
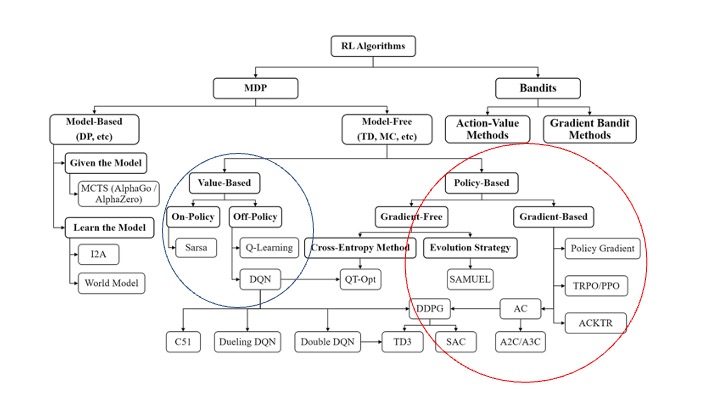
Policy-Based
기존에 Value Based 즉 Q-value를 예측하는 방식은 State와 action에 의존해 항상 trajectories(state-action-reward sequence)를 구해나가야하는 제약이 있었다. 하지만 Policy-Based는 Q-value뿐 아니라 Policy에 대한 추정도 같이하는 것이다. 우리가 원하는 것은 Agent가 올바른 길로 가는 전략을 찾는 것으로 Policy-Based가 이를 더 잘 반영해주었다.
장점으로는
- policy를 직접 학습하므로 안정성이 높다.(환경 변화, 노이즈에 덜 민감)
- 확률적인 정책(Exploration, Exploitation) 사이의 균형을 조절하면서 π*(Optimal Policy)를 학습
- Continuous space에서도 잘 작동
- 다양한 Optimizer 사용 가능
Advantage Value
A(s, a) = Q(s, a) - V(s)
• A(s, a) : 상태 s에서 행동 a를 취했을 때의 Advantage 값
• Q(s, a) : 상태 s에서 행동 a를 취했을 때의 Q-value
• Q-value : 상태와 행동 쌍에 대한 기대 보상
• V(s) : 상태 s의 Value function 값 (Value function은 현재 상태의 기대 보상)
Advantage 사용하는 이유는 Policy Gradient에서 사용되는 보상값 대신 Advantage를 사용함으로써 gradinet 추정치의 기댓값을 0으로 만들어 Variance를 줄인다.
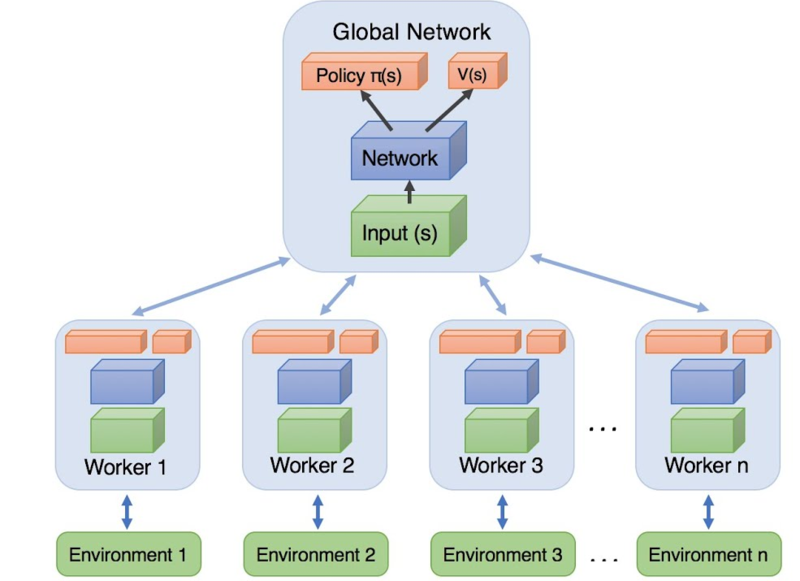
Actor-Critic
actor-critic은 actor환경에서 마구 다양한 환경을 접하게해 해당 환경에서 policy를 학습할때 생기는 gradient를 Global Network에 Update한다. 이때 유의미한 Gradient를 학습하기 위해 Critic이 평가를 한뒤 Update 하게 된다.
그래서 model 안에는 총 두가지의 gradient가 존재한다. Actor_network, Critic_network
'👾 Deep Learning' 카테고리의 다른 글
| [RL] Deep Deterministic Policy Gradient (A.K.A DDPG) (0) | 2023.04.04 |
|---|---|
| [RL] M1 Mac Mujoco_py 설치 (gcc@9 error) (0) | 2023.03.29 |
| [RL] A3C (Asynchronous Advantage Actor-Critic) (0) | 2023.03.28 |
| [Reinforce Learning] Deep Q-Network (0) | 2023.03.26 |
| [Whisper] Robust Speech Recognition via Large-Scale Weak Supervision - (4) (0) | 2023.03.21 |
Policy-Based
기존에 Value Based 즉 Q-value를 예측하는 방식은 State와 action에 의존해 항상 trajectories(state-action-reward sequence)를 구해나가야하는 제약이 있었다. 하지만 Policy-Based는 Q-value뿐 아니라 Policy에 대한 추정도 같이하는 것이다. 우리가 원하는 것은 Agent가 올바른 길로 가는 전략을 찾는 것으로 Policy-Based가 이를 더 잘 반영해주었다.
장점으로는
- policy를 직접 학습하므로 안정성이 높다.(환경 변화, 노이즈에 덜 민감)
- 확률적인 정책(Exploration, Exploitation) 사이의 균형을 조절하면서 π*(Optimal Policy)를 학습
- Continuous space에서도 잘 작동
- 다양한 Optimizer 사용 가능
Advantage Value
A(s, a) = Q(s, a) - V(s)
• A(s, a) : 상태 s에서 행동 a를 취했을 때의 Advantage 값
• Q(s, a) : 상태 s에서 행동 a를 취했을 때의 Q-value
• Q-value : 상태와 행동 쌍에 대한 기대 보상
• V(s) : 상태 s의 Value function 값 (Value function은 현재 상태의 기대 보상)
Advantage 사용하는 이유는 Policy Gradient에서 사용되는 보상값 대신 Advantage를 사용함으로써 gradinet 추정치의 기댓값을 0으로 만들어 Variance를 줄인다.
Actor-Critic
actor-critic은 actor환경에서 마구 다양한 환경을 접하게해 해당 환경에서 policy를 학습할때 생기는 gradient를 Global Network에 Update한다. 이때 유의미한 Gradient를 학습하기 위해 Critic이 평가를 한뒤 Update 하게 된다.
그래서 model 안에는 총 두가지의 gradient가 존재한다. Actor_network, Critic_network
'👾 Deep Learning' 카테고리의 다른 글
| [RL] Deep Deterministic Policy Gradient (A.K.A DDPG) (0) | 2023.04.04 |
|---|---|
| [RL] M1 Mac Mujoco_py 설치 (gcc@9 error) (0) | 2023.03.29 |
| [RL] A3C (Asynchronous Advantage Actor-Critic) (0) | 2023.03.28 |
| [Reinforce Learning] Deep Q-Network (0) | 2023.03.26 |
| [Whisper] Robust Speech Recognition via Large-Scale Weak Supervision - (4) (0) | 2023.03.21 |