
https://github.com/seohyunjun/RL_DDPG
GitHub - seohyunjun/RL_DDPG: CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING (a.k.a DDPG)
CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING (a.k.a DDPG) - GitHub - seohyunjun/RL_DDPG: CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING (a.k.a DDPG)
github.com
DDPG
* Continuous Action Space RL 문제 해결 (기존의 DQN discrete action space)
* DQN에서 actor-critic 사용
* off-policy
* Target Network(=AC) 사용
* Soft Update(Target Network를 업데이트할 때, parameter update t(tau) 비율 조정)

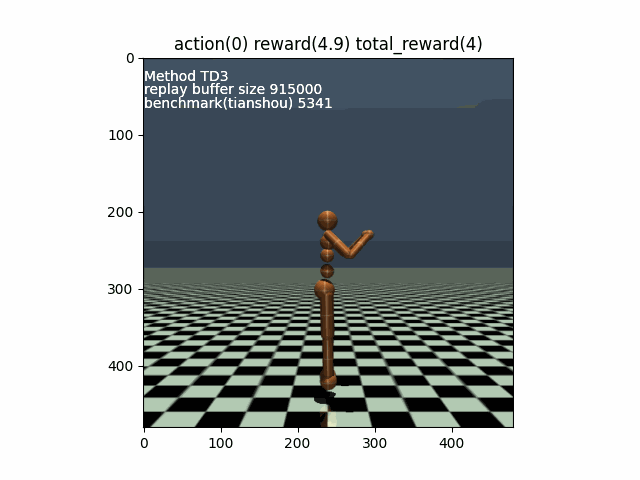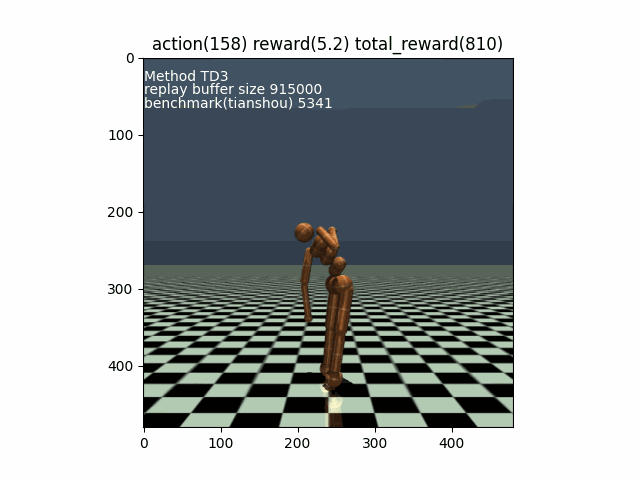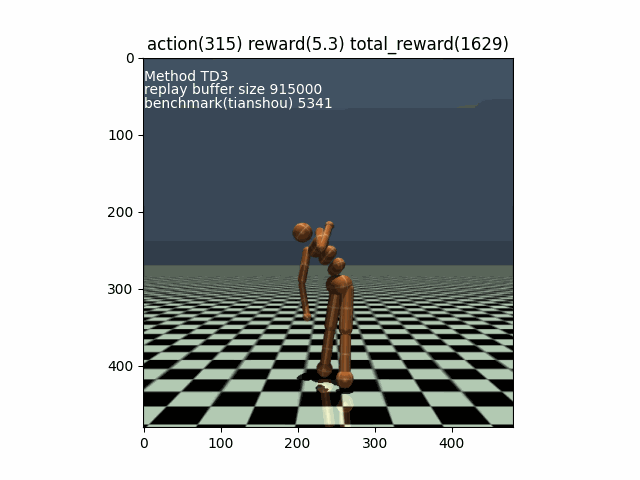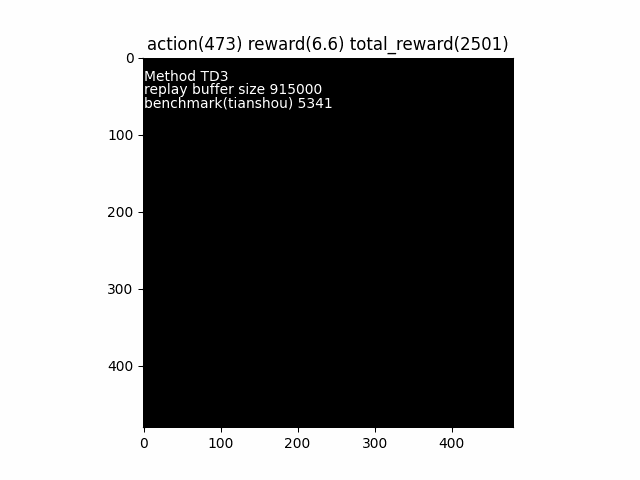
[Example Mujoco_Humanoid-v4] Episode 30
'👾 Deep Learning' 카테고리의 다른 글
| [RL] Soft Actor-Critic (a.k.a SAC) (0) | 2023.04.12 |
|---|---|
| [M1] Whisper.cpp Deploy C++ (ALL OS-) (0) | 2023.04.06 |
| [RL] M1 Mac Mujoco_py 설치 (gcc@9 error) (0) | 2023.03.29 |
| [RL] A3C (비동기 Advantage Actor-Critic) 정리 (0) | 2023.03.28 |
| [RL] A3C (Asynchronous Advantage Actor-Critic) (0) | 2023.03.28 |
https://github.com/seohyunjun/RL_DDPG
GitHub - seohyunjun/RL_DDPG: CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING (a.k.a DDPG)
CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING (a.k.a DDPG) - GitHub - seohyunjun/RL_DDPG: CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING (a.k.a DDPG)
github.com
DDPG
* Continuous Action Space RL 문제 해결 (기존의 DQN discrete action space)
* DQN에서 actor-critic 사용
* off-policy
* Target Network(=AC) 사용
* Soft Update(Target Network를 업데이트할 때, parameter update t(tau) 비율 조정)
[Example Mujoco_Humanoid-v4] Episode 30
'👾 Deep Learning' 카테고리의 다른 글
| [RL] Soft Actor-Critic (a.k.a SAC) (0) | 2023.04.12 |
|---|---|
| [M1] Whisper.cpp Deploy C++ (ALL OS-) (0) | 2023.04.06 |
| [RL] M1 Mac Mujoco_py 설치 (gcc@9 error) (0) | 2023.03.29 |
| [RL] A3C (비동기 Advantage Actor-Critic) 정리 (0) | 2023.03.28 |
| [RL] A3C (Asynchronous Advantage Actor-Critic) (0) | 2023.03.28 |