
Textbooks Are All You Need
Abstract
우리는 phi-1이라는 새로운 대규모 언어 모델을 소개합니다. 이 모델은 경쟁 모델보다 훨씬 작은 크기를 가지고 있습니다. phi-1은 1.3B 개의 파라미터를 가진 Transformer 기반 모델로, 웹에서 "교과서 수준"의 데이터 (6B 토큰)와 GPT-3.5 (1B 토큰)를 사용하여 8 A100에서 4일 동안 훈련되었습니다. 이 작은 규모에도 불구하고 phi-1은 HumanEval에서 50.6%의 pass@1 정확도와 MBPP에서 55.5%의 정확도를 달성합니다. 또한, 코딩 연습 데이터셋에서 finetuning 단계 이전인 phi-1-base 모델과 같은 파이프라인으로 훈련된 350M 개의 파라미터를 가진 더 작은 모델인 phi-1-small은 여전히 HumanEval에서 45%의 정확도를 달성합니다.
1 Introduction
인공 신경망의 대규모 훈련 기술은 특히 Transformer 아키텍처[VSP+17]의 발견 이후에 놀라운 진전을 이루어 왔습니다. 그러나 이러한 성공의 과학적 배경은 여전히 제한적입니다. Transformers가 소개된 것과 동시에 성능이 어느 정도 예측 가능하게 개선된다는 것이 확인된 것처럼, 성능은 계산 또는 네트워크의 크기를 확장함에 따라 어느 정도 예측 가능하게 개선된다는 것이 일종의 질서로 정리되었습니다[HNA+17]. 이러한 현상은 이제 스케일링 법칙[KMH+20]이라고 불리고 있습니다. 딥 러닝에서 스케일 탐색은 이러한 스케일링 법칙에 따라 이루어졌으며, 이러한 법칙의 변형들의 발견은 성능의 급격한 향상으로 이어졌습니다[HBM+22]. 본 연구에서는 Eldan과 Li [EL23]의 연구를 따라, 데이터의 품질이 개선될수록 어떤 개선이 얻어질 수 있는지 살펴보고자 합니다. 높은 품질의 데이터가 더 좋은 결과를 가져오는 것은 오랫동안 알려져 왔으며, 데이터 정제는 현대적인 데이터셋 생성의 중요한 부분입니다[RSR+20]. 이는 다른 부가효과로써 상대적으로 작은 데이터셋[LYR+23, YGK+23]이나 데이터에 대한 추가적인 패스를 허용할 수 있다는 장점을 가져올 수 있습니다[MRB+23]. TinyStories에 대한 Eldan과 Li의 최근 연구 (신경망에 영어를 가르치기 위해 합성으로 생성된 고품질 데이터셋)는 실제로 고품질 데이터의 효과가 이를 뛰어넘어, 대규모 모델의 성능을 훨씬 더 가볍게 훈련/모델링할 수 있게 할 수 있다는 것을 보였습니다[E23]. 본 연구에서는 고품질 데이터가 대규모 언어 모델(LLM)의 SOTA(State-of-the-Art)를 개선하면서 데이터셋 크기와 훈련 계산을 현저하게 줄일 수 있다는 것을 보여줍니다. 훈련이 덜 필요한 더 작은 모델은 LLM의 환경적 비용을 상당히 줄일 수 있습니다[BGMMS21].
코드를 위해 훈련된 LLMs에 주목하고 특히 [CTJ+21]과 같이 간단한 Python 함수를 독스트링으로 작성합니다. 후자의 연구에서 제안된 평가 벤치마크인 HumanEval은 코드에 대한 LLMs의 성능을 비교하는 데 널리 채택되었습니다. 우리는 고품질 데이터의 효과를 강조하기 위해 phi-1-base 모델의 finetuning 단계 이전인 Eldan과 Li의 초기 연구를 뛰어넘어 대규모 언어 모델의 성능을 보여줍니다. 데이터셋 크기와 훈련 계산을 현저히 줄일 수 있습니다. 더 중요한 것은 훈련이 덜 필요한 작은 모델은 LLMs의 환경적 비용을 상당히 줄일 수 있다는 점입니다[BGMMS21].
1arXiv:2306.11644v1 [cs.CL] 2023년 6월 20일
| 날짜 | 모델 | 모델 크기 | 데이터셋 크기 | HumanEval | MBPP |
|---|---|---|---|---|---|
| 2021년 7월 | Codex-300M [CTJ+21] | 300M | 100B | 13.2% | - |
| 2021년 7월 | Codex-12B [CTJ+21] | 12B | 100B | 28.8% | - |
| 2022년 3월 | CodeGen-Mono-350M [NPH+23] | 350M | 577B | 12.8% | - |
| 2022년 3월 | CodeGen-Mono-16.1B [NPH+23] | 16.1B | 577B | 29.3% | 35.3% |
| 2022년 4월 | PaLM-Coder [CND+22] | 540B | 780B | 35.9% | 47.0% |
| 2022년 9월 | CodeGeeX [ZXZ+23] | 13B | 850B | 22.9% | 24.4% |
| 2022년 11월 | GPT-3.5 [Ope23] | 175B | N.A. | 47% | - |
| 2022년 12월 | SantaCoder [ALK+23] | 1.1B | 236B | 14.0% | 35.0% |
| 2023년 3월 | GPT-4 [Ope23] | N.A. | N.A. | 67% | - |
| 2023년 4월 | Replit [Rep23] | 2.7B | 525B | 21.9% | - |
| 2023년 4월 | Replit-Finetuned [Rep23] | 2.7B | 525B | 30.5% | - |
| 2023년 5월 | CodeGen2-1B [NHX+23] | 1B | N.A. | 10.3% | - |
| 2023년 5월 | CodeGen2-7B [NHX+23] | 7B | N.A. | 19.1% | - |
| 2023년 5월 | StarCoder [LAZ+23] | 15.5B | 1T | 33.6% | 52.7% |
| 2023년 5월 | StarCoder-Prompted [LAZ+23] | 15.5B | 1T | 40.8% | 49.5% |
| 2023년 5월 | PaLM 2-S [ADF+23] | N.A. | N.A. | 37.6% | 50.0% |
| 2023년 5월 | CodeT5+ [WLG+23] | 2B | 52B | 24.2% | - |
| 2023년 5월 | CodeT5+ [WLG+23] | 16B | 52B | 30.9% | - |
| 2023년 5월 | InstructCodeT5+ [WLG+23] | 16B | 52B | 35.0% | - |
| 2023년 6월 | WizardCoder [LXZ+23] | 16B | 1T | 57.3% | 51.8% |
| 2023년 6월 | phi-1 | 1.3B | 7B | 50.6% | 55.5% |
Table 1: 본 논문은 프로그램 합성을 위한 언어 모델(Language Model for Program Synthesis)의 성능을 비교하는 연구입니다. 테이블 1에서는 다양한 모델들의 모델 크기, 데이터셋 크기, HumanEval 및 MBPP 성능을 확인할 수 있습니다.
