
BACKGROUND & STATE OF THE ART
자연어 처리(NLP) 영역에서 언어 모델은 과거 입력 토큰의 시퀀스를 사용하여 토큰(예: 단어)을 생성하는 데 사용됩니다. 대용량 언어 모델(Large Language Models, LLMs)은 이 공간에서의 최신 딥러닝 혁신으로, 인간과 유사한 방식으로 텍스트를 생성하기 위해 설계되었습니다. 이러한 모델은 일반적으로 입력 토큰의 큰 시퀀스에 대한 주의를 개선하기 위해 transformer를 사용합니다.
LLaMA는 1조 개 이상의 토큰으로 훈련된 강력한 기반 LLM으로, Meta AI에서 오픈 소스로 제공됩니다. LLaMA는 GPT-3, Chinchilla, PaLM과 같은 많은 최고의 모델과 경쟁력을 가지고 있습니다.
LLaMA (13B)는 GPT-3 (175B)보다 뛰어난 성능을 보여주며, 각 모델 파라미터에서 더 많은 계산을 추출할 수 있는 능력을 갖추고 있습니다.
이 블로그 포스트에서는 LLaMA를 예제 모델로 사용하여 PyTorch/XLA가 LLM 추론에 어떻게 사용되는지의 기능을 보여줍니다. 여기에서 설명하는 계산 기술과 최적화 기술이 Google Cloud TPU v4 (v4-16)에서 구동되는 65B 파라미터 LLaMA 모델의 추론 대기 시간을 6.4배 개선하는 방법에 대해 논의합니다.
MODEL OVERVIEW
우리는 PyTorch/XLA의 성능 기능을 Meta의 최신 LLM인 LLaMA에서 보여줍니다. 우리는 일련의 일반적인 LLaMA 구성에 대한 성능 최적화를 시연합니다. 아래에서 언급된 175B 파라미터 모델 구성은 공개 도메인에 없습니다. 우리는 아래에서 언급된 175B 파라미터 모델에 대해 LLaMA 코드 기반에 OPT 175B 모델 구성을 적용합니다. 그 외의 경우에는 모든 구성에서 max_seq_len=256 및 dtype=bfloat16을 사용하여 가중치와 활성화를 설정합니다.
Table 1: 이 문서에서 탐색한 모델 구성
| LLaMA | 모델 하이퍼 파라미터 |
|---|---|
| 7B | 4,096 |
| 33B | 6,656 |
| 65B | 8,192 |
| 175B | 12,288 |
PERFORMANCE CHALLENGES OF LLMS
LLM은 컴파일러 최적화에 어려움을 줄 수 있는 몇 가지 특성을 갖고 있습니다. (a) LLM은 이전 토큰을 기반으로 다음 토큰을 생성하기 위해 자기회귀 디코딩을 사용합니다. 이는 프롬프트 텐서와 코치가 동적인 형태를 갖는다는 것을 의미합니다. (b) LLM은 입력 텐서 모양의 변경으로 인한 다시 컴파일을 유발하지 않고도 가변적인 입력 프롬프트 길이로 작동해야 합니다. 입력 텐서는 적절하게 버킷화되고 패딩되어 다시 컴파일을 피해야 합니다. (c) LLM은 종종 단일 TPU(또는 GPU) 장치가 지원할 수 있는 메모리보다 많은 메모리가 필요합니다. 모델 샤딩 방식은 분산 컴퓨팅 아키텍처에 모델을 맞추기 위해 필요합니다. 예를 들어, 65B 파라미터를 가진 LLaMA 모델은 8개의 A100 GPU와 비교 가능한 v4-16 클라우드 TPU에 맞출 수 있습니다. (d) LLM을 운영 환경에서 실행하는 것은 비용이 많이 들 수 있습니다. 총 소유 비용 당 성능(Perf/TCO)을 향상시키는 한 가지 방법은 양자화입니다. 양자화는 하드웨어 요구 사항을 줄일 수 있습니다.
