
728x90
Model Info
- 중국 Baidu에서 공개한 End-to-End 음성인식 모델(2015.12)
- 음성데이터에 Melspectrograms을 적용
- Fourier Transform시 발생하는 각 음성 feature의 위치를 파악할 수 없다.
- STFT(short time fourier transform)을 적용, 음성 feature를 좁은 단위로 FT를 적용해 feature의 위치를 반영
- 사람은 저주파수에 대해 민감히 잘 파악한다. 고주파수에 대한 음성은 잘 인식하지 못한다.
- 주파수를 사람의 인식단위로 mel scale 변환
- Mel(f) = 2595 * log(1+ f / 700)
- 주파수를 사람의 인식단위로 mel scale 변환
- Mel feature를 CNN과 RNN을 거친 뒤 CTC(Connectionist Temporal Classification)을 적용
- Fourier Transform시 발생하는 각 음성 feature의 위치를 파악할 수 없다.

CTC (Connectionist temporal classification)
- 장점
- 음성 데이터의 별다른 라벨링 없이 시퀀스 간의 거리를 파악
- 시퀀스간 조건부 확률을 통해 P(S_t|S_t+1) 간의 유사성으로 전사에 대한 구분 C(hel-lo) = C(h-ello) = C(hello)
- 단점
- 시퀀스간 조건부 확률을 적용하므로 계산량이 증가한다.
- beam 계산으로 중복 연산방지
- Mel 함수 적용 + CTC 적용시 feature의 프레임이 변하게 되어 학습이 제대로 이루어지지 않을 수 있다.
- 시퀀스간 조건부 확률을 적용하므로 계산량이 증가한다.
Train Compose (AI Hub 한국어 음성, 17G)
Using Kospeech
| batch size | 32 |
| init_lr_scale | 0.01 |
| final_lr_scale | 0.05 |
| optimizer | adam |
| init_lr | 0.000001 |
| final_lr | 0.000001 |
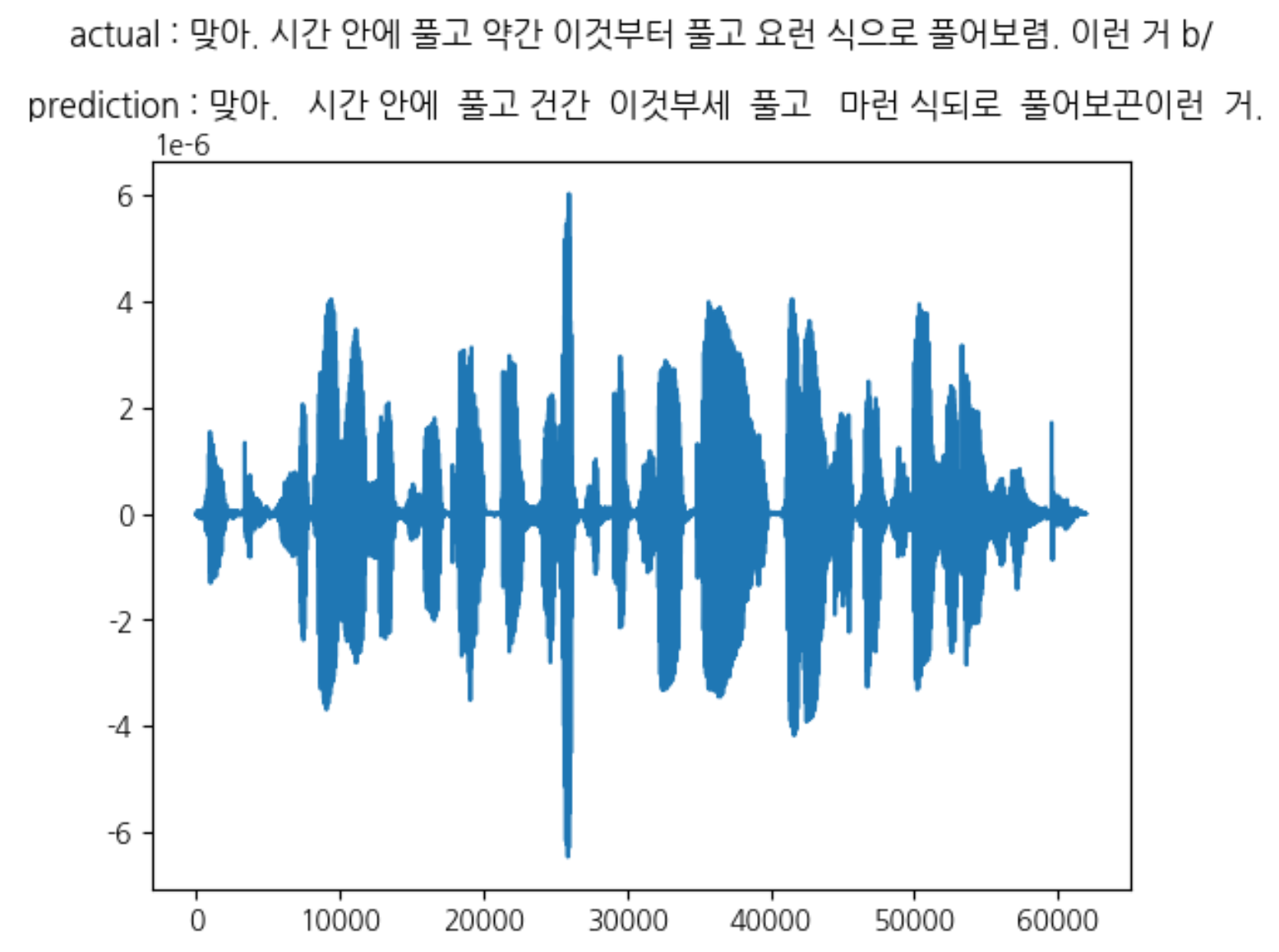
Result
| Cost Time | 137.68h |
| Epoch | 18 / 70 |
| CER | 0.26 |
| loss | 0.419 |

반응형
'👾 Deep Learning' 카테고리의 다른 글
| [NVIDIA RIVA ASR] 설치 가이드 (feat.nvidia-riva-sdk) (0) | 2023.02.23 |
|---|---|
| [from numba.np.ufunc import _internalSystemError: initialization of _internal failed without raising an exception] numpy version Error (0) | 2023.02.23 |
| [NVIDIA RIVA] ngc 등록 (0) | 2023.01.27 |
| [mac] VToonify [...ing] (0) | 2023.01.15 |
| ViT(Vision in Transformer) Review (0) | 2022.12.19 |
