
스킵그램 접근 방식
스킵그램 접근 방식에서는 주어진 입력 다넝에 기초해서 일정 범위 이내의 주변 단어들을 예측하도록 모형을 훈련한다.
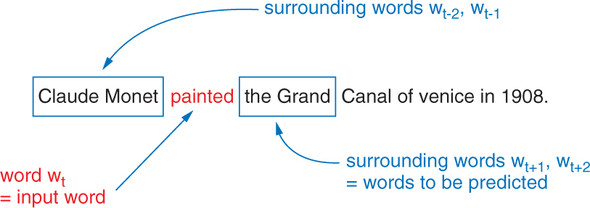
painted 주변 단어를 예측하는 예시이다. painted에 대해 신경망은 claude, monet, the, grand 라는 주변 단어 스킵그램을 출력한다. skip gram은 skip 말그대로 painted를 시작해 Monet과 the 토큰을 건너 뛰고 claude. Grand를 예측하는 것이다.
주변 단어들을 예측하는 신경망의 구조는 신경망의 구조와 비슷하다. 스킵그램을 위한 신경망의 구조는 입력층과 은닉층, 출력층으로 이루어진 다층 신경망이다. 은닉층은 n개의 뉴런으로 구성되어있으며 여기서 n은 단어하나를 표현하는 벡터의 차원 수이다. 입력층과 출력층은 각각 M개의 뉴런으로 구성되는데, 여기서 M은 모형의 어휘 크기이다. 출력층의 활성화 함수는 분류 문제에 흔히 쓰이는 소프트맥스 함수이다.
소프트맥스 함수
소프트맥스 함수는 분류 문제의 햅버을 배우는 것이 목표인 신경망의 출력층 활성화 함수로 자주 쓰인다. 0~1 사이의 값을 출력값으로 쓴다. 압착한다.(squash)라 한다. 출력의 합은 항상 1이다. 따라서 출력층의 한 소프트맥스의 출력을 확률로 취급할 수 있다.
출력층 K개의 노드 각각에 대해 정규화된 지수함수로 정의된다.
$\sigma(z)_{j} = \frac{e^{z_j}}{\sum^K_{k=1}{e^{z_k}}}$
v = [0.5, 0.9, 0.2] softmax(v) = [0.30.9, 0.461, 0.229]
Sentence = "Claude Monet painted the Grand Canal of Venice in 1806"
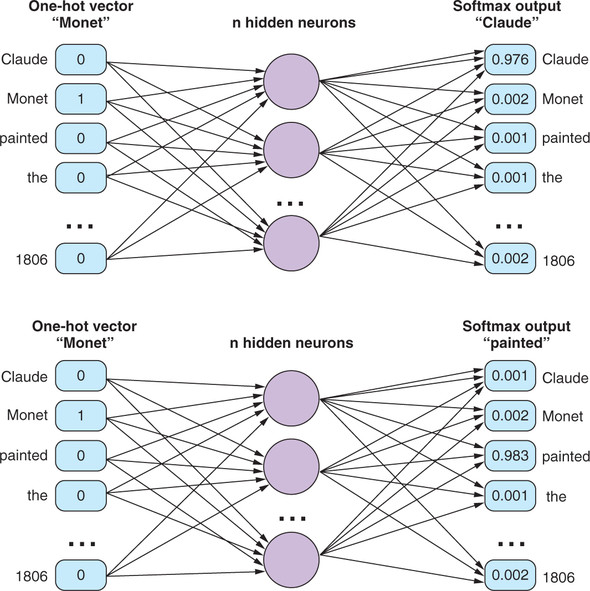
Input word : Monet
expected output : Claude painted
Sentence = "Claude Monet painted the Grand Canal of Venice in 1806"
문장을 토큰화해서 나온 10개의 5-그램
painted가 input word일 때
Wt-2 = Claude
Wt-1 = Monet
Wt = painted
Wt+1 = the
Wt+2 = Grand
이처럼 5-gram 일 경우 기대 출력이 총 4개이다. 4개의 주변 단어가 있을 경우 4번의 훈련 과정을 거친다. 기대 출력은 원-핫 벡터로 표현되어 소프트 맥스 함수를 이용해 출력 단어가 주변에 등장할 확률을 계산한다. 등장할 확률이 가장 큰 단어에 해당하는 성분만 1이고 나머지 성분들은 0인 벡터로 출룍을 사용하면 손실함수의 계산이 간단해진다.
주어진 입력에 대해 출력 원핫 벡터와 손실함수를 계산하고 그로부터 역전파를 진행해서 연결 가중치들을 학습하는 과정이 모두 끝나면 가중치들은 단어의 의미를 반영한다. 애초에 신경망이 주어진 단어 주변에 나타날 확률이 높은 단어들을 잘 예측하도록 훈련되어 있으므로, 그리고 신경망의 입력과 출력이 원핫 벡터의 형태이므로 가중치 행렬의 각 행은 어휘의 각 단어 주변에 나타날 가능성이 큰 단어들을 말해준다. 주변에 나타나는 단어들이 비슷한 두 단어는 그 의미나 쓰임새도 비슷할 것이라고 가정할 수 있다. 결과적으로 가중치 행렬의 각 행은 각 단어의 의미를 반영한다.
훈련이 끝나면 신경망의 출력층은 이제 쓸모가 없다. 우리가 원하는 것은 입력층과 은닉층을 연결하는 가중치들이다. 입력 단어를 표현한 원핫 벡터와 이 가중치 행렬을 곱한 것이 바로 단어 벡터 내장(word vector embedding)이다.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [Word2Vec] 계산 (0) | 2021.03.01 |
|---|---|
| [Word2Vec] 연속 단어 모음 (0) | 2021.03.01 |
| Word2Vec 활용 (0) | 2021.02.28 |
| 의미 기반 검색(semantic search) (0) | 2021.02.23 |
| 선형 판별 분석 ( LDA ) (0) | 2021.02.23 |