INFERENCE TECH STACK IN PYTORCH/XLA
TorchDynamo, PjRt, OpenXLA 및 여러 모델 병렬화 기법. TorchDynamo는 런타임에서 추적 오버헤드를 제거하며, PjRt는 효율적인 호스트-장치 통신을 가능하게 합니다. PyTorch/XLA 추적 가능한 컬렉티브를 통해 LLaMA에서 모델 및 데이터 병렬화를 가능하게 하는 PyTorch/XLA 추적 가능한 컬렉티브를 사용합니다. 우리의 결과를 시도하려면, 우리의 커스텀 torch, torch-xla 휠을 사용하여 LLaMA 추론 솔루션을 재현해 보십시오. PyTorch/XLA 2.1은 이 게시물에서 논의하는 기능을 기본적으로 지원할 것입니다.
PARALLEL COMPUTING
FairScale Sharding
LLaMA는 FairScale 모델 샤딩 API (fairscale.nn.model_parallel.layers)를 사용합니다. 우리는 가속기 간의 프로그램 상태(활성화 등)를 통신하기 위해 모든 리듀스와 같은 PyTorch/XLA 통신 컬렉티브(Collective Communication) 연산을 사용하여 이 API의 동등한 표현을 구축했습니다. TorchDynamo는 현재 CC 연산을 완전히 지원하지 않습니다(즉, 추적 가능한 컬렉티브를 지원하지 않음). 이러한 지원이 없으면 TorchDynamo FX 그래프는 모든 디바이스 통신마다(즉, 모델 레이어마다) 잘릴 것입니다. 그래프 잘림은 XLA 컴파일러가 전체 그래프 최적화 기회를 잃어 성능 손실을 야기합니다. 이를 해결하기 위해 기존의 CC API에 디스패처 컬렉티브를 통합함으로써 PyTorch/XLA 추적 가능한 컬렉티브를 제공합니다. 차이점은 PyTorch/XLA의 지연 실행 특성으로 인해 컬렉티브 이후에 c10d.wait() 연산을 삽입할 필요가 없다는 것입니다. 추론 가능한 컬렉티브를 지원함으로써 PyTorch/XLA는 TorchDynamo에서 단일 FX 그래프 생성을 가능하게 합니다.
AUTOREGRESSIVE DECODING ON PYTORCH/XLA
LLM은 이전 단어를 prompt로 사용하여 다음 토큰을 예측하기 위해 autoregressive decoding을 사용합니다. Autoregressive decoding은 제한 없는 동적 형태 문제를 야기하며, 이는 모든 prompt의 재컴파일을 초래합니다. 저희는 LLaMA autoregressive decoder를 최적화하여 고정된 형태로 작동하도록 하여 KV-cache, 출력 시퀀스 및 어텐션 마스크를 효율적으로 업데이트하고자 했습니다. 패딩, 마스킹 및 인덱스 작업의 조합을 통해 너무 많은 그래프 재컴파일을 피하고 효율적인 autoregressive decoding을 달성했습니다.
KV-Cache 최적화
LLaMA는 KV-cache를 사용하여 autoregressive decoding을 구현합니다. 생성된 각 토큰마다 KV-cache는 각 Transformer 레이어의 어텐션 키/값 활성화를 저장합니다. 따라서 새로운 토큰을 디코딩할 때 이전 토큰의 키/값은 다시 계산할 필요가 없습니다.
LLaMA에서는 KV-cache 텐서 슬라이스를 원래 자리에 업데이트하므로 토큰이 생성될 때마다 재컴파일 이벤트가 발생합니다. 이 문제를 해결하기 위해 인덱스 텐서와 tensor.index_copy() 연산을 사용하여 원래 자리에 슬라이스 업데이트를 대체합니다. 어텐션 마스크와 출력 시퀀스도 동일한 최적화를 받습니다.
INPUT PROMPT OPTIMIZATION
LLM 응용 프로그램에서 가변 길이의 입력 프롬프트는 일반적입니다. 이 속성은 입력 텐서의 형태 동적성을 야기하고, 이에 따라 재컴파일 이벤트가 발생합니다. KV-cache를 채우기 위해 프롬프트를 처리할 때 (a) 입력 프롬프트를 토큰별로 처리하거나 (b) 전체 프롬프트를 한 번에 처리합니다. 각 방법의 장단점은 다음과 같습니다.
