
nlpia를 통해 미리 훈련된 구글 뉴스 word2vec 모형을 받아온다. 단어 수 30만개
import os
from nlpia.loaders import get_data
from gensim.models.word2vec import Word2VecKeyedVectors
wv = get_data('word2vec')
len(wv.vocab) #3000000
n-gram 단어들이 '_' 문자로 연결된 것을 확인 할 수 있다.
import pandas as pd
from tqdm import tqdm
vocab = pd.Series(wv.vocab)
vocab.iloc[1000000:1000006]
# Starwood_Hotels_HOT Vocab(count:2000000, index:1000000)
# Tammy_Kilborn Vocab(count:1999999, index:1000001)
# aortic_aneurism Vocab(count:1999998, index:1000002)
# Spragins_Hall Vocab(count:1999997, index:1000003)
# Ed_Iacobucci Vocab(count:1999996, index:1000004)
# Seilheimer Vocab(count:1999995, index:1000005)'Seilheimer' 단어 벡터는 아래 와 같이 확인 할 수있다. 300개의 단어 벡터를 보여준다.
wv['Seilheimer']
# array([ 0.10107422, 0.08935547, -0.15429688, -0.04956055, -0.00436401,
# -0.06079102, -0.07421875, -0.06005859, -0.06079102, -0.02758789,
# 0.03015137, -0.05712891, -0.07617188, 0.05786133, -0.05249023,
# .....dtype=float32)
wv['Seilheimer'].shape # (300,)'Seilheimer' 과 'Seil'의 거리를 확인해 보았다.
유클리드 거리, 코사인 유사도, 코사인 거리 확인
2.5733225import numpy as np
np.linalg.norm(wv['Seilheimer'] - wv['Seil']) # 2.5733225
cos_similarity = np.dot(wv['Seilheimer'],wv['Seil']) / (np.linalg.norm(wv['Seilheimer'])*np.linalg.norm(wv['Seil']))
cos_similarity # 0.35953805
1 - cos_similarity # 0.6404619514942169'Seilheimer' 과 'Seil'의 거리는 별 차이가 없었다. 'Seilheimer' 과 'person'의 단어 거리를 보면 'Seilheimer'라는 단어가 사람이랑 높게 연관되어 있음을 알 수 있다.
np.linalg.norm(wv['Seilheimer'] - wv['person'])
cos_similarity = np.dot(wv['Seilheimer'],wv['person']) / (np.linalg.norm(wv['Seilheimer'])*np.linalg.norm(wv['person']))
cos_similarity # 0.039810065
1 - cos_similarity # 0.96cities = get_data('cities')
cities.head(1).T
# geonameid 3039154
# name El Tarter
# asciiname El Tarter
# alternatenames Ehl Tarter,Эл Тартер
# latitude 42.5795
# longitude 1.65362
# feature_class P
# feature_code PPL
# country_code AD
# cc2 NaN
# admin1_code 02
# admin2_code NaN
# admin3_code NaN
# admin4_code NaN
# population 1052
# elevation NaN
# dem 1721
# timezone Europe/Andorra
# modification_date 2012-11-03# Geocities의 자료를 통해 지도위의 위치와 각 지방간의 거리를 비교하기
cities = get_data('cities')
cities.head(1).T
# geonameid 3039154
# name El Tarter
# asciiname El Tarter
# alternatenames Ehl Tarter,Эл Тартер
# latitude 42.5795
# longitude 1.65362
# feature_class P
# feature_code PPL
# country_code AD
# cc2 NaN
# admin1_code 02
# admin2_code NaN
# admin3_code NaN
# admin4_code NaN
# population 1052
# elevation NaN
# dem 1721
# timezone Europe/Andorra
# modification_date 2012-11-03한국의 지방 정보를 다 가져온다.
그 후 st 지방의 고유 번호를 통해 state 데이터와 mapping 시켜 데이터를 통합니다.
