
[8일차]
1. Deep Learning의 구조 소개
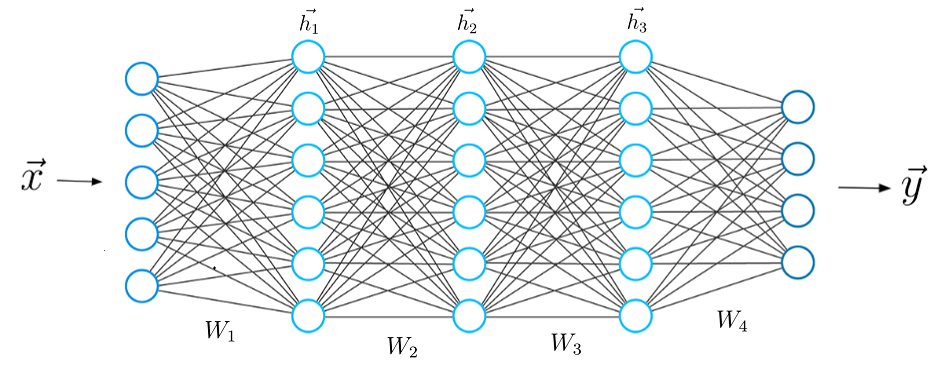
* Wn(Weight) : 회귀 분석의 회귀 계수와 비슷한 역할을 한다.
회귀 분석의 목적과 동일 하게 변수를 통해 Output을 찾는 식을 구하는 방식이다.
2. 다양한 Optimizer 소개
* 경사하강법(Gradient descent) :
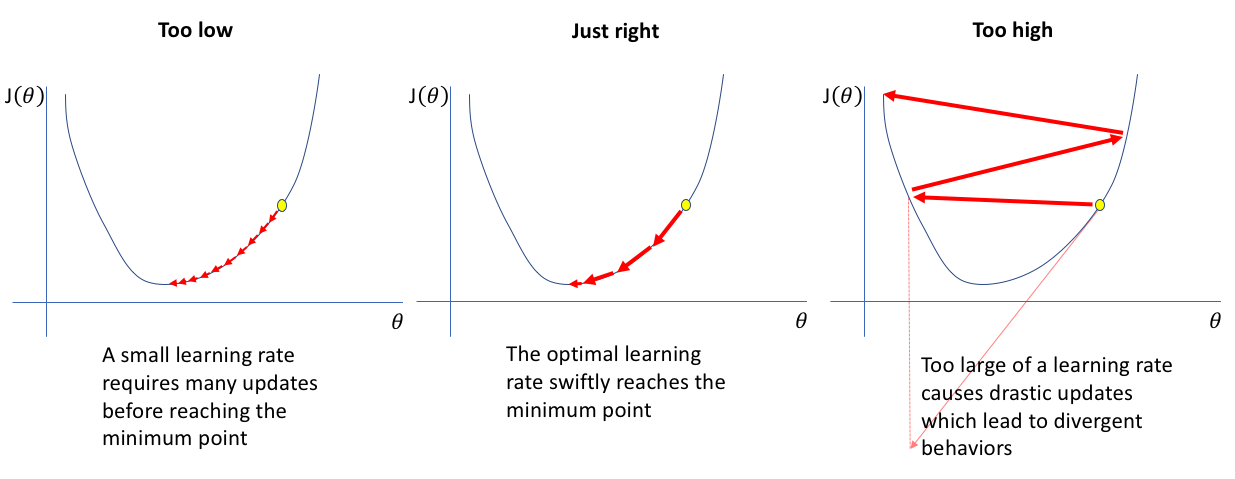
- stochastic gradient descent : 값을 하나하나 넣어 갱신하기 때문에 시간이 오래걸린다는 단점이 있다.
