
Adam
Adam: Adaptive moment estimation
Adam = RMSprop + Momentum
Momentum : gradient descent 시 최소점을 찾기 위해 모든 스텝을 밟는 것이 아닌 스텝을 건너 뛴다.
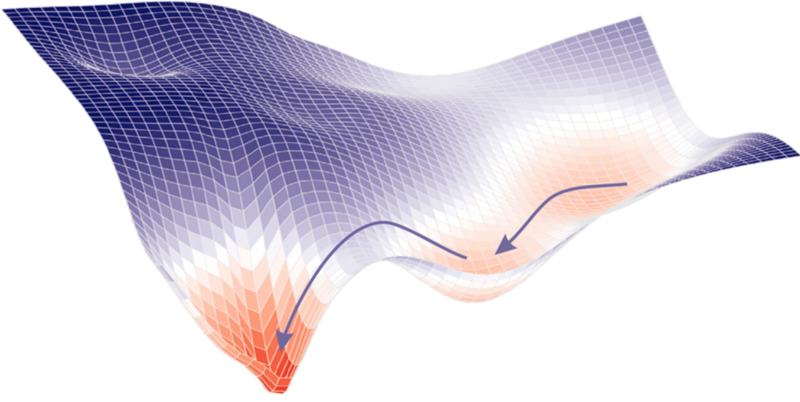
Stochastic gradient descent(SGD)
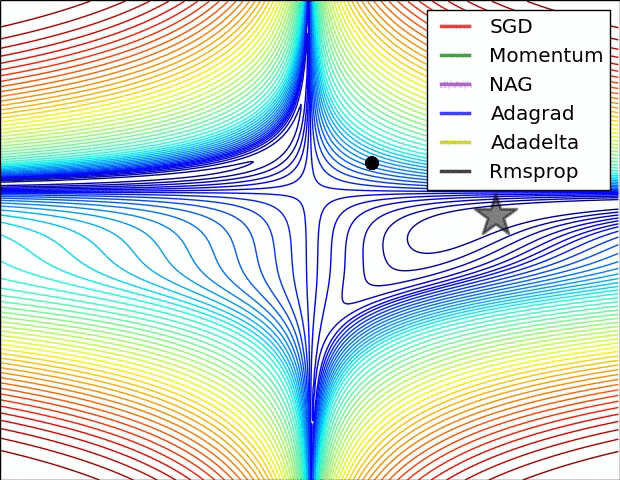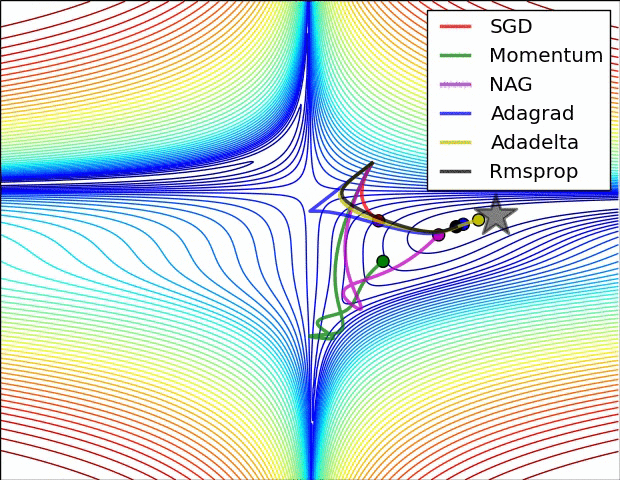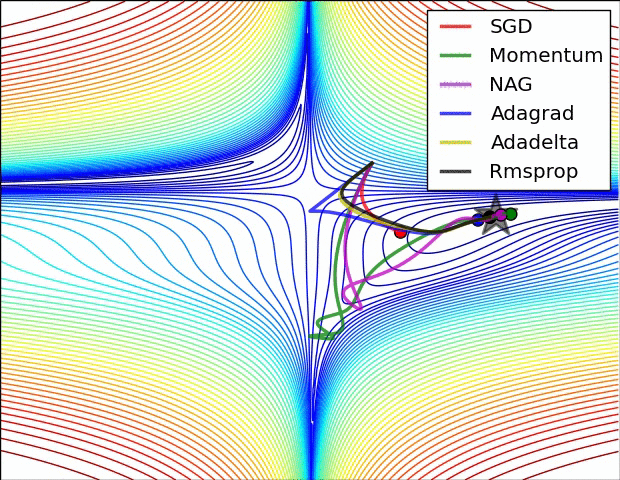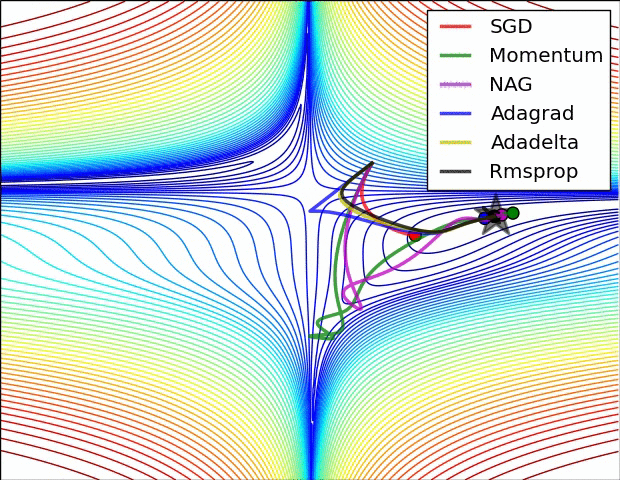
Adagrad
It makes big updates for infrequent parameters and small updates for frequent parameters. For this reason, it is well-suited for dealing with sparse data.
The main benefit of Adagrad is that we don’t need to tune the learning rate manually. Most implementations use a default value of 0.01 and leave it at that.
Disadvantage —
Its main weakness is that its learning rate is always Decreasing and decaying.
AdaDelta
It is an extension of AdaGrad which tends to remove the decaying learning Rate problem of it.
Another thing with AdaDelta is that we don’t even need to set a default learning rate.
'👾 Deep Learning' 카테고리의 다른 글
| [Pytorch] CNN - Conv2D (0) | 2021.04.02 |
|---|---|
| GTX 1660 super에 맞는 tensorflow, python, CUDA, Cudnn 버전 (4) | 2021.03.28 |
| 손실 함수 (loss function) (0) | 2021.03.07 |
| tensorboard 사용법, gpu 할당 메모리 관리 (0) | 2021.03.06 |