kr = cities[(cities.country_code == "KR") & (cities.admin1_code.notnull())].copy()
# name asciiname ... timezone modification_date
# geonameid ...
# 1832015 Heunghae Heunghae ... Asia/Seoul 2016-09-09
# 1832215 Yeonil Yeonil ... Asia/Seoul 2016-09-09
# 1832257 Neietsu Neietsu ... Asia/Seoul 2012-01-18
# 1832384 Eisen Eisen ... Asia/Seoul 2012-01-18
# 1832501 Reiko Reiko ... Asia/Seoul 2012-01-18
# ... ... ... ... ...
# 9887776 Dongmyeon Dongmyeon ... Asia/Seoul 2015-01-08
# 10913399 Yeonsan Yeonsan ... Asia/Seoul 2015-11-10
# 11124627 Oepo Oepo ... Asia/Seoul 2016-04-12
# 11523293 Sejong Sejong ... Asia/Seoul 2017-04-11
# 11549691 Bupyeong Bupyeong ... Asia/Seoul 2017-05-25
# [175 rows x 18 columns]
# kr = cities[(cities.country_code == "KR")]
# kr = cities[(cities.country_code == "KR") & (cities.admin1_code.notnull())].copy()
# kr
# Out[36]:
# name asciiname ... timezone modification_date
# geonameid ...
# 1832015 Heunghae Heunghae ... Asia/Seoul 2016-09-09
# 1832215 Yeonil Yeonil ... Asia/Seoul 2016-09-09
# 1832257 Neietsu Neietsu ... Asia/Seoul 2012-01-18
# 1832384 Eisen Eisen ... Asia/Seoul 2012-01-18
# 1832501 Reiko Reiko ... Asia/Seoul 2012-01-18
# ... ... ... ... ...
# 9887776 Dongmyeon Dongmyeon ... Asia/Seoul 2015-01-08
# 10913399 Yeonsan Yeonsan ... Asia/Seoul 2015-11-10
# 11124627 Oepo Oepo ... Asia/Seoul 2016-04-12
# 11523293 Sejong Sejong ... Asia/Seoul 2017-04-11
# 11549691 Bupyeong Bupyeong ... Asia/Seoul 2017-05-25
# [175 rows x 18 columns]
states = pd.read_csv('states.csv',header=True)
states
states.Abbreviation[0] = '01'
states.Abbreviation[1] = '03'
states.Abbreviation[2] = '05'
states.Abbreviation[3] = '06'
states
states = dict(zip(states.Abbreviation, states.State))
kr['city']= kr.name.copy()
kr['st'] = kr.admin1_code.copy()
kr['state'] = kr.st.map(states)
kr[kr.columns[-3:]].head()
vocab = pd.np.concatenate([kr.city,kr.st,kr.state])
vocab = np.array([word for word in vocab if word in wv.wv])
vocab[:5] #array(['Eisen', 'Reiko', 'Eisen', 'Yeoncheon', 'Yeoju'], dtype='<U9')
# 주 단어 벡터로 도시 단어 벡터 증강
한국에는 광주광역시와 경기도 광주시가 있다. 이처럼 그 도시가 속한 주를 연결하는 것이 도시 벡터를 해당 주 벡터 정보로 'augmentation' 한다고 한다.
city_plus_state = []
for c, state, st in zip(kr.city, kr.state, kr.st):
if c not in vocab:
continue
row = []
if state in vocab:
try:
row.extend(wv[c]+wv[state])
except KeyError:
continue
else:
try:
row.extend(wv[c]+wv[st])
except KeyError:
continue
city_plus_state.append(row)
kr_300D = pd.DataFrame(city_plus_state)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
kr_2D = pca.fit_transform(kr_300D.iloc[:,:300])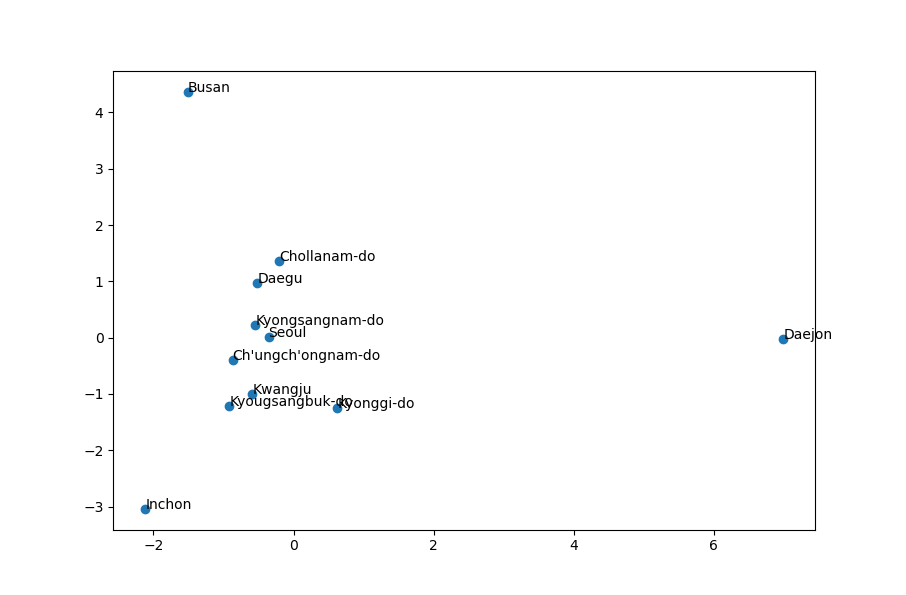
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [CNN] 합성곱 신경망 (feat. Learning Word Vectors for Sentiment Analysis) (0) | 2021.03.13 |
|---|---|
| [doc2vec] 문서 유사도 추정 (0) | 2021.03.09 |
| Word2vec Vs GloVe (0) | 2021.03.08 |
| BERT (Deep Bidirectional Transformers for Language Understanding) (0) | 2021.03.03 |
| [Word2Vec] 구현 패키지 사용 (4) | 2021.03.02 |
nlpia를 통해 미리 훈련된 구글 뉴스 word2vec 모형을 받아온다. 단어 수 30만개
import os
from nlpia.loaders import get_data
from gensim.models.word2vec import Word2VecKeyedVectors
wv = get_data('word2vec')
len(wv.vocab) #3000000
n-gram 단어들이 '_' 문자로 연결된 것을 확인 할 수 있다.