- Batch gradient descent : Training set data의 가중치 평균을 이용하여 갱신
- Mini Batch : 일부 훈련자료의 무작위 복원 추출하여 Training set data의 가중치 평균을 갱신
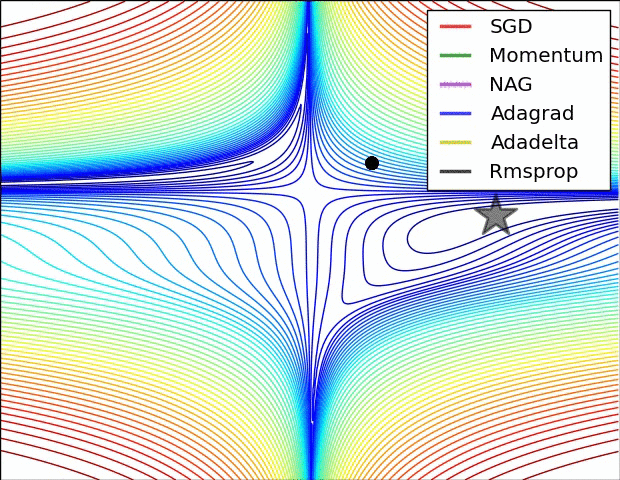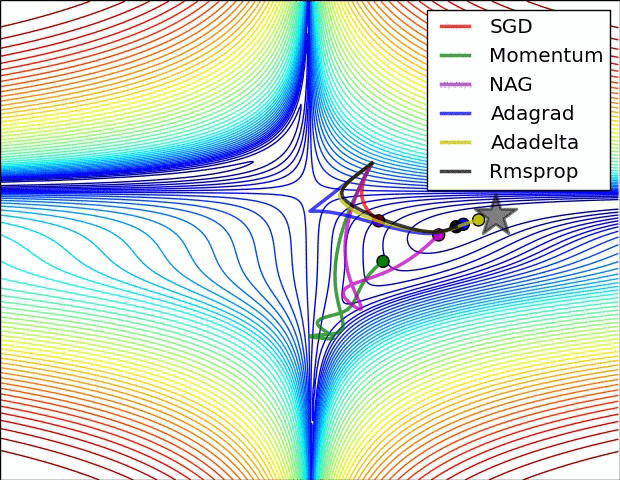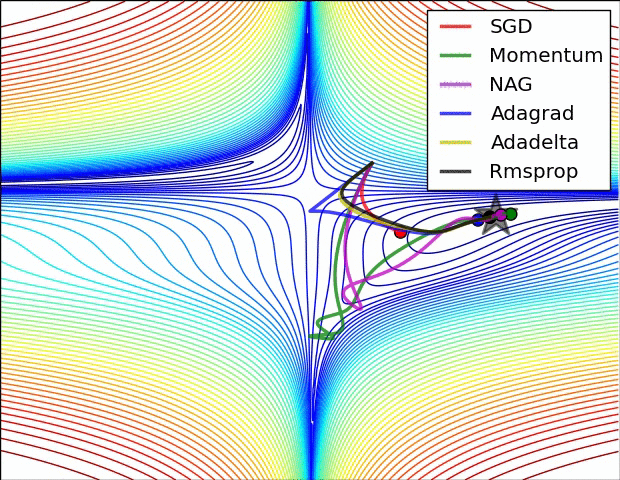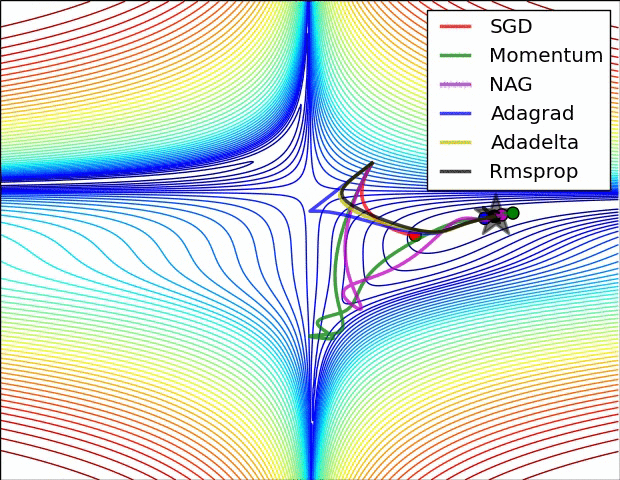
3. Learning rate를 조절하는 방식
- ADAM : Momentum과 RMSProp의 혼합형으로서 기존 진행방향과 진행폭을 모두 반영
- Momentum : 기존 진행방향에 대한 관성을 기억함으로써 SGD의 방법의 진동폭을 완화
