
728x90
연속 단어 모음 접근 방식
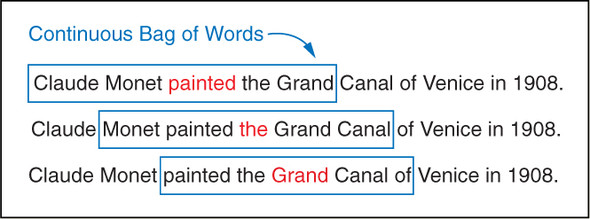
연속 단어 모음(CBOW) 접근 방식에서는 주어진 단어들에 기초해서 그 중심 단어를 예측한다. 따라서 하나의 훈련 견본은 하나의 입력 단어와 다수의 출력 단어들이 아니라 다수의 주변 단어들과 하나의 중심 단어로 구성된다. 다수의 주변 단어들은 멀티핫 벡터로 표현한다. 이 멀티핫 벡터는 주변 단어들의 원핫 벡터들을 모두 합한 것이다.

painted가 기대출력일 때
$W_{t-2}$ = Claude
$W_{t-1}$ = Monet
$W_{t}$ = painted
$W_{t+1}$ = the
$W_{t+2}$ = Grand
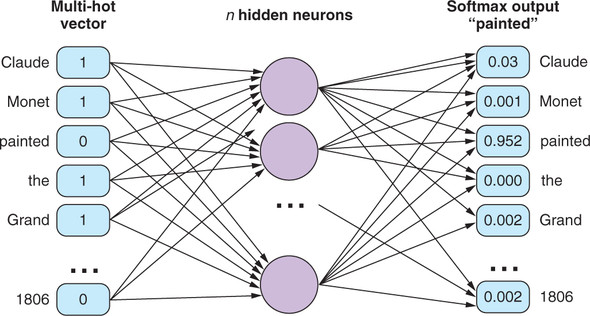
문서를 토큰화해서 얻은 주변 단어 멀티핫 벡터와 목표 단어 원핫 벡터의 쌍들로 이루어진 훈련 자료 집합으로 신경망을 훈련한다. 즉 목표 단어 $w_t$의 원핫 벡터를 신경망의 기대 출력으로 두고 그 주변 단어 $w_{t-2}$, $w_{t-1}$, $w_{t+1}$, $w_{t+2}$의 멀티핫 벡터를 입력으로 두어서 신경망의 순전파 단계를 진행한다. 스킵 그램처럼 출력층은 소프트맥스를 이용해서 각 단어의 확률을 계산하고, 확률이 가장 높은 단어의 원핫 벡터를 출력한다.
사용 용도
ㅇ말뭉치가 작을 때 그리고 자주 쓰이지 않는 단어들이 주어 졌을 때 스킵 그램이 잘 작동한다.
ㅇ연속 단어 모음 접근 방식은 자주 쓰이는 단어들에 대해 정확도가 높으며 훈련이 훨씬 더 빠르다.
반응형
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [Word2Vec] 구현 패키지 사용 (4) | 2021.03.02 |
|---|---|
| [Word2Vec] 계산 (0) | 2021.03.01 |
| [Word2Vec] 스킵그램 접근 방식 (0) | 2021.02.28 |
| Word2Vec 활용 (0) | 2021.02.28 |
| 의미 기반 검색(semantic search) (0) | 2021.02.23 |