import pandas as pd
from tqdm import tqdm
vocab = pd.Series(wv.vocab)
vocab.iloc[1000000:1000006]
# Starwood_Hotels_HOT Vocab(count:2000000, index:1000000)
# Tammy_Kilborn Vocab(count:1999999, index:1000001)
# aortic_aneurism Vocab(count:1999998, index:1000002)
# Spragins_Hall Vocab(count:1999997, index:1000003)
# Ed_Iacobucci Vocab(count:1999996, index:1000004)
# Seilheimer Vocab(count:1999995, index:1000005)'Seilheimer' 단어 벡터는 아래 와 같이 확인 할 수있다. 300개의 단어 벡터를 보여준다.
wv['Seilheimer']
# array([ 0.10107422, 0.08935547, -0.15429688, -0.04956055, -0.00436401,
# -0.06079102, -0.07421875, -0.06005859, -0.06079102, -0.02758789,
# 0.03015137, -0.05712891, -0.07617188, 0.05786133, -0.05249023,
# .....dtype=float32)
wv['Seilheimer'].shape # (300,)'Seilheimer' 과 'Seil'의 거리를 확인해 보았다.
유클리드 거리, 코사인 유사도, 코사인 거리 확인
2.5733225import numpy as np
np.linalg.norm(wv['Seilheimer'] - wv['Seil']) # 2.5733225
cos_similarity = np.dot(wv['Seilheimer'],wv['Seil']) / (np.linalg.norm(wv['Seilheimer'])*np.linalg.norm(wv['Seil']))
cos_similarity # 0.35953805
1 - cos_similarity # 0.6404619514942169'Seilheimer' 과 'Seil'의 거리는 별 차이가 없었다. 'Seilheimer' 과 'person'의 단어 거리를 보면 'Seilheimer'라는 단어가 사람이랑 높게 연관되어 있음을 알 수 있다.
np.linalg.norm(wv['Seilheimer'] - wv['person'])
cos_similarity = np.dot(wv['Seilheimer'],wv['person']) / (np.linalg.norm(wv['Seilheimer'])*np.linalg.norm(wv['person']))
cos_similarity # 0.039810065
1 - cos_similarity # 0.96cities = get_data('cities')
cities.head(1).T
# geonameid 3039154
# name El Tarter
# asciiname El Tarter
# alternatenames Ehl Tarter,Эл Тартер
# latitude 42.5795
# longitude 1.65362
# feature_class P
# feature_code PPL
# country_code AD
# cc2 NaN
# admin1_code 02
# admin2_code NaN
# admin3_code NaN
# admin4_code NaN
# population 1052
# elevation NaN
# dem 1721
# timezone Europe/Andorra
# modification_date 2012-11-03# Geocities의 자료를 통해 지도위의 위치와 각 지방간의 거리를 비교하기
cities = get_data('cities')
cities.head(1).T
# geonameid 3039154
# name El Tarter
# asciiname El Tarter
# alternatenames Ehl Tarter,Эл Тартер
# latitude 42.5795
# longitude 1.65362
# feature_class P
# feature_code PPL
# country_code AD
# cc2 NaN
# admin1_code 02
# admin2_code NaN
# admin3_code NaN
# admin4_code NaN
# population 1052
# elevation NaN
# dem 1721
# timezone Europe/Andorra
# modification_date 2012-11-03한국의 지방 정보를 다 가져온다.
그 후 st 지방의 고유 번호를 통해 state 데이터와 mapping 시켜 데이터를 통합니다.