본 연구에서는 phi-1이라는 1.3B 파라미터 모델을 학습시키고, 약 70B 토큰(7B 토큰 이상의 데이터)에 대해 8번의 학습 과정을 거친 뒤 200M 토큰 미만의 데이터에 대해 finetuning을 수행하였습니다. 텍스트북 퀄리티의 데이터를 학습에 활용하였으며, GPT-3.5로부터 생성된 합성 데이터와 웹 소스로부터 필터링된 데이터를 사용하였습니다. 테이블 1에서 확인할 수 있듯이, 데이터셋 및 모델 크기 측면에서 기존 모델들과 비교했을 때 phi-1은 명확히 작은 편이지만, HumanEval 및 MBPP 성능에서 우수한 결과를 얻었습니다. phi-1은 단일 LLM 생성에 기반한 50.6% pass@1 정확도를 가지며, 이는 자체보고된 최고 성능 중 하나입니다. 섹션 2에서는 학습 과정에 대한 자세한 내용을 제시하고, 이러한 결과를 달성하기 위해 데이터 선택 과정의 중요성에 대해 논의합니다. 또한, 기존 모델들에 비해 훨씬 적은 토큰으로 학습되었음에도 불구하고, phi-1은 신생적인 특성을 보여줍니다. 섹션 3에서는 이러한 신생적인 특성에 대해 논의하며, 특히 파라미터 수가 신생에 핵심적인 역할을 하는지에 대한 가설을 phi-1과 phi-1-small의 출력을 비교하여 확인합니다. 본 섹션에서 사용된 방법론은 LLM의 성능을 평가하기 위해 정적인 벤치마크를 벗어나는 것을 주장한 "Sparks of AGI" 논문 [BCE+23]과 유사합니다. 마지막으로, 섹션 4에서는 모델 평가를 위한 대안적인 벤치마크를 논의하고, 섹션 5에서는 HumanEval에 대한 학습 데이터의 오염 가능성에 대해 연구합니다.
More related works
본 연구는 프로그램 합성을 위해 LLM을 사용하는 최근 프로그램의 일부입니다. 자세한 참고문헌은 [CTJ+21, NPH+22]를 참조하십시오. 또한, 우리의 접근 방식은 이미 존재하는 LLM을 사용하여 새로운 세대의 LLM을 훈련하기 위해 데이터를 합성하는 새로운 트렌드의 일환입니다. [WKM+22, TGZ+23, ...] [MMJ+23, LGK+23, JWJ+23]. "재귀적 학습"이 이러한 결과적인 LLM의 범위를 좁혀질 수 있는지에 대한 논의가 진행 중이다 [SSZ+23, GWS+23] [MMJ+23]는 반대 의견을 제시하고 있다.
이 논문에서는 우리가 설계한 좁은 과제에 초점을 맞추고 있으며, 이 경우에는 후자의 논문에서 주장하는 대로 특정 과제에서 교사 LLM보다 더 나은 성능을 달성하는 것이 가능해 보인다.
2 Training details and the importance of high-quality data
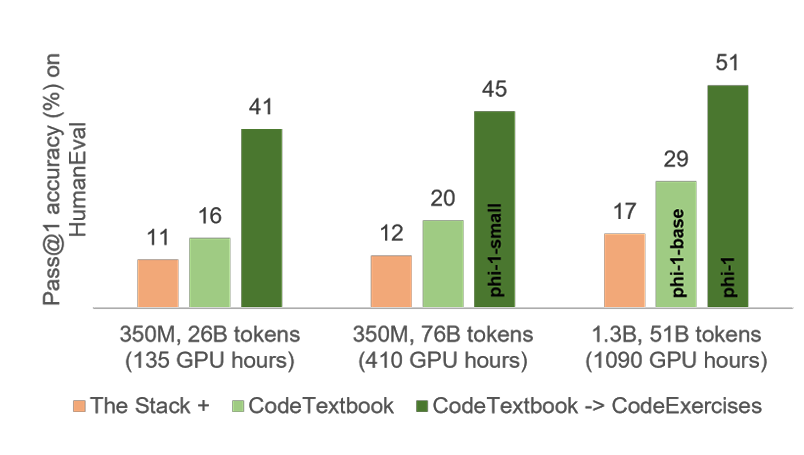
Figure 2.1: HumanEval에서의 Pass@1 정확도 (%). 막대 그래프의 그룹화는 데이터의 계산 시간을 증가시키는 일반적인 스케일링 차원(26B 토큰에서 76B로) 또는 모델의 매개변수 수를 증가시키는 경우(350M에서 1.3B로)에 해당한다. 그룹 내의 각 열은 다른 훈련 데이터 세트에 해당한다:
(A) 첫 번째(주황색) 열은 The Stack의 중복이 제거된 Python 파일 및 1.3B 매개변수 모델용 StackOverflow에서 훈련된 모델의 성능을 나타낸다.
(B) 두 번째(연두색) 열은 우리의 새로운 데이터 세트인 CodeTextbook으로 훈련된 모델의 성능을 나타낸다.
(C) 마지막으로, 세 번째(진한 연두색) 열은 우리의 새로운 CodeExercises 데이터 세트에서 세 번째 열 모델에 대해 finestuning한 결과를 나타낸다.
우리는 단지 1.3B 매개변수 모델로 CodeTextbook 데이터 세트로 훈련된 phi-1-base 모델로서 29%의 HumanEval 성능을 달성했다. 이전에 HumanEval에서 30%에 가까운 성능을 달성한 가장 작은 모델은 2.7B 매개변수를 가진 Replit-Finetuned 모델로, 우리보다 100배 더 많은 교육 토큰으로 훈련되었다. 또한, phi-1을 얻기 위해 CodeExercises 데이터 세트에 대해 finetuning하면 HumanEval에서 51%의 최고 성능을 얻을 뿐만 아니라 추가적인 예상치 못한 코딩 능력을 선보인다.(3절 참조).
