
728x90
nlp.seas.harvard.edu/2018/04/01/attention.html#position-wise-feed-forward-networks
The Annotated Transformer
The recent Transformer architecture from “Attention is All You Need” @ NIPS 2017 has been instantly impactful as a new method for machine translation. It also offers a new general architecture for many NLP tasks. The paper itself is very clearly writte
nlp.seas.harvard.edu
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
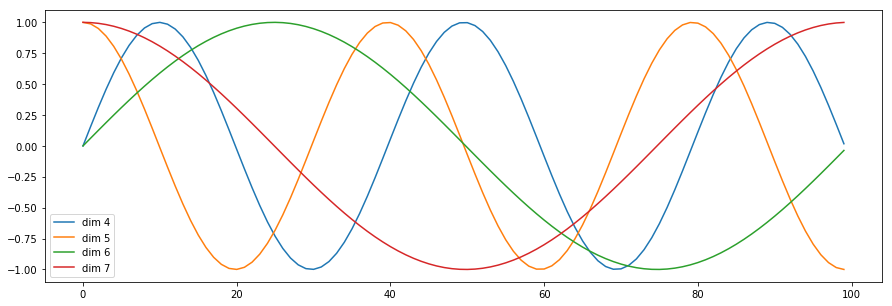
Postional Encoding
앞의 순환 신경망과 달리 트랜스포머 모델은 입력을 단어 하나하나 순차적으로 넣지 않고 한번에 넣는다. 입력 시퀀스에 대한 순서 정보를 전달해줘야한다.
순서 정보를 주입하는 함수 (짝수 : 2i, 홀수: 2i+1)
$\sin$과 $\cos$ 함수는 시퀀스 위치에 따라 피처 차원 인덱스에 각자의 위치 정보를 달리 주고자한다.
반응형
'👾 Deep Learning' 카테고리의 다른 글
| [Transformer] Model 정리 (0) | 2021.02.23 |
|---|---|
| VAE(Variational autoencoder) 종류 (0) | 2021.02.21 |
| [Transformer] Position-wise Feed-Forward Networks (2) (0) | 2021.02.20 |
| [Transformer] Self-Attension 셀프 어텐션 (0) (0) | 2021.02.19 |
| VAE(Variational Autoencoder) (3) MNIST (0) | 2021.02.18 |