- AdaGrad : 기존 가중치 변화의 진행 폭을 고려하여 이를 반영하여 학습률을 변화
- RMSProp : AdaGrad의 gt가 무작정 커지는 것을 방지하기 위하여 고안된 방법
4. RBM(Restricted Boltzmann Machine)
볼츠만이 고안한 모델에 제프리 힌턴이 제약을 두어 사용을 하니 딥러닝의 신경망 모델과 유사성을 발견하여 위에 언급한 기울기가 0이 되어 극소점을 찾지 못하는 기울기 소실(Gradient Vanishing)을 해결
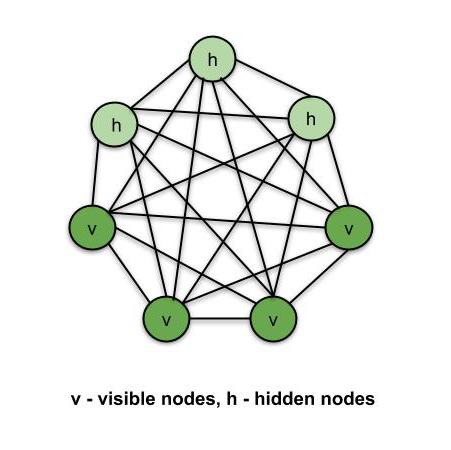
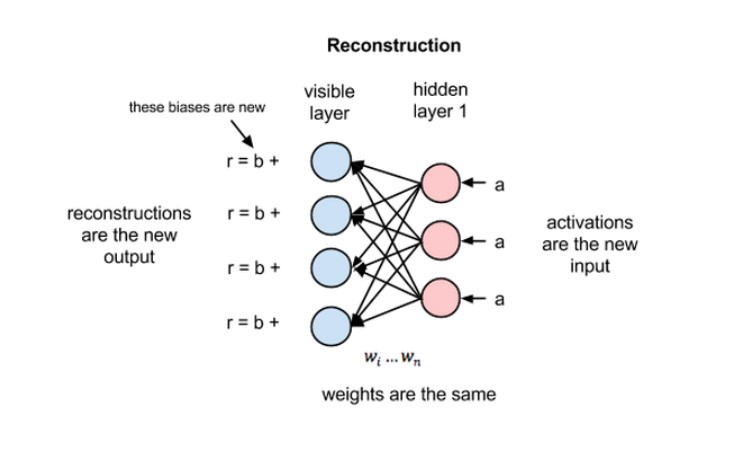
- 가시층과 은닉층으로 구성된 비지도 학습 신경망 모델
- 주어진 데이터들을 가장 잘 설명하는 특정 패턴을 높은 확률로 발생시킨다.
