
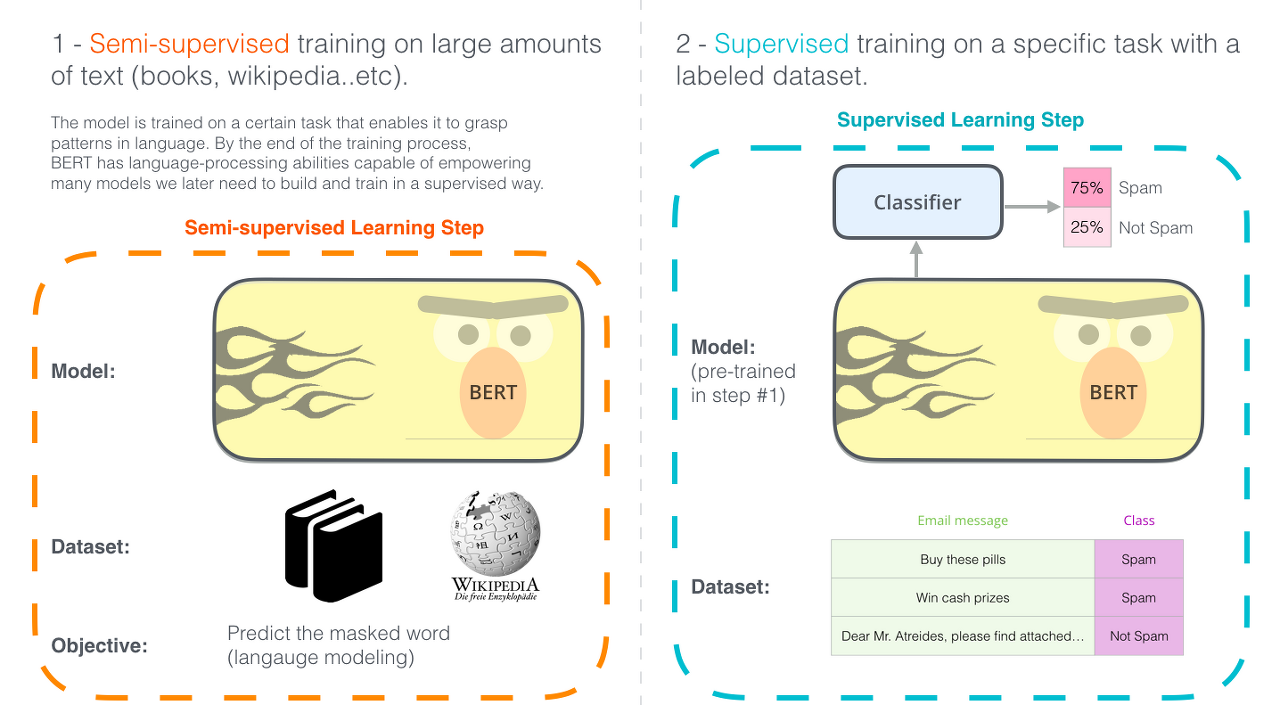
BERT는 2018년 구글에서 공개한 논문인 BERT: Deep Bidirectional Transformers for Language Understanding에서 제안된 모델로서 비지도 학습을 통해 딥러닝 모델 들어가기 전에 사전 학습을 진행하는 모델이다.


버트의 특징은 다른 사전 모델 기법인 GPT나 ELMo와 다르게 양방향성을 가지고 학습한다. 마스크 언어 모델을 학습하기 때문이다. 버트는 word2vec의 CBOW 처럼 주변단어를 통해 의미를 파악한다.
마스크 언어 모델이란 양방향성을 가지고 언어 모델을 학습하기 위한 방법으로 입력 문장이 주어진 경우 일부 단어들을 마스킹해서 해당 단어를 모델이 알지 못하도록 가린다. 그 후 모델을 통해 마스킹된 단어가 무엇인지 예측한다. 입력값으로 들어간 문장 안의 다른 단어들을 통해 마스킹된 단어를 예측하도록한다. (CBOW와 비슷) 이때 양방향성이 생긴다는 것은 기존 언어 모델과의 차이에서 발생하는 현상이다. 기존의 대부분의 언어 모델을 학습한다는 것은 앞의 단어들을 사용해 다음 단어를 예측하는 방식으로 이뤄지는데 버트의 경우 특정 단어를 가리고 앞뒤 상관없이 문장 안의 단어들을 모두 사용해서 가려진 단어들을 예측하게 함으로써 양방향의 단어들을 모두 사용하게 한다.

