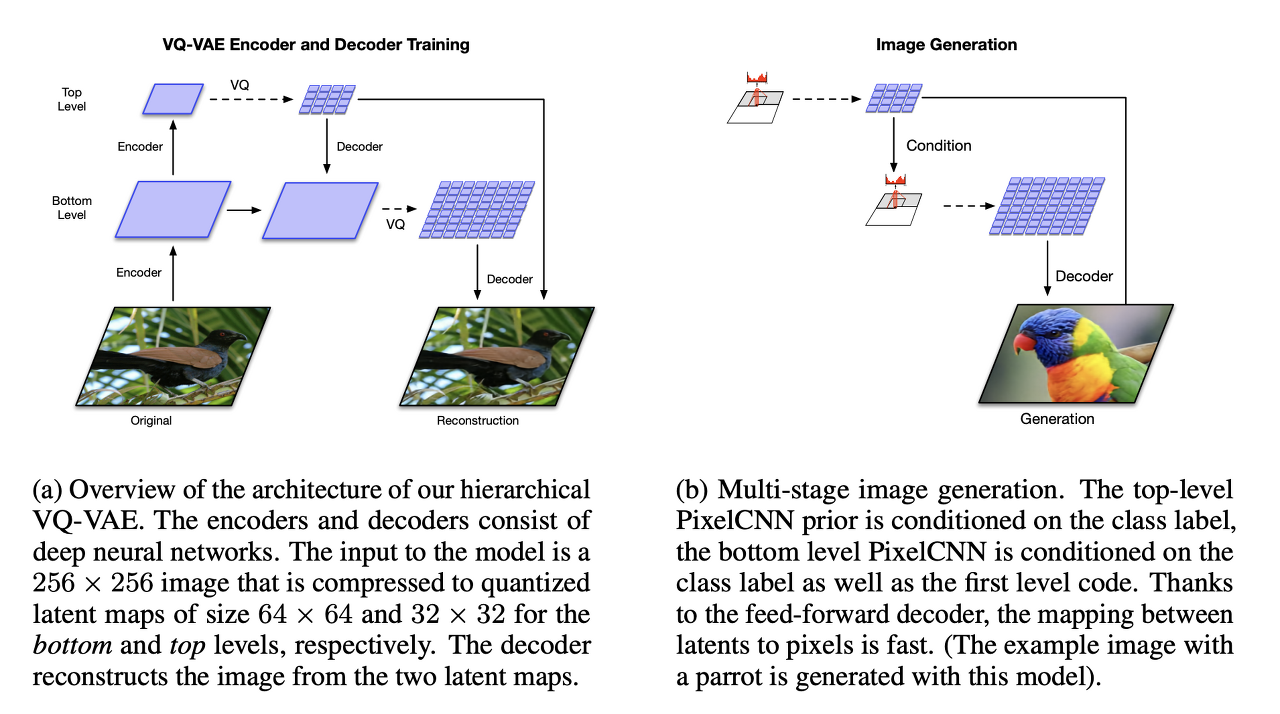
VQ-VAE-2는 VQ-VAE를 계층 구조로 만들어 더 높은 해상도의 이미지를 생성할 수 있게 만든 기술이다. 이 잠재 표현은 원래 이미지보다 훨씬 작지마느 디코더에 입력하면 더 선명하고 사실적인 이미지를 재구현 가능하다.
'👾 Deep Learning' 카테고리의 다른 글
| 파이썬의 뉴런 (0) | 2021.02.24 |
|---|---|
| [Transformer] Model 정리 (0) | 2021.02.23 |
| [Transformer] Positional Encoding (3) (0) | 2021.02.20 |
| [Transformer] Position-wise Feed-Forward Networks (2) (0) | 2021.02.20 |
| [Transformer] Self-Attension 셀프 어텐션 (0) (0) | 2021.02.19 |
Conditional VAE (조건부 VAE)
조건부VAE(Conditional VAE)는 잠재 변수뿐만 아니라 레이블도 디코더에 입력하여 레이블을 지정하는 형태로 데이터를 생성한다. 필기체 숫자 이미지별로 가로와 세로의 잠재 변수 2개를 변화시키며 같은 숫자라도 필기체 숫자 이미지가 바뀌는 것을 알 수 있다.
VAE는 보통 비지도학습이지만 지도학습 요소를 추가해 비지도 학습을 실행하면 복원할 데이터를 지정할 수 있다.
β-VAE
β-VAE는 이미지의 'disentanglement', 얽힌 것을 푸는 것이 특징이다. 이미지의 특징을 잠재 공간에서 분리하는 응용 기술이다. 예를 들어 얼굴 이미지는 첫 번쨰 잠재 변수에서 눈의 모양, 두 번째 잠재 변수에서 얼굴 방향의 특징을 담는다. 잠재 변수로 눈의 모양을 조정하고 두 번째 잠재 변수로 얼굴의 방향을 조정할 수 있다.
첫번째 열의 사진은 얼굴의 방향이 바뀌게 조정되어 가고있다.
두번째 열의 사진은 감정에 대한 표정이 바뀌게 조정되어 가고있다.
세번째 열의 사진은 머리 스타일이 바뀌게 조정되어 가고있다.
VAE는 표정과 얼굴의 방향이 모두 변화 한다. β-VAE는 얼굴 뱡향과 표정 이외에는 변화하는 요소가 없다. 이처럼
β-VAE는 잠재 변수를 사용해 이미지 등의 특징을 요소 기준으로 나눌 수 있는 기술이다.
VQ-VAE
VAE는 잠재 변수가 데이터의 특징을 정확하게 파악하지 못하는 '사후 붕괴(posterior collapse)'라는 현상으로 인해, 생성된 이미지가 흐릿한 문제가 있었다. 이 문제를 해결한 것이 '벡터 양자화된 변이형 오토인코더(Vector Quantised-VAE)' VQ-VAE 이다. 잠재 변수를 이산 값 즉 0,1,2 등 연속되지 않은 값으로 변환한다. 이는 이미지를 인코더에 입력하고 출력인 잠재 변수의 벡터를 코드북에 mapping해 구현한다.
VQ-VAE-2
VQ-VAE-2는 VQ-VAE를 계층 구조로 만들어 더 높은 해상도의 이미지를 생성할 수 있게 만든 기술이다. 이 잠재 표현은 원래 이미지보다 훨씬 작지마느 디코더에 입력하면 더 선명하고 사실적인 이미지를 재구현 가능하다.
'👾 Deep Learning' 카테고리의 다른 글
| 파이썬의 뉴런 (0) | 2021.02.24 |
|---|---|
| [Transformer] Model 정리 (0) | 2021.02.23 |
| [Transformer] Positional Encoding (3) (0) | 2021.02.20 |
| [Transformer] Position-wise Feed-Forward Networks (2) (0) | 2021.02.20 |
| [Transformer] Self-Attension 셀프 어텐션 (0) (0) | 2021.02.19 |