- 기준 MLE(Maximum Liklihood Estimate) 사용
5. Autoencoder
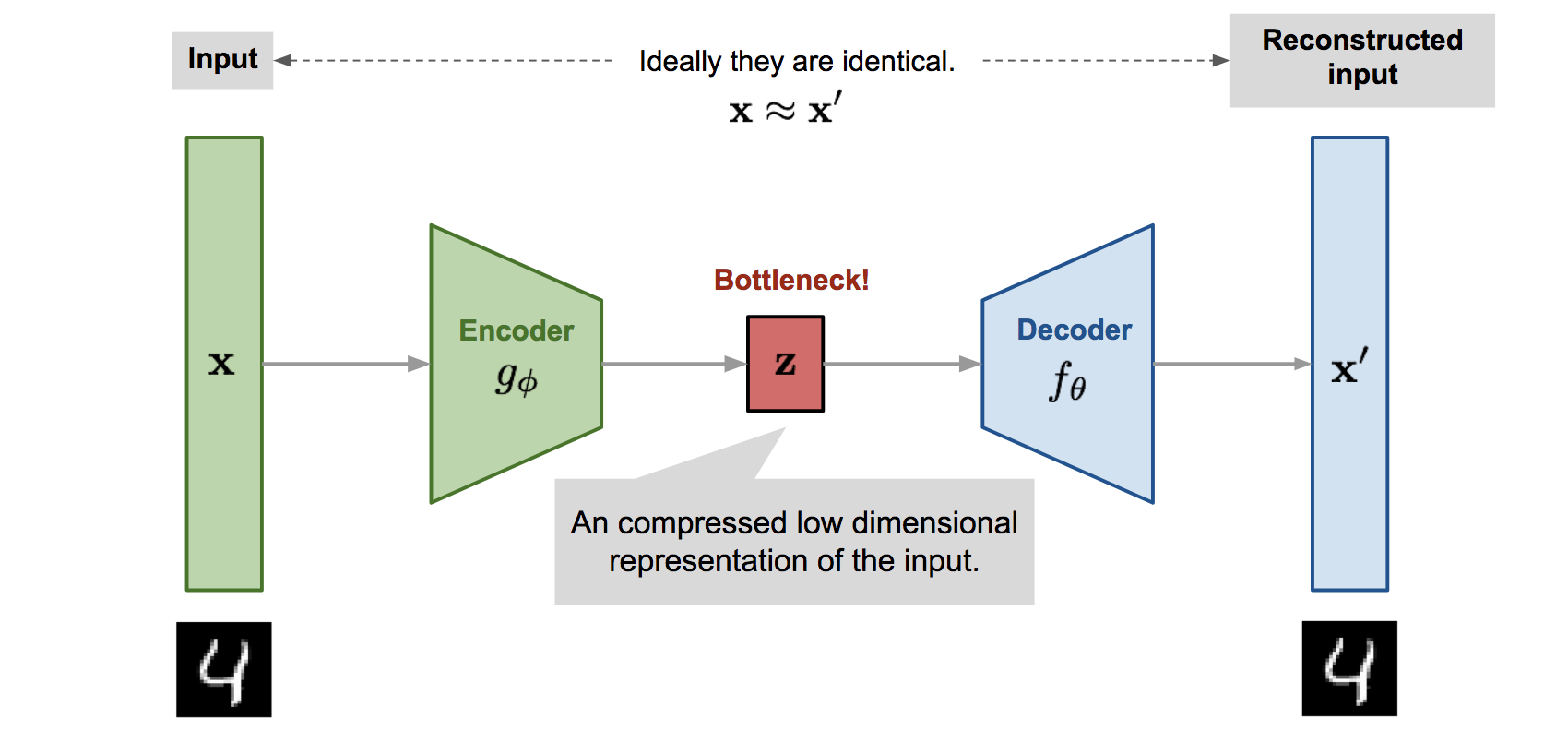
- 비지도학습으로 데이터를 효율적으로 축소 저장(encoding)하는 방법을 학습
- x - Encoder - z - Decoder - x hat
6. CNN ( Convolution Neural Network)
* 비정형 데이터를 Input data로 활용 하기 위해 고안된 방법 이미지의 가장 자리들은 이미지의 특징으로 보기 어렵다. 따라서 이부분을 activation 중 relu ( if x>0 x else x=0 ) 연산을 사용해 필요한 특징들만을 뽑고 filter를 통해 다시 한 번 특징들을 pooling을 통해 추출한다. 추출한 input data를 feature map이라 한다. 이 feature map을 다양한 형태로 변형하여 원하는 가중치를 구한다.