1개의 그래프를 미리 컴파일하고 프롬프트를 토큰별로 처리함
장점: 워밍업 동안 1개의 그래프만 컴파일됨
단점: 입력 프롬프트 길이 L을 처리하는 데 O(L)이 걸림 - 긴 프롬프트의 단점1에서 max_seq_len (예: 2,048)까지의 입력 길이로 모든 그래프를 미리 컴파일함
장점: 워밍업 시간 동안 max_seq_len 그래프를 미리 컴파일하고 캐시함
단점: 입력을 처리하는 데 1개의 그래프 실행이 필요함저희는 두 가지 대안 사이에서 균형을 맞추기 위해 프롬프트 길이 버킷화를 도입했습니다. 우리는 오름차순으로 정렬된 버킷 크기 집합 (b0, b1, b2, ..., bB-1)를 정의하고, 이러한 버킷 값 (G0, G1, G2, ..., GB-1)에 따라 입력 크기에 대한 프로그램 그래프를 미리 컴파일합니다. B는 버킷의 수입니다. 주어진 입력 프롬프트에 대해 프롬프트 길이를 가장 가까운 버킷 값 bn으로 반올림하고 시퀀스를 패딩한 다음 Gn을 사용하여 프롬프트를 한 번에 처리합니다. 패딩 토큰의 계산은 삭제됩니다. 가장 큰 버킷 크기보다 큰 프롬프트의 경우, 섹션별로 처리합니다.
최적의 버킷 크기는 대상 응용 프로그램에서 프롬프트 길이 분포에 의해 결정되어야 합니다. 여기에서는 버킷 길이를 128, 256, 384, 512로 채택했습니다. 최대 2,047 토큰을 포함하는 모든 입력 프롬프트는 최대 4개의 그래프 실행이 필요합니다. 예를 들어, 1,500의 입력 프롬프트와 256의 생성 길이를 가진 경우, 260개의 그래프 실행이 필요합니다 - 입력을 처리하기 위한 4개와 출력을 생성하기 위한 256개의 그래프 실행입니다.
QUANTIZATION
양자화는 값을 표현하는 데 필요한 비트 수를 줄이는 것으로, 여러 가속기 노드 간 데이터 통신 대역폭을 줄이고 특정 모델 크기를 처리하는 데 필요한 하드웨어 요구 사항을 낮춥니다.
일반적으로 BF16 가중치로는 175B 매개 변수 모델이 약 351GB의 메모리를 사용하며, 따라서 모델을 수용하기 위해 v4-32 인스턴스가 필요합니다. 가중치를 INT8로 양자화함으로써 모델 크기를 대략 50% 줄여 v4-16 인스턴스에서 실행할 수 있게 되었습니다. LLaMA는 모델 활성화를 샤딩하므로, 양자화는 무시할 수 있는 통신 이득을 제공합니다.
저희 실험에서는 선형 레이어를 양자화했습니다. LLaMA 모델 체크포인트는 공개적으로 사용할 수 없으며, 우리의 목표는 성능을 평가하는 것이므로 양자화된 모델은 임의의 가중치로 초기화되었습니다. AWQ 및 Integer or Floating Point?와 같은 최근 문헌은 다양한 저비트 양자화 체계에서 LLaMA의 성능 특성에 대한 통찰력을 제공합니다.
Effect of Batch Size on Quantization Performance
모델 배치 크기 (BS) > 1일 때 TPU v4는 행렬 곱셈 유닛 (MXU)에서 matmul을 실행합니다. BS = 1인 경우 matmul은 벡터 프로세서 유닛 (VPU)에서 실행됩니다. MXU가 VPU보다 효율적이므로 INT8 양자화는 BS > 1일 때 성능을 향상시킵니다. 자세한 내용은 성능 분석 섹션을 참조하십시오.
OP SUPPORT
가끔씩 새로운 모델은 컴파일을 위해 PyTorch/XLA가 지원하는 연산 집합을 확장해야 하는 새로운 수학 연산을 소개합니다. LLaMA의 경우, multinomial을 지원했습니다.
METHODOLOGY
LLaMA는 LazyTensorCore에서 PyTorch/XLA를 사용하여 기본 구성으로 작동합니다. 모든 실험은 256 길이의 입력 프롬프트를 가정합니다. 공개적으로 사용 가능한 모델 체크포인트가 없으므로, 우리는 이 추론 스택 최적화 작업을 위해 임의의 텐서 초기화를 사용했습니다. 여기서는 모델 체크포인트가 지연 시간 결과에 영향을 미치지 않을 것으로 예상됩니다.
