
전문 검색
특정 단어나 문구가 있는 문서를 검색하는 것을 전문 검색(full text search)이라고 한다. 검색 엔진이 하는 기능이다. 검색 엔진들은 문서를 여러 조각으로 나누고, 각 조각들이 문서에 있는지 역색인(inversed index)을 작성한다. 책 뒷면에 keyword를 정리해둔 페이지와 비슷한 역할이다.

의미 기반 검색(semantic search)
질의문을 구성하는 단어들의 의미를 고려해서 문서를 찾는다. LSA와 LDiA를 사용해 주제 벡터를 구하는 방법으로 찾는다. 이 기법이 BOW나 TF-IDF 벡터 같은 수치들의 '색인'을 이용한 의미 기반 검색을 가능하게 하는 방법이다.
그러나 BOW나 TF-IDF벡터와 달리 의미 벡터들의 테이블은 전통적인 역색인 기법들로 쉽게 이산화하고 색인화할 수 없다. 이전 색인화 접근 방식은 주로 BOW, 이산벡터, TF-IDF 벡터 같은 희소 연속 벡터, 3차원 GIS 데이터 같은 저차원 연속을 대상으로 한다. LSA, LDiA 같은 고차원 벡터는 그런 접근 방식으로 색인화하기 어렵다. 연속형을 정수로 이산화 작업을 거쳐 색인 항목을 두어도 된다. TF-IDF의 경우 희소 벡터이므로 대부분의 차원이 0이다. 색인 항목을 줄일 수 있다.
LSA와 LDiA가 산출하는 주제 벡터는 고차원 연속 조밀(0인 성분이 별로 없는) 벡터이다. 그리고 의미 분석 알고리즘은 규모가변적 검색에 적합한 효율적인 색인을 제공하지 않는다. 잠재 의미 벡터의 '색인화'는 현실적으로 문제가 많다. 차원의 저주 때문에 정확한 색인을 얻기 불가능하기 때문이다.
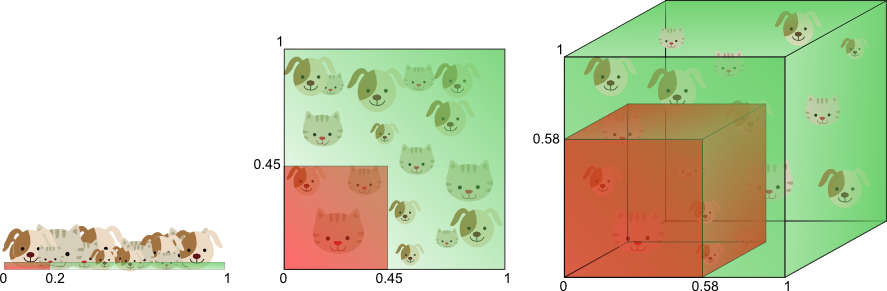
고차원 벡터를 효율적으로 색인화하는 방법은 LSH(locality sensitive hash,LSH) 이다. LSH는 초공간의 한 여역을 서술하는 좌표라고 할 수 있다. LSH는 이산적이고 오직 벡터 값에만 의존한다. 그러나 12차원 이상의 차원에서 더 이상 완벽하게 작동하지 않는다. 주제 벡터의 차원은 2~16 사이 이다.
NumPy로 행렬 곱셈 연산들을 병렬화 할 수 있지만, 연산 수가 줄어 들지는 않는다. 대규모 커~~다란 말뭉치 규모에서는 O(n) 알고리즘이 통하지 않는다. 따라서 색인화 보다는 검색 결과를 좋게 만드는 방향으로 구축한다. 예를 들어 LSH와 함께 근사 최근접 이웃(approximate nearest neighbor) 알고리즘을 이용하면 큰 말뭉치에 대한 좋은 결과를 얻을 수 있다.
구현 알고리즘
- Spotify의 Annoy패키지
- genism의 genism.models.KeyedBector 클래스
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [Word2Vec] 스킵그램 접근 방식 (0) | 2021.02.28 |
|---|---|
| Word2Vec 활용 (0) | 2021.02.28 |
| 선형 판별 분석 ( LDA ) (0) | 2021.02.23 |
| LSA 거리와 유사도 (0) | 2021.02.21 |
| [Transformer] Multi-Head Attention (1) (0) | 2021.02.20 |