
728x90
nlp.seas.harvard.edu/2018/04/01/attention.html#position-wise-feed-forward-networks
The Annotated Transformer
The recent Transformer architecture from “Attention is All You Need” @ NIPS 2017 has been instantly impactful as a new method for machine translation. It also offers a new general architecture for many NLP tasks. The paper itself is very clearly writte
nlp.seas.harvard.edu
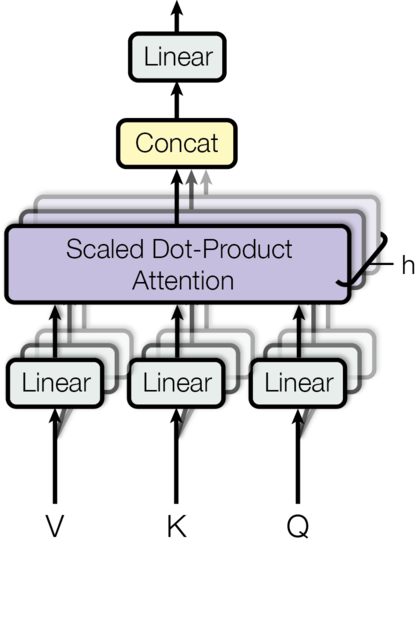
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.p = dropout
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask, dropout=self.p)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
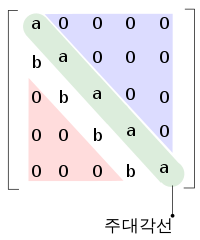
return self.linears[-1](x)Attention이 하나의 Sentence가 아닌 여러 문장의 정보를 줄수 있게 Scaled Dot-Product Attention을 수행한 Query, Key , Value 정보를 넘긴다. 넘기는 과정에서 하삼각행렬(lower triangular matrix)만이 정보이고 나머지 상삼각행렬(upper triangular matrix)은 0으로 채워진다. 따라서 나머지 불필요한 윗부분을 아주작은 수로 채워 넣어 후에 Softmax함수를 적용하게해 0으로 만든다.
반응형
'🗣️ Natural Language Processing' 카테고리의 다른 글
| 선형 판별 분석 ( LDA ) (0) | 2021.02.23 |
|---|---|
| LSA 거리와 유사도 (0) | 2021.02.21 |
| 잠재 디클레 할당 (LDiA, Latent Dirichlet Allocation) (0) | 2021.02.17 |
| [Kaggle] 네이버 영화 리뷰 분류(2) (0) | 2021.02.17 |
| 챗 봇 만들기(1) (0) | 2021.02.13 |