Model Sizing
N이 파라미터 수, dimensions이 hidden size, n_layers가 레이어 수, n_heads가 어텐션 헤드 수라고 가정할 때, 아래의 식을 사용하여 모델의 크기를 근사할 수 있습니다. 자세한 내용은 모델 개요 섹션을 참조하십시오.
n_heads는 N에 영향을 주지 않지만, 오픈 소스 모델 구성에 대해서는 다음 식이 성립합니다.
Cache Sizing
모델 파라미터와 어텐션 블록의 캐시 레이어는 메모리 소비에 영향을 줍니다. 이 섹션의 메모리 소비 계산은 BF16 가중치를 사용하는 기본 LLaMA 모델을 기반으로 합니다.
캐시 레이어의 크기는 cache_size = max_batch_size * max_seq_len * dimensions로 계산됩니다. 다음 계산에서 예제 구성으로 max_batch_size = 1 및 max_seq_len = 256을 사용합니다. 각 어텐션 블록에는 2개의 캐시 레이어가 있습니다. 따라서 총 LLaMA 캐시 크기(바이트)는 total_cache_size = n_layers * 2 * cache_size * (2 바이트)입니다.
TPU v4 Hardware Sizing
각 TPU v4 칩은 32GB의 사용 가능한 고대역폭 메모리(HBM)를 가지고 있습니다. 표 2에는 메모리 소비 및 LLaMA 모델을 보유하기 위해 필요한 TPU 칩 수에 대한 세부 정보가 있습니다.
표 2: LLaMA TPU v4 HBM 요구 사항 (즉, TPU v4 칩 요구 사항)
파라미터
| 파라미터 | (MB) | 캐시 (MB) | 전체 (GB) | 최소 TPU v4 칩 수 |
|---|---|---|---|---|
| 7B | 14,000 | 134 | 14.128 | 1 |
| 33B | 66,000 | 408 | 66.41 | 3 |
| 65B | 130,000 | 671 | 130.67 | 5 |
| 175B | 350,000 | 1,208 | 351.21 | 11 |
Metrics
아래는 추론 속도를 측정하는 유용한 메트릭스입니다. T는 총 시간, B는 배치 크기, L은 디코딩된 시퀀스 길이를 가정합니다.
Latency Definition
지연 시간은 타깃 길이 L에서 디코딩된 결과를 얻기까지 걸리는 시간으로, 배치 크기 B와는 상관없이 사용자가 생성 모델의 응답을 받기까지 기다려야 하는 시간을 나타냅니다.
Per-token latency
자기 회귀 디코딩의 한 단계는 배치의 각 샘플에 대해 토큰을 생성합니다. 토큰당 지연 시간은 해당 한 단계에 대한 평균 시간입니다.
Throughput
처리량은 단위 시간당 생성된 토큰 수를 측정합니다. 온라인 서빙을 평가하는 데 유용한 메트릭스는 아니지만 배치 처리 속도를 측정하는 데 유용합니다.
지연 시간과 처리량을 혼합하는 T / (B * L)과 같은 메트릭스는 혼란과 오해를 줄이기 위해 피하는 것이 좋습니다.
RESULTS
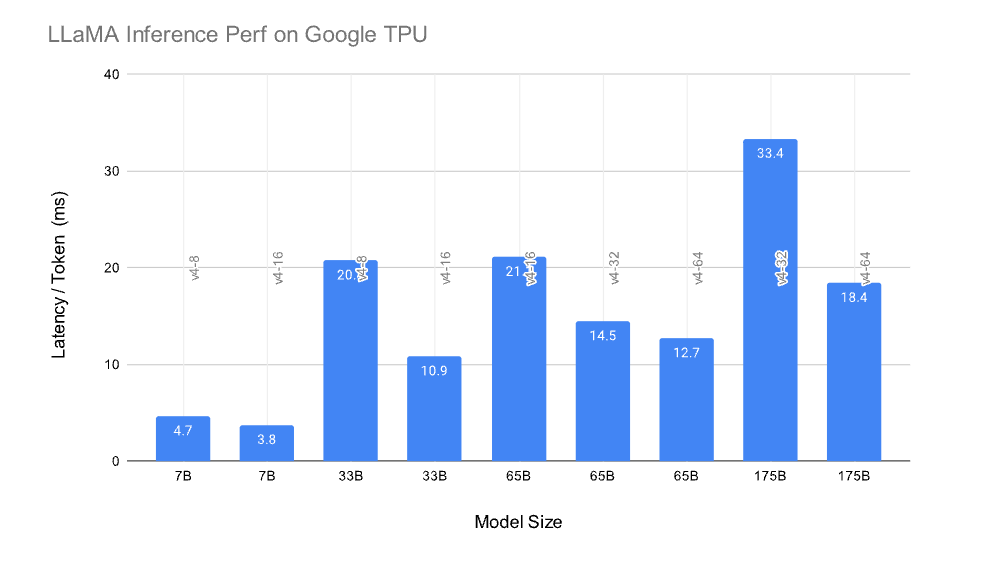
Figure 1은 LLaMA 7B에서 175B 모델에 대한 지연 시간/토큰 결과를 보여줍니다. 각 경우 모델은 다양한 TPU v4 구성에서 실행됩니다. 예를 들어, LLaMA 7B는 v4-8에서는 4.7ms/토큰, v4-16에서는 3.8ms/토큰을 보여줍니다. 더 많은 비교를 위해서는 HuggingFace LLM 성능 리더보드를 방문하십시오.