728x90
Model Info
- 중국 Baidu에서 공개한 End-to-End 음성인식 모델(2015.12)
- 음성데이터에 Melspectrograms을 적용
- Fourier Transform시 발생하는 각 음성 feature의 위치를 파악할 수 없다.
- STFT(short time fourier transform)을 적용, 음성 feature를 좁은 단위로 FT를 적용해 feature의 위치를 반영
- 사람은 저주파수에 대해 민감히 잘 파악한다. 고주파수에 대한 음성은 잘 인식하지 못한다.
- 주파수를 사람의 인식단위로 mel scale 변환
- Mel(f) = 2595 * log(1+ f / 700)
- 주파수를 사람의 인식단위로 mel scale 변환
- Mel feature를 CNN과 RNN을 거친 뒤 CTC(Connectionist Temporal Classification)을 적용
- Fourier Transform시 발생하는 각 음성 feature의 위치를 파악할 수 없다.
CTC (Connectionist temporal classification)
- 장점
- 음성 데이터의 별다른 라벨링 없이 시퀀스 간의 거리를 파악
- 시퀀스간 조건부 확률을 통해 P(S_t|S_t+1) 간의 유사성으로 전사에 대한 구분 C(hel-lo) = C(h-ello) = C(hello)
- 단점
- 시퀀스간 조건부 확률을 적용하므로 계산량이 증가한다.
- beam 계산으로 중복 연산방지
- Mel 함수 적용 + CTC 적용시 feature의 프레임이 변하게 되어 학습이 제대로 이루어지지 않을 수 있다.
- 시퀀스간 조건부 확률을 적용하므로 계산량이 증가한다.
Train Compose (AI Hub 한국어 음성, 17G)
Using Kospeech
| batch size | 32 |
| init_lr_scale | 0.01 |
| final_lr_scale | 0.05 |
| optimizer | adam |
| init_lr | 0.000001 |
| final_lr | 0.000001 |
Result
| Cost Time | 137.68h |
| Epoch | 18 / 70 |
| CER | 0.26 |
| loss | 0.419 |
반응형
'👾 Deep Learning' 카테고리의 다른 글
| [NVIDIA RIVA ASR] 설치 가이드 (feat.nvidia-riva-sdk) (0) | 2023.02.23 |
|---|---|
| [from numba.np.ufunc import _internalSystemError: initialization of _internal failed without raising an exception] numpy version Error (0) | 2023.02.23 |
| [NVIDIA RIVA] ngc 등록 (0) | 2023.01.27 |
| [mac] VToonify [...ing] (0) | 2023.01.15 |
| ViT(Vision in Transformer) Review (0) | 2022.12.19 |