논문 제목에서 암시된 대로, 우리의 모델의 핵심 구성 요소는 교과서 수준의 훈련 데이터에 의존한다. 코드 생성을 위해 이전 연구에서 사용된 표준 텍스트 데이터 소스인 The Stack [KLA+22](허용 라이선스를 가진 저장소의 소스 코드를 포함) 및 기타 웹 기반 데이터 세트(StackOverflow 및 CodeContest [LCC+22])는 모델에게 알고리즘적인 추론과 계획을 가르치는 데 최적화되지 않았다고 주장한다.
반면에, 우리의 모델 구조와 훈련 방법은 상당히 전통적이므로(2.3절 참조), 이 절에서는 주로 데이터를 어떻게 선별했는지 설명한다.
표준 코드 데이터 세트[KLA+22, LCC+22]는 다양한 주제와 사용 사례를 다루는 대규모이고 다양한 말뭉치를 형성한다. 그러나 무작위 샘플의 수동 검사를 통해 많은 스니펫이 코딩의 기본 사항을 배우기에는 매우 교육적이지 않고 여러 가지 단점이 있는 것으로 관찰된다:
많은 샘플이 자체 완결되지 않았으며, 즉, 추가 컨텍스트 없이는 이해하기 어렵게 다른 모듈이나 파일에 의존하는 경우가 있다.
이 논문은 기존의 코드 데이터셋의 한계점과 언어 모델의 성능에 대해 논의하고 있습니다. 기존의 코드 데이터셋은 의미 있는 계산을 포함하지 않으며, 대부분은 상수 정의, 매개 변수 설정 또는 GUI 요소 구성과 같은 단순한 코드로 이루어져 있습니다. 또한 알고리즘 로직을 포함하는 샘플들은 복잡하거나 문서화되지 않은 함수 안에 숨겨져 있어 따라가기 어렵고 학습하기 어렵습니다. 이러한 문제들은 인간 학습자가 이러한 데이터셋으로부터 코딩 스킬을 습득하는 것이 얼마나 괴로우고 비효율적인지 상상해볼 수 있습니다. 이러한 이유로 우리는 언어 모델의 성능에도 영향을 미치는 이러한 문제들을 해결하기 위해 노력하였습니다. 우리는 고의적으로 고품질의 데이터를 선택하고 생성함으로써 기존 방법보다 훨씬 작은 모델과 더 적은 계산으로 코드 생성 작업에서 최신 결과를 얻을 수 있다는 것을 보여줍니다. 우리의 훈련은 세 가지 주요 데이터셋을 기반으로 합니다. 첫째, 약 60억 토큰으로 구성된 The Stack과 StackOverflow의 하위 집합인 필터링된 코드-언어 데이터셋. 둘째, 약 10억 토큰의 GPT-3.5로 생성된 파이썬 데이터셋. 셋째, 약 1억 8천만 토큰의 파이썬 연습 문제와 해답으로 구성된 작은 합성 연습 데이터셋입니다. 이러한 데이터셋은 총 70억 토큰 이하입니다. 우리는 필터링된 코드-언어와 합성 교과서 데이터셋의 조합을 "CodeTextbook"이라고 부르며, 이를 기반으로 사전 훈련 단계에서 경쟁력 있는 HumanEval 성능 29%를 달성하는 기본 모델 phi-1-base을 얻을 수 있습니다. 그런 다음 1억 8천만 토큰의 합성 연습 데이터셋 "CodeExercises"를 사용하여 phi-1-base 모델을 세밀하게 튜닝하여 phi-1을 얻습니다.
기존의 코드 데이터셋은 의미 있는 계산을 포함하지 않으며, 대부분은 상수 정의, 매개 변수 설정 또는 GUI 요소 구성과 같은 단순한 코드로 이루어져 있습니다. 또한 알고리즘 로직을 포함하는 샘플들은 복잡하거나 문서화되지 않은 함수 안에 숨겨져 있어 따라가기 어렵고 학습하기 어렵습니다. 이러한 예제들은 특정 주제나 사용 사례에 편향되어 있어 데이터셋 전체에서 코딩 개념과 기술의 균형이 맞지 않습니다. 이러한 데이터셋에서 코딩 스킬을 습득하려는 인간 학습자에게는 많은 노이즈, 모호성 및 불완전성과 같은 문제가 발생하여 불만족스럽고 비효율적일 것으로 상상할 수 있습니다. 이러한 이유로 우리는 언어 모델의 성능에도 영향을 미치는 이러한 문제들을 해결하기 위해 노력하였습니다. 우리는 언어 모델이 자연어를 코드로 매핑하는 신호의 품질과 양을 줄이는 요소로 인해 기존 방법보다 더 많은 성과를 얻을 수 있을 것이라고 추측합니다. 우리는 언어 모델이 좋은 "교과서"로 인식할 수 있는 훈련 세트와 동일한 품질을 가지는 훈련 세트에서 장점을 얻을 것이라고 가정합니다. 이 논문에서 우리는 이러한 도전에 직접 대응하고, 고의적으로 고품질의 데이터를 선택하고 생성함으로써 기존 방법보다 훨씬 작은 모델과 더 적은 계산으로 코드 생성 작업에서 최신 결과를 얻을 수 있다는 것을 보여줍니다.
우리의 훈련은 세 가지 주요 데이터셋을 기반으로 합니다. 첫째, 약 60억 토큰으로 구성된 필터링된 코드-언어 데이터셋은 The Stack과 StackOverflow의 하위 집합입니다. 이 데이터셋은 언어 모델 기반의 분류기를 사용하여 얻었습니다. 둘째, 약 10억 토큰의 GPT-3.5로 생성된 파이썬 교과서 데이터셋입니다. 셋째, 약 1억 8천만 토큰의 파이썬 연습 문제와 해답으로 구성된 작은 합성 연습 데이터셋입니다. 이러한 데이터셋은 총 70억 토큰 이하입니다. 필터링된 코드-언어와 합성 교과서 데이터셋의 조합을 "CodeTextbook"이라고 부르며, 이를 기반으로 사전 훈련 단계에서 경쟁력 있는 HumanEval 성능 29%를 달성하는 기본 모델 phi-1-base을 얻을 수 있습니다. 그런 다음 1억 8천만 토큰의 합성 연습 데이터셋 "CodeExercises"를 사용하여 phi-1-base 모델을 세밀하게 튜닝하여 phi-1을 얻습니다.