이 블로그 포스트에서 논의된 기능이 없는 경우, LLaMA 65B는 여기서 얻은 14.5ms/토큰 대신 120ms/토큰으로 v4-32에서 실행되어 8.3배의 가속을 제공합니다. 이전에 언급한 대로, 개발자는 LLaMA 추론 결과를 잠금 해제하는 사용자 정의 torch, torch-xla 휠을 시도할 것을 권장합니다.
Figure 1: TPU v4 하드웨어에서의 LLaMA 추론 성능
PyTorch/XLA:GPU 성능은 PyTorch:GPU eager보다 우수하며 PyTorch Inductor와 유사합니다. PyTorch/XLA:TPU 성능은 PyTorch/XLA:GPU보다 우수합니다. 가까운 미래에 XLA:GPU는 XLA:TPU와 동등한 최적화를 제공할 것입니다. 단일 A100 구성은 LLaMA 7B만 맞습니다. 8-A100은 LLaMA 175B에 맞지 않습니다.
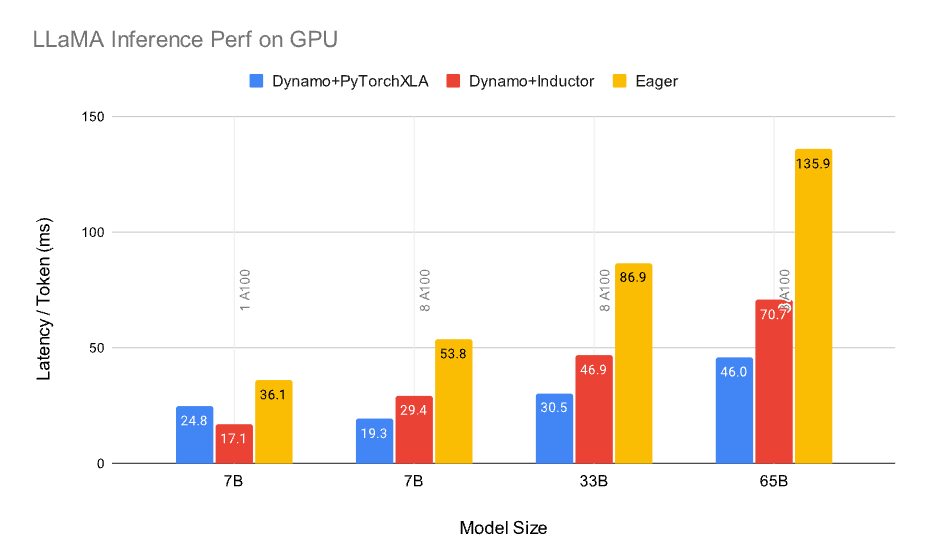
Figure 2: GPU A100 하드웨어에서의 LLaMA 추론 성능
배치 크기가 증가함에 따라 토큰당 지연 시간이 비선형적으로 증가하는 것을 관찰합니다. 이는 하드웨어 이용률과 지연 시간 사이의 트레이드오프를 강조합니다.