kr = cities[(cities.country_code == "KR") & (cities.admin1_code.notnull())].copy()
# name asciiname ... timezone modification_date
# geonameid ...
# 1832015 Heunghae Heunghae ... Asia/Seoul 2016-09-09
# 1832215 Yeonil Yeonil ... Asia/Seoul 2016-09-09
# 1832257 Neietsu Neietsu ... Asia/Seoul 2012-01-18
# 1832384 Eisen Eisen ... Asia/Seoul 2012-01-18
# 1832501 Reiko Reiko ... Asia/Seoul 2012-01-18
# ... ... ... ... ...
# 9887776 Dongmyeon Dongmyeon ... Asia/Seoul 2015-01-08
# 10913399 Yeonsan Yeonsan ... Asia/Seoul 2015-11-10
# 11124627 Oepo Oepo ... Asia/Seoul 2016-04-12
# 11523293 Sejong Sejong ... Asia/Seoul 2017-04-11
# 11549691 Bupyeong Bupyeong ... Asia/Seoul 2017-05-25
# [175 rows x 18 columns]
# kr = cities[(cities.country_code == "KR")]
# kr = cities[(cities.country_code == "KR") & (cities.admin1_code.notnull())].copy()
# kr
# Out[36]:
# name asciiname ... timezone modification_date
# geonameid ...
# 1832015 Heunghae Heunghae ... Asia/Seoul 2016-09-09
# 1832215 Yeonil Yeonil ... Asia/Seoul 2016-09-09
# 1832257 Neietsu Neietsu ... Asia/Seoul 2012-01-18
# 1832384 Eisen Eisen ... Asia/Seoul 2012-01-18
# 1832501 Reiko Reiko ... Asia/Seoul 2012-01-18
# ... ... ... ... ...
# 9887776 Dongmyeon Dongmyeon ... Asia/Seoul 2015-01-08
# 10913399 Yeonsan Yeonsan ... Asia/Seoul 2015-11-10
# 11124627 Oepo Oepo ... Asia/Seoul 2016-04-12
# 11523293 Sejong Sejong ... Asia/Seoul 2017-04-11
# 11549691 Bupyeong Bupyeong ... Asia/Seoul 2017-05-25
# [175 rows x 18 columns]
states = pd.read_csv('states.csv',header=True)
states
states.Abbreviation[0] = '01'
states.Abbreviation[1] = '03'
states.Abbreviation[2] = '05'
states.Abbreviation[3] = '06'
states
states = dict(zip(states.Abbreviation, states.State))
kr['city']= kr.name.copy()
kr['st'] = kr.admin1_code.copy()
kr['state'] = kr.st.map(states)
kr[kr.columns[-3:]].head()
vocab = pd.np.concatenate([kr.city,kr.st,kr.state])
vocab = np.array([word for word in vocab if word in wv.wv])
vocab[:5] #array(['Eisen', 'Reiko', 'Eisen', 'Yeoncheon', 'Yeoju'], dtype='<U9')
# 주 단어 벡터로 도시 단어 벡터 증강
한국에는 광주광역시와 경기도 광주시가 있다. 이처럼 그 도시가 속한 주를 연결하는 것이 도시 벡터를 해당 주 벡터 정보로 'augmentation' 한다고 한다.
city_plus_state = []
for c, state, st in zip(kr.city, kr.state, kr.st):
if c not in vocab:
continue
row = []
if state in vocab:
try:
row.extend(wv[c]+wv[state])
except KeyError:
continue
else:
try:
row.extend(wv[c]+wv[st])
except KeyError:
continue
city_plus_state.append(row)
kr_300D = pd.DataFrame(city_plus_state)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
kr_2D = pca.fit_transform(kr_300D.iloc[:,:300])'🗣️ Natural Language Processing' 카테고리의 다른 글
| [CNN] 합성곱 신경망 (feat. Learning Word Vectors for Sentiment Analysis) (0) | 2021.03.13 |
|---|---|
| [doc2vec] 문서 유사도 추정 (0) | 2021.03.09 |
| Word2vec Vs GloVe (0) | 2021.03.08 |
| BERT (Deep Bidirectional Transformers for Language Understanding) (0) | 2021.03.03 |
| [Word2Vec] 구현 패키지 사용 (4) | 2021.03.02 |