2.1 Filtering of existing code datasets using a transformer-based classifier

우리는 공개적으로 사용 가능한 Python 코드 데이터셋을 사용하여 시작합니다. The Stack과 StackOverflow의 중복 제거된 버전의 Python 하위 집합을 사용하며, 이 데이터셋은 총 3천5백만 개의 파일/샘플과 3천5백억 개의 토큰을 포함합니다. 우리는 작은 부분집합의 파일(약 10만 개의 샘플)의 품질을 주석으로 지정하기 위해 GPT-4를 사용합니다. 주어진 코드 조각에 대해 모델에게 "기본 코딩 개념을 배우고자 하는 학생을 위한 교육적 가치를 판단하라"는 프롬프트를 제공합니다.
그런 다음 주석이 달린 이 데이터셋을 사용하여 사전 훈련된 codegen 모델의 출력 임베딩을 특징으로 사용하여 파일/샘플의 품질을 예측하는 랜덤 포레스트 분류기를 훈련시킵니다. 우리는 합성 콘텐츠 생성에 광범위하게 사용되는 GPT-3.5와 달리, GPT-4는 주로 The Stack과 StackOverflow의 작은 부분집합에 대한 주석에 사용됩니다. 따라서 우리는 GPT-4의 사용을 단순히 귀찮은 인간 주석 작업을 피하기 위한 방법으로만 사용한다고 생각합니다. [DLT+23]
2.2 Creation of synthetic textbook-quality datasets
코드 생성을 위한 고품질 데이터셋을 생성하는 주요 도전 중 하나는 예제가 다양하고 반복되지 않는 것을 보장하는 것이다. 이러한 다양성은 다양한 코딩 개념, 기술 및 시나리오를 다루고 난이도, 복잡성 및 스타일에서 다양성을 가져야 함을 의미한다. 이 다양성은 몇 가지 이유로 중요하다. 즉, 언어 모델에게 코드로 문제를 표현하고 해결하는 다양한 방법을 노출시키고, 특정 패턴이나 솔루션을 기억하거나 기억하는 것을 방지하며, 모델의 일반화 및 강건성을 높인다. 그러나 이러한 다양성을 달성하는 것은 쉽지 않다. 특히 다른 언어 모델에 의해 생성된 합성 데이터를 사용할 때 그렇다. 단순히 모델에게 코딩 교재나 연습 문제 세트를 생성하도록 지시하는 경우, 지시 사항이나 매개 변수에 약간의 변화가 있더라도 동일한 개념과 솔루션이 반복되는 매우 동질적이고 중복된 데이터셋이 생성될 것이다. 이는 언어 모델이 훈련 데이터와 사전에 주어진 가정을 기반으로 가장 가능성이 높거나 일반적인 경로를 따르며, 대체 또는 독특한 코드 생성 방식을 탐색하는 창의성이나 동기 부여가 부족하기 때문이다. 따라서 예제의 품질과 일관성을 유지하면서 언어 모델이 출력에서 더욱 창의적이고 다양한 방식으로 작동하도록 유도할 수 있는 적절한 "기교"를 찾아야 한다. [EL23]에서 영감을 받아, 고정된 어휘에서 선택된 단어의 무작위 하위 집합을 포함하여 다양한 짧은 이야기 집합이 생성되도록 요구하는 방식으로 무작위성을 입력에 주입하는 방법을 찾는다.
The synthetic textbook dataset
이 데이터셋은 GPT-3.5로 생성된 Python 교과서의 토큰 수가 10억개 미만인 데이터셋으로, 자연어가 많이 포함된 텍스트와 관련 있는 코드 스니펫이 교차되어 고품질의 소스를 제공하기 위해 합성되었습니다.
또한 이 교과서의 내용을 추론과 기본적인 알고리즘 기술을 촉진하는 주제로 고려했습니다. 여기에서 다양성은 생성된 교과서의 주제와 대상 독자에 대한 제약 조건을 제공함으로써 얻을 수 있습니다. 다음 예시는 합성으로 생성된 교과서 텍스트를 보여줍니다.
먼저, 단수 행렬과 비단수 행렬을 정의해 봅시다. 행렬의 행렬식이 0이면 해당 행렬은 단수 행렬이라고 합니다. 반면, 행렬의 행렬식이 0이 아니면 해당 행렬은 비단수 행렬이라고 합니다. 이제 예제를 통해 이러한 개념을 살펴보겠습니다.
예제 1:
행렬 A = np.array([[1, 2], [2, 4]])을 고려해 봅시다. 이 행렬이 단수인지 비단수인지를 행렬식 함수를 사용하여 확인할 수 있습니다. is_singular(A)라는 Python 함수를 정의할 수 있으며, 이 함수는 A의 행렬식이 0이면 true를 반환하고 그렇지 않으면 false를 반환합니다.

The CodeExercises dataset
이것은 작은 합성 연습 데이터셋으로, Python 연습문제와 해답의 토큰 수가 1억 8000만개 미만입니다. 각 연습문제는 완성해야 하는 함수의 문서 문자열입니다. 이 데이터셋의 목표는 자연어 지침에 기반하여 함수 완성 작업을 수행하는 모델을 조정하는 것입니다. 이 데이터셋은 GPT-3.5로 생성되었으며, 주된 다양성 유도 방법은 함수 이름을 제한함으로써 이루어집니다. 특히 이 데이터셋에 대해서는 다음 섹션에서 명시적인 오염 제거와 대체 평가를 수행하여 HumanEval 벤치마크와 유사한 문제가 미세조정 동안 나타나지 않도록 보장합니다. 다음 스니펫은 합성으로 생성된 연습문제를 보여줍니다.

2.3 Model architecture and traning
우리는 FlashAttention 구현을 사용하여 멀티 헤드 어텐션(MHA) [DFE+22]을 사용한 디코더 전용 트랜스포머 [VSP+17] 모델을 사용합니다. 또한 CodeGen [NPH+22], PaLM [CND+22], GPT-NeoX [BBH+22]와 같은 최근 모델들을 따라 MHA 및 MLP 레이어를 병렬 구성으로 사용합니다. 우리의 13억 개 파라미터 phi-1 모델의 아키텍처는 24개 레이어, 2048의 히든 디멘션, 8192의 MLP 인터 디멘션, 각각 64의 어텐션 헤드 32개로 구성됩니다. 더 작은 3억 5000만 개 파라미터 phi-1-small 모델은 20개의 레이어, 1024의 히든 디멘션, 4096의 MLP 인터 디멘션, 각각 64의 어텐션 헤드 16개로 구성됩니다.