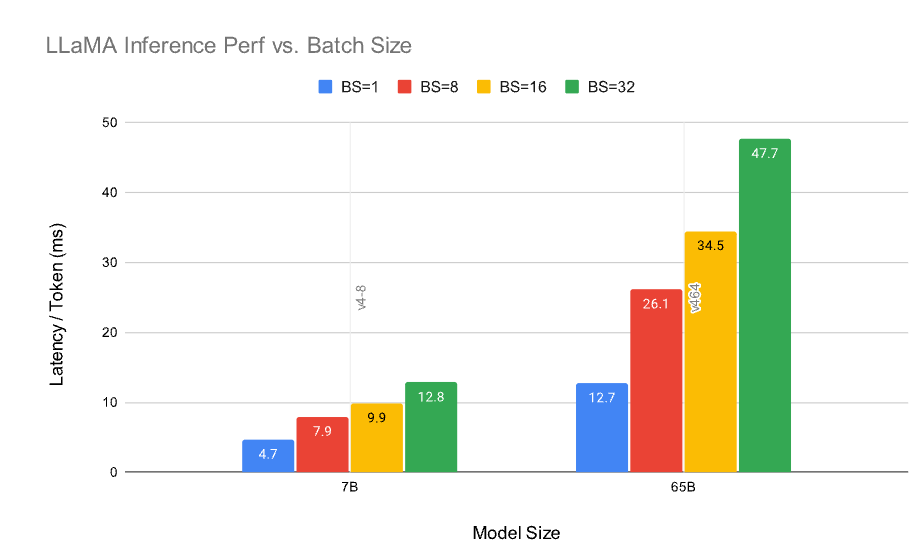
Figure 3: 다른 배치 크기에 따른 LLaMA 추론 성능
저희의 연구 결과, 최대 시퀀스 입력 길이(max_seq_len)가 추론 지연 시간에 미치는 영향은 비교적 미미하다고 나타났습니다. 이는 토큰 생성의 순차적이고 반복적인 특성에 기인할 수 있습니다. 성능의 작은 차이는 저장소 크기가 증가함에 따라 KV 캐시 액세스 지연 시간이 변경되기 때문일 수 있습니다.
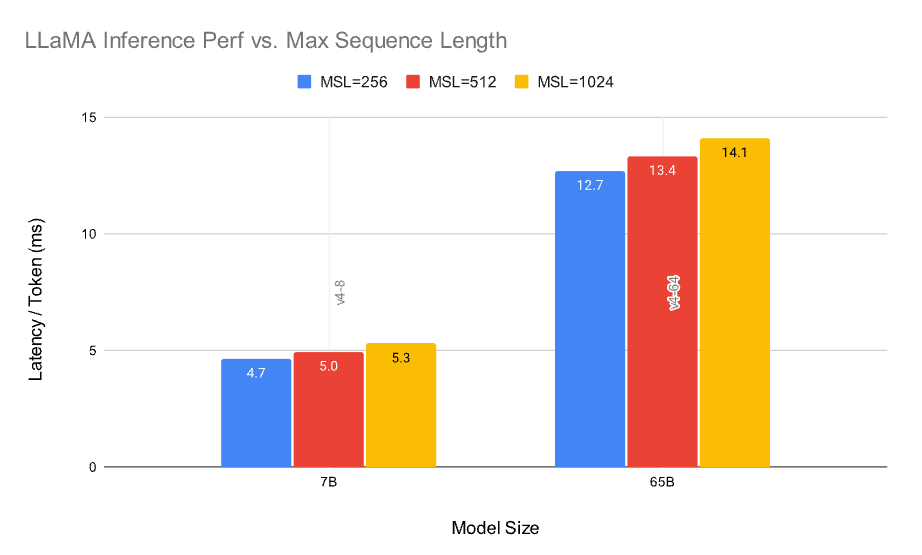
Figure 4: 다른 프롬프트 길이에 따른 LLaMA 추론 성능
LLM은 종종 메모리 바운드 애플리케이션입니다. 따라서 모델 파라미터를 양자화함으로써 시간 단위당 MXU 당 더 큰 텐서를 로드하고 실행할 수 있습니다(HBM ⇒ CMEM 및 CMEM ⇒ MXU 데이터 이동). Figure 5는 INT8 가중치만 양자화하는 것이 주어진 하드웨어에서 더 큰 모델을 실행할 수 있도록 1.6배에서 1.9배의 가속을 제공함을 보여줍니다.