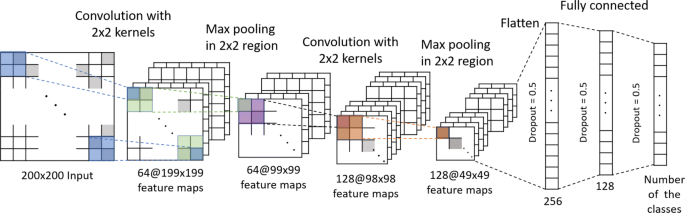
- 특정 위치에 있는 Feature Map화 진행(Encoder)
- Input과 Filter의 합성곱 연산을 통해 이미지의 특징을 추출
*Parameter: Filter size(5x5), Filter(128), Padding, Stride
7. RNN (Recurrent Neural Network)
* 순환 신경망
* 이전 step의 가중치를 현재 step의 가중치에 반영하여 진행하는 모델이다.
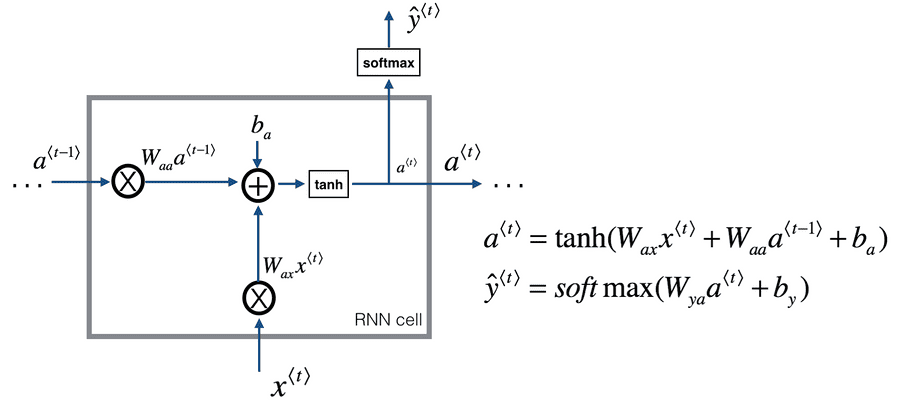
- 현재 단계의 정보가 다음 단계에 전달되어 output에 영향을 준다는것이 핵심
8. GNN (Graph Neural Network)
* 그래프 신경망 모델로 각 노드들이 가지고 있는 가중치에 대한 동형을 찾아주는 모델
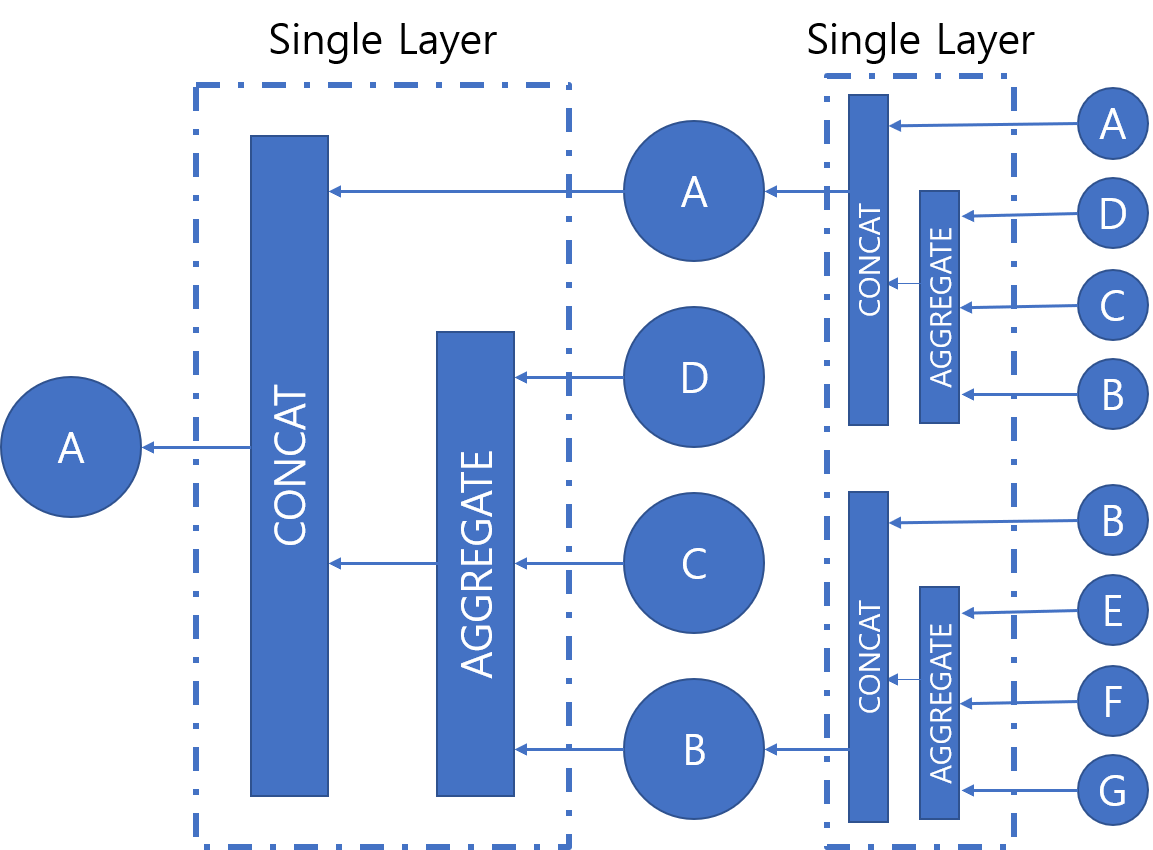
- GCN(Graph Convolution Network) : Graph Convolution Layer
- 노드 간 관계를 통해 지도 학습 이전에 라벨링에 사용
9. LSTM / GRU (Long Short Term Memory / Gated Recurrent Unit)
* LSTM : RNN에서의 연산을 축소시키고자 forget gate 와 reset gate를 도입
* GRU : RNN의 장기 의존성 문제를 해결하고 학습할 가중치가 LSTM에 비해 적다.
[9일차]
1. R studio에 Keras 설치 방법
Anaconda 설치 후 환경 변수 설정 후 R에서 패키지 실행
install.packages("keras")
library(keras)
library(reticulate)