우리는 rotary position embedding [SLP+21]을 32의 rotary 디멘션으로 사용합니다. 이러한 아키텍처 선택은 [NPH+22]에서 채택되었습니다. 또한 우리는 codegen-350M-mono [NPH+22]와 동일한 토크나이저를 사용합니다. FlashAttention을 제외하고 우리의 모델들은 Fill-In-the-Middle (FIM) [BJT+22] 또는 Multi-Query-Attention (MQA) [RSR+20]와 같은 다른 새로운 기술을 사용하지 않습니다. 이러한 기술들은 성능과 효율성을 더욱 향상시킬 수 있습니다 [LAZ+23].
pretraining과 finetuning 모두에서 우리는 각각의 데이터셋을 파일을 구분하는 "∣endoftext∣" 토큰을 사용하여 하나의 차원 배열로 연결합니다. 우리는 다음 토큰 예측 손실을 가진 2048의 시퀀스 길이로 데이터셋 배열에서 모델을 훈련시킵니다. 우리는 AdamW 옵티마이저, linear-warmup-linear-decay 학습률 스케줄, 그리고 어텐션과 residual dropout 0.1을 사용하는 fp16 훈련을 사용합니다. 우리는 deepspeed를 사용하여 8개의 Nvidia-A100 GPU에서 모델을 훈련시킵니다. 우리의 사전 훈련된 베이스 모델 phi-1-base는 4일 이내의 훈련으로 얻어졌습니다. 동일한 하드웨어에서 phi-1을 얻기 위해 추가로 7시간을 사용하여 finetuning을 수행합니다.
사전 훈련. phi-1-base는 CodeTextbook 데이터셋(필터링된 코드-언어 말뭉치 및 합성 교과서)로 훈련되었습니다. 데이터 병렬 처리 및 그라디언트 누적을 포함한 효과적인 배치 크기 1024, 웜업 단계 750에서 최대 학습률 1e-3, 가중치 감소 0.1을 사용하여 총 36,000 단계 동안 훈련합니다. 우리는 24,000 단계의 체크포인트를 phi-1-base로 사용합니다. 이는 총 50B 이상의 훈련 토큰에 대해 CodeTextbook 데이터셋에서 약 8 epoch에 해당합니다. 작은 크기와 계산 능력에도 불구하고, 이 모델은 이미 HumanEval에서 29%의 정확도를 달성합니다.
Finetuning. phi-1은 CodeExercises 데이터셋에서 phi-1-base를 finetuning하여 얻어집니다. finetuning을 위해 사전 훈련과 동일한 설정을 사용하지만 하이퍼파라미터는 다릅니다. 효과적인 배치 크기는 256, 웜업 50 단계에서 최대 학습률 1e-4, 가중치 감소 0.01을 사용합니다. 총 6,000 단계 동안 훈련하고 매 1000 단계마다 최상의 체크포인트를 선택합니다.
3 Spikes of model capability after finetuning on CodeExcersies
Figure 2.1은 HumanEval에서의 가장 큰 개선이 작은 CodeExercises 데이터셋 (<200M 토큰)에서의 finetuning으로 인한 것임을 보여줍니다. CodeExercises는 기본 Python 라이브러리만 사용하는 짧은 Python 작업으로만 구성됩니다. 이 섹션에서는 finetuning 데이터셋에 포함되지 않은 작업을 실행하는 데 모델이 상당한 개선을 보이는 것을 보여줍니다. 이는 본질적으로 본인의 CodeExercises 데이터셋에 명시적으로 포함되지 않은 지식을 사전 훈련 기간 동안 습득하고 정리하는 데 모델이 도움을 받았을 가능성을 시사합니다. 이 섹션에서는 finetuned 모델 phi-1과 그 사전 훈련된 13억 개 파라미터 베이스 모델 phi-1-base의 능력을 질적으로 비교하고 대조하는 데 초점을 맞출 것입니다.
3.1 Finetuning improves the model's understanding
우리가 직접 만든 간단한 Python 함수를 사용하여, 우리는 아래에서 finetuning 후 모델이 지시에 대해 훨씬 더 높은 수준의 이해력과 준수성을 보여줍니다.
특히, phi-1-base는 프롬프트의 논리적인 관계에 어려움을 겪지만, phi-1은 질문을 해석하고 정확한 답을 생성할 수 있습니다. 이 예시에서는 350M의 phi-1-small 모델조차도 문제에 대한 이해 수준을 일부 보여주지만, 결과적인 해결책은 잘못됩니다.

3.2 Feinetuning improves the model's ability to use external libraries

CodeExercises에서의 Feinetuning이 예상치 못하게 Pygame과 Tkinter와 같은 외부 라이브러리 사용 능력을 향상시킨다는 것을 여기서 보여줍니다. 우리의 연습문제에는 이러한 라이브러리가 포함되어 있지 않음에도 불구하고, 이는 우리의 Feinetuning이 목표로 한 작업뿐만 아니라 관련 없는 작업을 사전 훈련으로부터 보다 쉽게 추출 가능하게 만든다는 것을 시사합니다. 참고로, Figure 3.1은 CodeExercises 데이터셋에서 패키지 임포트의 분포를 보여줍니다.
Figure 3.1: Feinetuning에서 879486개의 연습문제 중 임포트 수 (10회 미만으로 무시된 라이브러리 임포트). 그래프는 다음 프롬프트로 phi-1에 의해 생성되었습니다: "사전이 있을 때, 값을 기준으로 사전을 큰 값부터 작은 값으로 정렬하고, pyplot 막대 그래프를 생성하세요. 먼저 글꼴 크기를 7로 설정하고, 그 다음 x축 레이블을 90도로 회전하세요. x축은 키이고, y축은 사전의 값입니다. y축에 로그 스케일을 사용하세요. 또한, y축 레이블을 'Log Number of Times'로, x축 레이블을 'Imports'로 설정하세요. dpi는 1000으로 설정하세요."
PyGame 예제
PyGame을 사용하여 코드를 생성하여 공을 이동시킵니다.