BS=1인 경우, INT8 텐서는 MXU보다 작은 VPU로 전송됩니다 (TPU v4 논문 참조). 그렇지 않으면 MXU가 사용됩니다. 결과적으로, BS=1인 경우 양자화 메모리 대역폭 획득은 MXU 이용 불가로 인해 상쇄됩니다. 그러나 BS>1인 경우, 메모리 획득이 양자화된 모델에서 우수한 지연 시간을 제공합니다. 예를 들어, 175B 파라미터 LLaMA의 경우, 양자화된 v4-16과 양자화되지 않은 v4-32는 유사한 성능을 제공합니다. FP8 비교는 PyTorch가 이러한 데이터 형식을 아직 제공하지 않기 때문에 제공하지 않습니다.
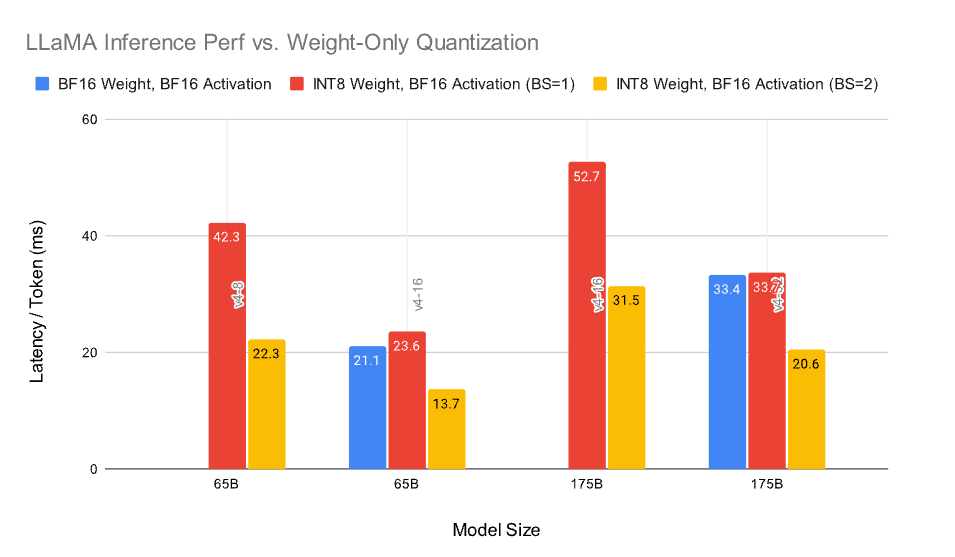
Figure 5: 가중치만 양자화된 LLaMA 추론 성능 대비. 누락된 파란색 막대는 지정된 TPU 하드웨어에 모델 크기가 맞지 않음을 의미합니다.# PyTorch/XLA의 LLaMA 추론 성능
이 문서는 PyTorch/XLA의 LLaMA(Large Language Model Analysis) 추론 성능에 관한 내용을 다룹니다. 아래 그림들은 관련 실험 결과를 시각적으로 보여줍니다.

**Figure 6**: 입력 프롬프트 길이에 따른 LLaMA 추론 성능
이 그림은 입력 프롬프트 길이가 10 토큰에서 1,500 토큰으로 증가함에 따라 PyTorch/XLA의 일관된 성능 우위를 보여줍니다. 이 강력한 스케일링 능력은 실제 응용 프로그램의 다양한 범위에서 최소한의 PyTorch/XLA 재컴파일 이벤트를 가능하게 합니다. 이 실험에서 최대 길이는 2,048이며 최대 생성 길이는 256입니다.
FINAL THOUGHTS
우리는 PyTorch/XLA가 앞으로 어떤 발전을 이룰지에 대해 매우 기대하고 있으며, 커뮤니티에 함께 참여할 것을 초대합니다. PyTorch/XLA는 완전히 오픈 소스로 개발되었습니다. 따라서 이슈를 등록하고 풀 리퀘스트를 제출하며, GitHub로 RFCs를 보내서 공개적으로 협업할 수 있습니다. 또한, TPU와 GPU를 포함한 다양한 XLA 장치에서 PyTorch/XLA를 직접 시도해 볼 수도 있습니다.
감사합니다,
Google의 PyTorch/XLA 팀