다음 문장 예측은 입력으로 주어진 두 문장이 이어진 문장인지 아닌지를 데이터의 50% 확률로 이어서 전체 텍스를 모델의 입력값으로 넣고 나머지 50%의 확률로 임의의 다른 문서의 문장을 기존 문장과 함께 모델의 입력값으로 한다.
다음 문장이 맞는 지에 대한 여부 표시로 [CLS]라는 특수 토큰을 입력값 앞에 사용한다. 추가로 두개의 문장을 함께 입력으로 넣기 때문에 모델이 각 문장을 구분할 수 있 도록 [SEP]라는 특수 토큰 또한 각 문장이 끝나는 지점에 넣어 준다. 특수 토큰을 사용하므로 버트의 두 문장같의 관계를 예측력이 높아진다. 사전 학습을 통해 마스크를 예측하고 그 결과 두 문장의 관계를 파악해 이어졌는지 아닌지를 파악한다.
bert 모델 미세 조정(Fine-tuning)
사전 학습한 버트 모델을 하위 문제에 미세 조정함으로써 사전 학습 없이 학습한 모델보다 더 좋은 성능을 낼 수 있다.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [Word2vec] 단어 관계 시각화 (0) | 2021.03.08 |
|---|---|
| Word2vec Vs GloVe (0) | 2021.03.08 |
| [Word2Vec] 구현 패키지 사용 (4) | 2021.03.02 |
| [Word2Vec] 계산 (0) | 2021.03.01 |
| [Word2Vec] 연속 단어 모음 (0) | 2021.03.01 |
BERT는 2018년 구글에서 공개한 논문인 BERT: Deep Bidirectional Transformers for Language Understanding에서 제안된 모델로서 비지도 학습을 통해 딥러닝 모델 들어가기 전에 사전 학습을 진행하는 모델이다.
버트의 특징은 다른 사전 모델 기법인 GPT나 ELMo와 다르게 양방향성을 가지고 학습한다. 마스크 언어 모델을 학습하기 때문이다. 버트는 word2vec의 CBOW 처럼 주변단어를 통해 의미를 파악한다.
마스크 언어 모델이란 양방향성을 가지고 언어 모델을 학습하기 위한 방법으로 입력 문장이 주어진 경우 일부 단어들을 마스킹해서 해당 단어를 모델이 알지 못하도록 가린다. 그 후 모델을 통해 마스킹된 단어가 무엇인지 예측한다. 입력값으로 들어간 문장 안의 다른 단어들을 통해 마스킹된 단어를 예측하도록한다. (CBOW와 비슷) 이때 양방향성이 생긴다는 것은 기존 언어 모델과의 차이에서 발생하는 현상이다. 기존의 대부분의 언어 모델을 학습한다는 것은 앞의 단어들을 사용해 다음 단어를 예측하는 방식으로 이뤄지는데 버트의 경우 특정 단어를 가리고 앞뒤 상관없이 문장 안의 단어들을 모두 사용해서 가려진 단어들을 예측하게 함으로써 양방향의 단어들을 모두 사용하게 한다.
다음 문장 예측은 입력으로 주어진 두 문장이 이어진 문장인지 아닌지를 데이터의 50% 확률로 이어서 전체 텍스를 모델의 입력값으로 넣고 나머지 50%의 확률로 임의의 다른 문서의 문장을 기존 문장과 함께 모델의 입력값으로 한다.
다음 문장이 맞는 지에 대한 여부 표시로 [CLS]라는 특수 토큰을 입력값 앞에 사용한다. 추가로 두개의 문장을 함께 입력으로 넣기 때문에 모델이 각 문장을 구분할 수 있 도록 [SEP]라는 특수 토큰 또한 각 문장이 끝나는 지점에 넣어 준다. 특수 토큰을 사용하므로 버트의 두 문장같의 관계를 예측력이 높아진다. 사전 학습을 통해 마스크를 예측하고 그 결과 두 문장의 관계를 파악해 이어졌는지 아닌지를 파악한다.
bert 모델 미세 조정(Fine-tuning)
사전 학습한 버트 모델을 하위 문제에 미세 조정함으로써 사전 학습 없이 학습한 모델보다 더 좋은 성능을 낼 수 있다.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [Word2vec] 단어 관계 시각화 (0) | 2021.03.08 |
|---|---|
| Word2vec Vs GloVe (0) | 2021.03.08 |
| [Word2Vec] 구현 패키지 사용 (4) | 2021.03.02 |
| [Word2Vec] 계산 (0) | 2021.03.01 |
| [Word2Vec] 연속 단어 모음 (0) | 2021.03.01 |