위의 코드 스니펫은 화면에 공을 튕기는 간단한 PyGame 프로그램의 메인 루프를 보여줍니다. phi-1은 프롬프트에 지시된 대로 PyGame 함수를 사용하여 공을 업데이트하고 그리는 능력을 올바르게 적용합니다. phi-1-base와 phi-1-small은 문법적으로 올바른 함수 호출을 생성하지만 의미론적으로는 관련이 없습니다. phi-1-base는 적절한 API 호출을 사용하는 능력을 일부 보여주지만, 작업의 논리를 따르지 못합니다. 반면에 phi-1-small은 논리를 이해하지만 올바른 함수 호출을 학습할 충분한 능력이 없습니다.
TKinter 예제. 두 번째 예제는 사용자가 버튼을 클릭할 때 모델에게 텍스트 필드를 업데이트하도록 요청하는 TKinter 응용 프로그램입니다.

세 모델의 완성은 프롬프트 이해력에 큰 차이를 보여줍니다. phi-1-base와 phi-1-small은 올바른 Tkinter API를 사용하지 못하고 의미 없는 함수 호출을 만듭니다. 반면 phi-1은 GUI와 모든 함수를 올바르게 구현했습니다(단, "pewpewpew?"를 올바르게 복사하지 않았습니다). Appendix A에는 pytorch 및 pyplot을 위한 두 가지 추가 예제를 제시합니다.
채팅 모드 예제입니다. 마지막으로, 우리는 phi-1이 phi-1-base보다 더 나은 채팅 능력을 갖고 있다는 것을 보여줍니다. 사전 훈련에서는 채팅 데이터가 배제되지만, fine-tuning에서는 배제되지 않음에도 불구하고입니다.

| 모델 | 크기 | 훈련 토큰 | 점수 | HumanEval |
|---|---|---|---|---|
| CodeGen-Mono-350M | 350M | 577B | 0.19 | 12.8% |
| CodeGen-Mono-16.1B | 16.1B | 577B | 0.38 | 29.3% |
| Replit | 2.7B | 525B | 0.37 | 21.9% |
| StarCoder | 15.5B | 1T | 0.51 | 33.6% |
| phi-1-base | 1.3B | 7B | 0.37 | 29% |
| phi-1-small | 350M | 7B | 0.45 | 45% |
| phi-1 | 1.3B | 7B | 0.52 | 50.6% |
표 2: 50개의 새로운 비전통적 코딩 문제에 대한 LLM 등급 이해도.
([EL23]에서와 같이) 이 접근 방식은 두 가지 명확한 장점이 있습니다. (1) GPT-4를 평가자로 사용함으로써, 학생 모델의 코딩 능력에 대한 더 세밀하고 의미 있는 신호를 얻을 수 있으며, (2) 테스트의 필요성을 없앱니다. 우리의 프롬프트는 LLM에게 학생의 솔루션을 먼저 짧은 언어 평가로 평가한 다음 0부터 10까지의 등급을 매기도록 지시합니다. phi-1과 경쟁 모델의 결과는 표 2를 참조하십시오. 새로운 비전통적 문제에서의 등급은 HumanEval과 동일한 순위를 제공합니다(표 1 참조). phi-1은 StarCoder보다 높은 점수를 달성하며, 이는 HumanEval에서도 마찬가지입니다. 이러한 새로운 문제들이 훈련 데이터에 오염되는 기회가 없었으며, 또한 훈련 분포 범위를 벗어난 것으로 설계되었기 때문에, 이러한 결과는 phi-1의 성능의 타당성에 대한 신뢰도를 크게 높입니다.
5 Data pruning for unbiased performance evaluation
그림 2.1에서 CodeExercises로의 훈련이 HumanEval 벤치마크에서 모델의 성능을 상당히 향상시킨 것을 볼 수 있습니다. 이 향상을 조사하기 위해, 우리는 CodeExercises 데이터셋에서 HumanEval과 "유사한" 파일을 제거하여 데이터를 가지치기하는 것을 제안합니다. 이 과정은 "강력한 형태"의 데이터 오염 제거로 볼 수 있습니다. 그런 다음 가지치기된 데이터에서 모델을 다시 훈련하고, 여전히 HumanEval에서 강력한 성능을 관찰합니다. 특히, 40% 이상의 CodeExercises 데이터셋을 적극적으로 가지치기한 경우에도 (이는 HumanEval과 미묘하게 유사한 파일도 가지치기합니다. Appendix C 참조), 재훈련된 phi-1은 여전히 StarCoder보다 우수한 성능을 나타냅니다.
우리는 이러한 데이터 가지치기 실험이 성능을 공정하게 평가하는 방법이며, 일반적으로 훈련 및 테스트 데이터 간의 중첩 정도를 기반으로 하는 기존 "오염" 연구에 비해 보다 의미 있는 것이라고 믿습니다 ([AON+21] 4.8 장 참조). 완전성을 위해, 이 섹션에서는 표준적인 오염 실험을 수행하여 CodeExercises가 이 표준적인 의미에서 HumanEval에 오염되지 않았음을 보여줍니다.
5.1 N-gram overlap
N-gram은 공유되는 n-단어 시퀀스에 기반하여 텍스트 세그먼트의 유사성을 측정합니다. 우리는 humaneval 질문의 독스트링과 CodeExercises 데이터셋에서 생성된 각 연습문제의 n-gram 중첩을 계산합니다. 우리는 데이터셋에서 적어도 하나의 항목과 13-gram 중첩이 있는 humaneval 질문 4개를 찾았습니다. 추가 조사 결과, 13-gram의 4개 중복 사례가 모두 아래 예시와 같이 거짓 양성임을 알게 되었습니다. 우리의 n-gram 중첩 분석은 데이터셋이 HumanEval과 거의 문자 단위로 중첩되지 않음을 보여줍니다.
테스트 세트를 엄격하게 구성하는 것은 [LXWZ23]에 의해 보여진 대로 상당한 작업일 수 있습니다. 이 논문은 주어진 양수 정수의 리스트에서 0보다 크고, 정수 자체의 값과 동일하거나 그보다 빈도가 더 높은 가장 큰 정수를 반환하는 알고리즘을 제안한다. 정수의 빈도는 리스트에서 나타나는 횟수이다. 또한 정수 리스트의 제곱 빈도의 합을 계산하는 알고리즘을 소개한다. 이를 위해 정수 리스트의 중복되지 않는 각 정수의 빈도 제곱의 합을 구한다. 정수의 빈도는 리스트에서 나타나는 횟수이다.