use_python('/home/pc/anaconda3/envs/tf113/bin/python.exe')
library(keras)
model <- keras_model_sequential()
2. 베르누이 볼츠만 머신 (Restricted Boltzmann Machine Derivations)
- RBM이 기존의 이미지보다 조금 더 특징을 잘 표현 한다.

3. GAN
4. NLP
Count Based Word Representation - WordEmbedding,Word2Vec,fastText - BERT
'👾 Deep Learning' 카테고리의 다른 글
| [Image Classification] Kaggle - Birds 400 Species ResNet(1) (0) | 2022.05.15 |
|---|---|
| [Image Classification] Kaggle - Birds 400 Species (0) (0) | 2022.05.12 |
| [PyTorch] 기존 제공 model 불러오기 (0) | 2021.04.07 |
| [Pytorch] CNN - Conv2D (0) | 2021.04.02 |
| GTX 1660 super에 맞는 tensorflow, python, CUDA, Cudnn 버전 (4) | 2021.03.28 |
[8일차]
1. Deep Learning의 구조 소개
* Wn(Weight) : 회귀 분석의 회귀 계수와 비슷한 역할을 한다.
회귀 분석의 목적과 동일 하게 변수를 통해 Output을 찾는 식을 구하는 방식이다.
2. 다양한 Optimizer 소개
* 경사하강법(Gradient descent) :
- stochastic gradient descent : 값을 하나하나 넣어 갱신하기 때문에 시간이 오래걸린다는 단점이 있다.