| OSError: [WinError 127] 지정된 프로시저를 찾을 수 없습니다. Error loading \\torch\\lib\\*_ops_gpu.dll or one of its dependencies. (0) | 2021.03.06 |
Adam
Adam: Adaptive moment estimation
Adam = RMSprop + Momentum
Momentum : gradient descent 시 최소점을 찾기 위해 모든 스텝을 밟는 것이 아닌 스텝을 건너 뛴다.
Stochastic gradient descent(SGD)
Adagrad
It makes big updates for infrequent parameters and small updates for frequent parameters. For this reason, it is well-suited for dealing with sparse data.
The main benefit of Adagrad is that we don’t need to tune the learning rate manually. Most implementations use a default value of 0.01 and leave it at that.
Disadvantage —
Its main weakness is that its learning rate is always Decreasing and decaying.
AdaDelta
It is an extension of AdaGrad which tends to remove the decaying learning Rate problem of it.
Another thing with AdaDelta is that we don’t even need to set a default learning rate.
'👾 Deep Learning' 카테고리의 다른 글
| [Pytorch] CNN - Conv2D (0) | 2021.04.02 |
|---|---|
| GTX 1660 super에 맞는 tensorflow, python, CUDA, Cudnn 버전 (4) | 2021.03.28 |
| 손실 함수 (loss function) (0) | 2021.03.07 |
| tensorboard 사용법, gpu 할당 메모리 관리 (0) | 2021.03.06 |
| OSError: [WinError 127] 지정된 프로시저를 찾을 수 없습니다. Error loading \\torch\\lib\\*_ops_gpu.dll or one of its dependencies. (0) | 2021.03.06 |