5.2 Embedding and syntax-based similarity analysis
우리는 이제 가지치기 실험에 대해 알아본다. 방금 본 것처럼, n-gram 분석은 HumanEval과 CodeExercises 사이의 유사한 코드 조각을 찾는 데에는 충분히 정교하지 않다. 대신 임베딩과 구문 기반 거리의 조합을 사용한다. 임베딩 거리에 대해서는 사전 훈련된 CodeGen-Mono 350M 모델 [NPH+23]에서 유도된 코드 조각의 임베딩 간의 L2 거리를 계산한다. 우리는 임베딩 거리가 전체적인 코드 의미가 유사한 코드 쌍을 포착하는 데 성공했다는 것을 관찰했다. 이는 파이썬 Docstring, 함수/클래스 이름, 코드 구조를 통해 추론할 수 있다. 구문 기반 거리에 대해서는 주어진 두 코드 조각의 추상 구문 트리 (AST) 사이의 (문자열) 편집 거리를 계산한다. AST 거리는 코드 쌍 사이의 중복되는 부분을 성공적으로 식별하며, 변수/함수 이름, 주석 및 파이썬 Docstring과 같은 비구문 텍스트에 대해서는 무관하다. CodeExercises의 가지치기를 위해 임베딩 거리에 대한 임계값을 고정하고, AST 거리에 대한 여러 매치 비율 τ를 테스트한다. 임베딩 거리와 여러 AST 매치 비율 τ로 포착된 코드 쌍의 예시는 부록 C를 참조하라. 우리는 τ를 0.95에서 0.8 사이로 변화시킨다. 이는 CodeExercises의 879.5K 총 문제 중 42.5K에서 354K를 제거하는 것에 해당한다.
| τ | 문제 개수 | phi-1 재학습 | StarCoder-Prompted |
|---|---|---|---|
| 0.95 | Similar 71 (81.7%) | 74.6% | 57.7% |
| non-similar 93 (26.9%) | 32.3% | 29.0% | |
| total 164 (50.6%) | 50.6% | 41.5% | |
| 0.9 | Similar 93 (63.4%) | 51.6% | 48.4% |
| non-similar 71 (33.8%) | 36.6% | 32.4% | |
| total 164 (50.6%) | 45.1% | 41.5% | |
| 0.85 | Similar 106 (62.3%) | 52.8% | 47.2% |
| non-similar 58 (29.3%) | 34.5% | 31.0% | |
| total 164 (50.6%) | 46.3% | 41.5% | |
| 0.8 | Similar 116 (59.5%) | 52.6% | 45.7% |
| non-similar 48 (29.2%) | 27.1% | 31.2% | |
| total 164 (50.6%) | 45.1% | 41.5% |
표 3은 다른 모델이 올바르게 해결한 유사한 HumanEval 문제와 유사하지 않은 문제의 백분율을 요약한 것이다. 유사성은 해당 HumanEval 문제가 원래의 CodeExercises 데이터셋 내에서 가까운 매치가 있는지 여부에 따라 결정된다 (주어진 τ에 대해). 문제 개수는 각 하위 집합 내의 HumanEval 문제의 수를 나타낸다. 여기서 τ는 유사성 검사를 위한 코드 간 AST 기반 매치 비율의 임계값이다.
6 Conclusion
이 논문에서는 양수 정수의 리스트에서 특정 조건을 만족하는 가장 큰 정수를 반환하는 알고리즘과 정수 리스트의 빈도 제곱의 합을 계산하는 알고리즘을 제안하였다. 또한 임베딩과 구문 기반 거리를 조합하여 코드 유사도를 분석하는 방법을 제시하였다. 실험 결과, 임베딩 거리와 AST 거리를 사용하여 유사한 코드 쌍을 포착할 수 있음을 확인하였다. 이러한 결과는 프로그래밍 언어와 코드 구조의 특징을 잘 파악하여 코드의 의미를 파악하는 것이 중요하다는 것을 보여준다. 이러한 알고리즘과 분석 방법은 코드 검색 및 유사도 분석에 활용될 수 있을 것으로 기대된다.
이 논문에서는 고품질 데이터의 중요성을 강조하며, 이를 통해 코드 생성 작업에서 언어 모델의 능력을 향상시킬 수 있다는 것을 입증했습니다. "교과서 수준"의 데이터를 사용하여, 모델 크기는 10배 작고 데이터셋 크기는 100배 작음에도 불구하고, HumanEval 및 MBPP와 같은 코딩 벤치마크에서 거의 모든 오픈소스 모델을 능가하는 모델을 훈련시킬 수 있었습니다. 이러한 고품질 데이터는 코딩 개념과 기술의 명확하고 자체 포함된 균형 잡힌 예제를 제공하여 코드에 대한 언어 모델의 학습 효율성을 크게 향상시킬 수 있다고 가설을 제기합니다. 그러나 이 모델은 파이썬 코딩에 특화되어 있고, 다른 언어 모델에 비해 다른 API를 사용하거나 드문 패키지를 사용하는 프로그래밍과 같은 도메인 특정 지식이 부족합니다. 또한 데이터셋의 구조화된 특성과 언어 및 스타일의 다양성 부족으로 인해 스타일 변화나 프롬프트의 오류(예: 문법 오류)에 대해 덜 견고합니다. 이러한 한계를 극복하기 위해 더 많은 연구가 필요하지만, 그럼에도 불구하고 이 접근 방식을 사용하여 모델의 성능을 향상시킬 수 있을 것이라고 믿습니다.
이 연구는 고품질 데이터셋을 생성하는 좋은 방법론을 개발하는 것이 자연어 처리 및 관련 분야의 연구의 중심 방향임을 보여줍니다. 그러나 고품질 데이터셋을 생성하는 것은 간단한 작업이 아니며, 해결해야 할 몇 가지 도전 과제가 있습니다. 데이터셋이 모델이 배워야 할 모든 관련 컨텐츠와 개념을 균형있고 대표적인 방식으로 다루고 있는지 보장하는 것이 한 가지 도전 과제입니다. 또 다른 도전 과제는 데이터셋이 실제로 다양하고 반복적이지 않도록 하는 것이며, 모델이 데이터에 단순히 과적합되지 않거나 특정 패턴이나 솔루션을 암기하지 않도록 해야 합니다. 이는 데이터 생성 과정에 무작위성과 창의성을 주입하는 방법을 찾는 것을 요구하며, 동시에 예제의 품질과 일관성을 유지해야 합니다. 또한 이러한 데이터를 생성하기 위해 언어 모델 자체가 사용될 것이므로, 이 과정에 관련된 데이터와 모델의 책임, 투명성 및 편향과 같은 윤리적 및 사회적 영향에 대한 중요성이 더욱 증가합니다.
