
728x90
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Vision in Transformer는 CNN 없이 Image Classification을 수행할 수 있다는 것을 보여준 하나의 사례이다. 이전에도 Transformer와 Vision을 합친 시도는 있었지만 방대한 양의 학습을 진행한 연구는 없었다. 학습양이 많고 예측 Label이 많을 경우 갖는 문제점을 개선하고 연산 감소(CNN 대비)와 Pre-trained Model이라는 점에서 Attention의 장점을 많이 활용했다.
CNN SOTA 대비 두가지 문제를 해결했다.
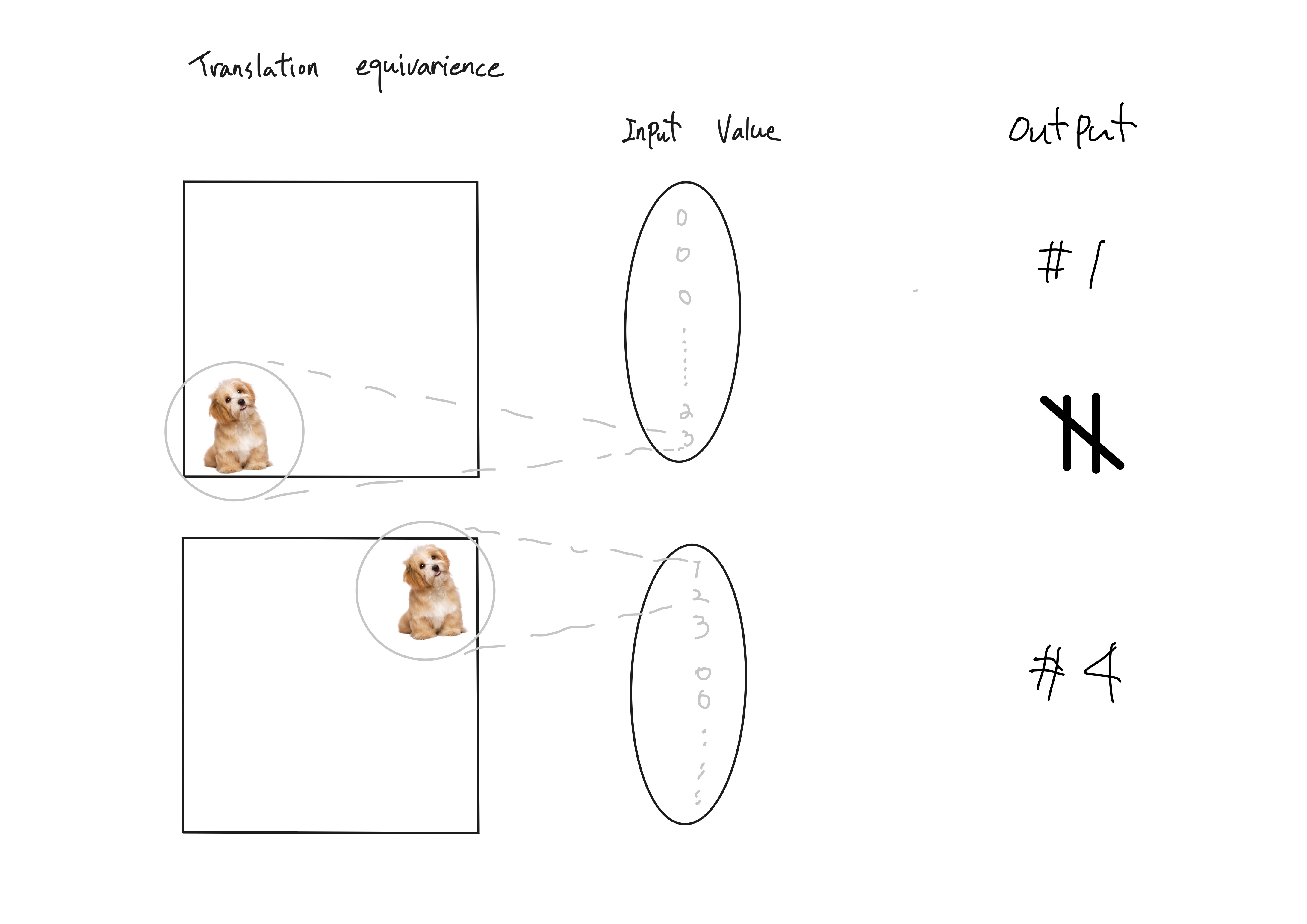
1. CNN(Convolution Neural Network)에서 발생하는 translation equivariance를 Self-Attention과 Large-scale training으로 해결
*translation equivariance : 같은 object의 이미지더라도 물체의 위치에 따라 Input 값이 달라져 Output이 동일하게 나오지 않는 것을 말한다.
2. 모델 일반화 개선
* inductive bias : 학습 시에 주어지지 않은 Input에 대해 정확한 예측을 하기 위해 사용하는 추가적인 가정
예측해야하는 label이 많을 경우 global한 training이 수행해야하는데 CNN의 경우 local적으로 얻는 정보가 많아 Transformer 사용 (예측 Label이 적을 경우 CNN 계열 사용이 더 성능이 좋다.)
반응형
'👾 Deep Learning' 카테고리의 다른 글
| [NVIDIA RIVA] ngc 등록 (0) | 2023.01.27 |
|---|---|
| [mac] VToonify [...ing] (0) | 2023.01.15 |
| Tensor 가지고 놀기 [Einsum + einops] (0) | 2022.12.17 |
| [Computer Vision] Image Modul Pillow import Error (0) | 2022.12.14 |
| [Model Train Error] 모델 학습 시 무한 루프 /Unknown batch (0) | 2022.05.25 |
728x90
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Vision in Transformer는 CNN 없이 Image Classification을 수행할 수 있다는 것을 보여준 하나의 사례이다. 이전에도 Transformer와 Vision을 합친 시도는 있었지만 방대한 양의 학습을 진행한 연구는 없었다. 학습양이 많고 예측 Label이 많을 경우 갖는 문제점을 개선하고 연산 감소(CNN 대비)와 Pre-trained Model이라는 점에서 Attention의 장점을 많이 활용했다.
CNN SOTA 대비 두가지 문제를 해결했다.
1. CNN(Convolution Neural Network)에서 발생하는 translation equivariance를 Self-Attention과 Large-scale training으로 해결
*translation equivariance : 같은 object의 이미지더라도 물체의 위치에 따라 Input 값이 달라져 Output이 동일하게 나오지 않는 것을 말한다.
2. 모델 일반화 개선
* inductive bias : 학습 시에 주어지지 않은 Input에 대해 정확한 예측을 하기 위해 사용하는 추가적인 가정
예측해야하는 label이 많을 경우 global한 training이 수행해야하는데 CNN의 경우 local적으로 얻는 정보가 많아 Transformer 사용 (예측 Label이 적을 경우 CNN 계열 사용이 더 성능이 좋다.)
반응형
'👾 Deep Learning' 카테고리의 다른 글
| [NVIDIA RIVA] ngc 등록 (0) | 2023.01.27 |
|---|---|
| [mac] VToonify [...ing] (0) | 2023.01.15 |
| Tensor 가지고 놀기 [Einsum + einops] (0) | 2022.12.17 |
| [Computer Vision] Image Modul Pillow import Error (0) | 2022.12.14 |
| [Model Train Error] 모델 학습 시 무한 루프 /Unknown batch (0) | 2022.05.25 |