
* BERT모델에 사용되는 사전 학습 전략 (Pretrained Training)
다음 문장 예측에 대한 방법은 이진 분류로 진행한다.
EX)
A : 종합소득세 신고는 어디서하나요?
B : 홈텍스에서 합니다.
A의 후속 문장으로 B가 알맞음을 알 수 있다. 이 경우 isNext(True)로 표시 한다.
A : 종합소득세 신고는 어디서하나요?
B : SSEM에서 합니다.
A의 후속 문장이 B가 맞는지 알 수 없다. 이 경우 notNext(False)로 표시한다.
이렇게 is / not으로 이진 분류를 진행한다.
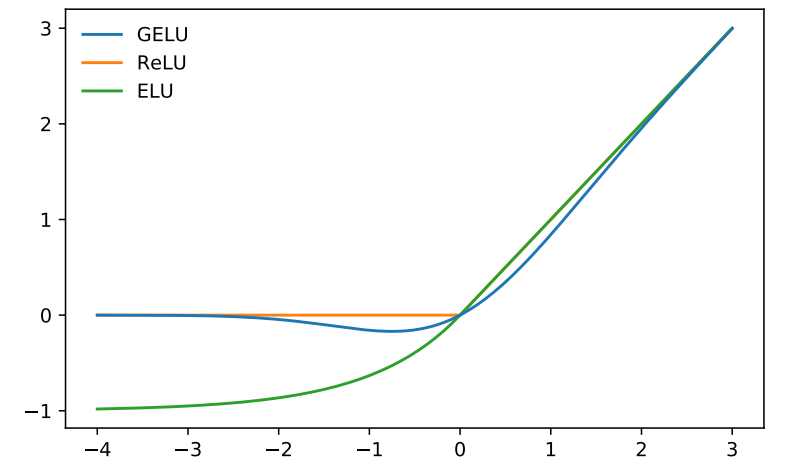
학습 초기에는 피드포워드 네트워크(ReLU)의 가중치가 정확하지 않아 올바르게 반환하지 못한다. 최적의 가중치를 찾으면서 다음 문장에 대한 관계를 정확하게 판단하게 된다.

* 사전 학습 절차
MLM(Mask 채우기)
+ NSP(다음 문장 예측)을 통해 BERT를 학습 시킨다.
+ 웜업 스텝 - Adam Optimizer (초기에는 큰 변화를 유도하고 학습 후반에는 낮은 학습률로 작은 변화를 주어 최적화)
활성화 함수로 GeLU(Gaussian Error Linear Unit)를 사용
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [BERT TOKENIZE]단어 토큰화 (1)- 바이트 쌍 인코딩 (0) | 2022.05.09 |
|---|---|
| [BERT] 하위 단어 토큰화 + OOV (Out of Vocabulary) (0) | 2022.05.09 |
| 버키팅(bucketing)을 이용한 학습 복잡도 해결 (0) | 2021.03.28 |
| [CNN] 합성곱 신경망 (feat. Learning Word Vectors for Sentiment Analysis) (0) | 2021.03.13 |
| [doc2vec] 문서 유사도 추정 (0) | 2021.03.09 |
* BERT모델에 사용되는 사전 학습 전략 (Pretrained Training)
다음 문장 예측에 대한 방법은 이진 분류로 진행한다.
EX)
A : 종합소득세 신고는 어디서하나요?
B : 홈텍스에서 합니다.
A의 후속 문장으로 B가 알맞음을 알 수 있다. 이 경우 isNext(True)로 표시 한다.
A : 종합소득세 신고는 어디서하나요?
B : SSEM에서 합니다.
A의 후속 문장이 B가 맞는지 알 수 없다. 이 경우 notNext(False)로 표시한다.
이렇게 is / not으로 이진 분류를 진행한다.
학습 초기에는 피드포워드 네트워크(ReLU)의 가중치가 정확하지 않아 올바르게 반환하지 못한다. 최적의 가중치를 찾으면서 다음 문장에 대한 관계를 정확하게 판단하게 된다.
* 사전 학습 절차
MLM(Mask 채우기)
+ NSP(다음 문장 예측)을 통해 BERT를 학습 시킨다.
+ 웜업 스텝 - Adam Optimizer (초기에는 큰 변화를 유도하고 학습 후반에는 낮은 학습률로 작은 변화를 주어 최적화)
활성화 함수로 GeLU(Gaussian Error Linear Unit)를 사용
'🗣️ Natural Language Processing' 카테고리의 다른 글
| [BERT TOKENIZE]단어 토큰화 (1)- 바이트 쌍 인코딩 (0) | 2022.05.09 |
|---|---|
| [BERT] 하위 단어 토큰화 + OOV (Out of Vocabulary) (0) | 2022.05.09 |
| 버키팅(bucketing)을 이용한 학습 복잡도 해결 (0) | 2021.03.28 |
| [CNN] 합성곱 신경망 (feat. Learning Word Vectors for Sentiment Analysis) (0) | 2021.03.13 |
| [doc2vec] 문서 유사도 추정 (0) | 2021.03.09 |