- Batch gradient descent : Training set data의 가중치 평균을 이용하여 갱신
- Mini Batch : 일부 훈련자료의 무작위 복원 추출하여 Training set data의 가중치 평균을 갱신
3. Learning rate를 조절하는 방식
- ADAM : Momentum과 RMSProp의 혼합형으로서 기존 진행방향과 진행폭을 모두 반영
- Momentum : 기존 진행방향에 대한 관성을 기억함으로써 SGD의 방법의 진동폭을 완화
- AdaGrad : 기존 가중치 변화의 진행 폭을 고려하여 이를 반영하여 학습률을 변화
- RMSProp : AdaGrad의 gt가 무작정 커지는 것을 방지하기 위하여 고안된 방법
4. RBM(Restricted Boltzmann Machine)
볼츠만이 고안한 모델에 제프리 힌턴이 제약을 두어 사용을 하니 딥러닝의 신경망 모델과 유사성을 발견하여 위에 언급한 기울기가 0이 되어 극소점을 찾지 못하는 기울기 소실(Gradient Vanishing)을 해결
- 가시층과 은닉층으로 구성된 비지도 학습 신경망 모델
- 주어진 데이터들을 가장 잘 설명하는 특정 패턴을 높은 확률로 발생시킨다.
- 기준 MLE(Maximum Liklihood Estimate) 사용
5. Autoencoder
- 비지도학습으로 데이터를 효율적으로 축소 저장(encoding)하는 방법을 학습
- x - Encoder - z - Decoder - x hat
6. CNN ( Convolution Neural Network)
* 비정형 데이터를 Input data로 활용 하기 위해 고안된 방법 이미지의 가장 자리들은 이미지의 특징으로 보기 어렵다. 따라서 이부분을 activation 중 relu ( if x>0 x else x=0 ) 연산을 사용해 필요한 특징들만을 뽑고 filter를 통해 다시 한 번 특징들을 pooling을 통해 추출한다. 추출한 input data를 feature map이라 한다. 이 feature map을 다양한 형태로 변형하여 원하는 가중치를 구한다.
- 특정 위치에 있는 Feature Map화 진행(Encoder)
- Input과 Filter의 합성곱 연산을 통해 이미지의 특징을 추출
*Parameter: Filter size(5x5), Filter(128), Padding, Stride
7. RNN (Recurrent Neural Network)
* 순환 신경망
* 이전 step의 가중치를 현재 step의 가중치에 반영하여 진행하는 모델이다.
- 현재 단계의 정보가 다음 단계에 전달되어 output에 영향을 준다는것이 핵심
8. GNN (Graph Neural Network)
* 그래프 신경망 모델로 각 노드들이 가지고 있는 가중치에 대한 동형을 찾아주는 모델
- GCN(Graph Convolution Network) : Graph Convolution Layer
- 노드 간 관계를 통해 지도 학습 이전에 라벨링에 사용
9. LSTM / GRU (Long Short Term Memory / Gated Recurrent Unit)
* LSTM : RNN에서의 연산을 축소시키고자 forget gate 와 reset gate를 도입
* GRU : RNN의 장기 의존성 문제를 해결하고 학습할 가중치가 LSTM에 비해 적다.
[9일차]
1. R studio에 Keras 설치 방법
Anaconda 설치 후 환경 변수 설정 후 R에서 패키지 실행
install.packages("keras")
library(keras)
library(reticulate)
use_python('/home/pc/anaconda3/envs/tf113/bin/python.exe')
library(keras)
model <- keras_model_sequential()
2. 베르누이 볼츠만 머신 (Restricted Boltzmann Machine Derivations)
- RBM이 기존의 이미지보다 조금 더 특징을 잘 표현 한다.
3. GAN
4. NLP
Count Based Word Representation - WordEmbedding,Word2Vec,fastText - BERT
'👾 Deep Learning' 카테고리의 다른 글
| [Image Classification] Kaggle - Birds 400 Species ResNet(1) (0) | 2022.05.15 |
|---|---|
| [Image Classification] Kaggle - Birds 400 Species (0) (0) | 2022.05.12 |
| [PyTorch] 기존 제공 model 불러오기 (0) | 2021.04.07 |
| [Pytorch] CNN - Conv2D (0) | 2021.04.02 |
| GTX 1660 super에 맞는 tensorflow, python, CUDA, Cudnn 버전 (4) | 2021.03.28 |