References
[ADF+23] Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre
Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, 등. Palm 2 기술 보고서. arXiv 사전 인쇄 arXiv:2305.10403 , 2023.
[ALK+23] Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey 등. Santacoder: 별을 향해 가지 마세요! arXiv 사전 인쇄 arXiv:2301.03988 , 2023.
[AON+21] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le 등. 대형 언어 모델을 사용한 프로그램 합성. arXiv 사전 인쇄 arXiv:2108.07732 , 2021.
[AZL23] Zeyuan Allen-Zhu와 Yuanzhi Li. 언어 모델의 물리학: 제1부, 문맥 자유 문법. arXiv 사전 인쇄 arXiv:2305.13673 , 2023.
[BBH+22] Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach 등. GPT-NeoX-20B: 오픈 소스 자기회귀 언어 모델. ACL Workshop on Challenges & Perspectives in Creating Large Language Models 논문집, 2022.
[BCE+23] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg 등. 인공 일반 지능의 발화: gpt-4의 초기 실험. arXiv 사전 인쇄 arXiv:2303.12712 , 2023.
[BGMMS21] Emily M Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell. 확률적 앵무새의 위험성: 언어 모델이 너무 커질 수 있을까? 2021년 공정성, 책임성, 투명성 ACM 학회 논문집, 페이지 610-623, 2021.
[BJT+22] Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, Mark Chen. 가운데 부분 채우기를 위한 언어 모델의 효율적인 훈련. arXiv 사전 인쇄 arXiv:2207.14255 , 2022.
[BMR+20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. 언어 모델은 소량 샷 학습자입니다. 신경 정보 처리 시스템의 발전, 33권, 페이지 1877-1901, 2020.
[CND+22] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann 등. Palm: 경로로 언어 모델 확장. arXiv 사전 인쇄 arXiv:2204.02311 , 2022.
[CTJ+21] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 , 2021.
[DFE+22] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems , 35:16344–16359, 2022.
[DLT+23] Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387 , 2023.
[EL23] Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english? arXiv preprint arXiv:2305.07759 , 2023.
[GWS+23] Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, and Dawn Song. The false promise of imitating proprietary llms. arXiv preprint arXiv:2305.15717 , 2023.
[HBM+22] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack William Rae, and Laurent Sifre. An empirical analysis of compute-optimal large language model training. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems , 2022.
[HNA+17] Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409 , 2017.
[JWJ+23] Jaehun Jung, Peter West, Liwei Jiang, Faeze Brahman, Ximing Lu, Jillian Fisher, Taylor Sorensen, and Yejin Choi. Impossible distillation: from low-quality model to high-quality dataset & model for summarization and paraphrasing. arXiv preprint arXiv:2305.16635 , 2023.
[KLA+22] Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Mu˜ noz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, et al. The stack: 3 tb of permissively licensed source code. arXiv preprint arXiv:2211.15533 , 2022.
[KMH+20] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 , 2020.
[LAZ+23] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161 , 2023.
[LCC+22] Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science , 378(6624):1092–1097, 2022.
[LGK+23] Zinan Lin, Sivakanth Gopi, Janardhan Kulkarni, Harsha Nori, and Sergey Yekhanin. Differentially private synthetic data via foundation model apis 1: Images. arXiv preprint arXiv:2305.15560, 2023.
[LXWZ23] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. arXiv preprint arXiv:2305.01210, 2023.
[LXZ+23] Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct, 2023.
[LYR+23] Shayne Longpre, Gregory Yauney, Emily Reif, Katherine Lee, Adam Roberts, Barret Zoph, Denny Zhou, Jason Wei, Kevin Robinson, David Mimno 등. A pretrainer's guide to training data: Measuring the effects of data age, domain coverage, quality, & toxicity. arXiv preprint arXiv:2305.13169, 2023.
[MMJ+23] Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707, 2023.
[MRB+23] Niklas Muennighoff, Alexander M Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. arXiv preprint arXiv:2305.16264, 2023.
[NHX+23] Erik Nijkamp, Hiroaki Hayashi, Caiming Xiong, Silvio Savarese, and Yingbo Zhou. Codegen2: Lessons for training llms on programming and natural languages. arXiv preprint arXiv:2305.02309, 2023.
[NPH+22] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint, 2022.
[NPH+23] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. ICLR, 2023.
[Ope23] OpenAI. Gpt-4 technical report, 2023. arXiv preprint arXiv:2303.08774 [cs.CL].
[Rep23] Replit. Replit dev day. https://twitter.com/Replit/status/1651344184593506304, 2023.
[RSR+20] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485-5551, 2020.
[SLP+21] Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864, 2021.
[SSZ+23] Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. Model dementia: Generated data makes models forget. arXiv preprint arXiv:2305.17493, 2023.
[TGZ+23] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin,
Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama
model.https://github.com/tatsu-lab/stanford_alpaca , 2023.
[VSP+17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N
Gomez, L ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances
in Neural Information Processing Systems , volume 30, 2017.
[WKM+22] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel
Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language model with self gen-
erated instructions. arXiv preprint arXiv:2212.10560 , 2022.
[WLG+23] Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi DQ Bui, Junnan Li, and Steven CH
Hoi. Codet5+: Open code large language models for code understanding and generation.
arXiv preprint arXiv:2305.07922 , 2023.
[WTB+22] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani
Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto,
Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large
language models. Transactions on Machine Learning Research , 2022. Survey Certification.
[YGK+23] Da Yu, Sivakanth Gopi, Janardhan Kulkarni, Zinan Lin, Saurabh Naik, Tomasz Lukasz
Religa, Jian Yin, and Huishuai Zhang. Selective pre-training for private fine-tuning. arXiv
preprint arXiv:2305.13865 , 2023.
[ZXZ+23] Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei
Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. Codegeex: A pre-trained
model for code generation with multilingual evaluations on humaneval-x, 2023.
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [Pinecone] llama-index with Pinecone (0) | 2023.10.01 |
|---|---|
| The Path to Achieve Ultra-Low Inference Latency With LLaMA 65B on PyTorch/XLA (0) | 2023.07.06 |
| LLM Context 확장 불가능은 아니다. (token size 늘리기 정리) (0) | 2023.06.28 |
| Text Embedding + t-SNE Visualization (0) | 2023.06.22 |
| [Langchain] paper-translator (0) | 2023.06.16 |