
https://arxiv.org/abs/2212.04356
Robust Speech Recognition via Large-Scale Weak Supervision
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard
arxiv.org
Robust Speech Recognition via Large-Scale Weak Supervision
Abstract & Introduction
680,000 시간의 다국어 학습을 진행 시 fine-tuning 없이 zero-shot transfer benchmark 수준의 결과를 얻을 수 있다. 또한 사람에 근접한 accuracy와 robustness를 가지게 됨.
기존의 데이터 학습 방식은 Wave2Vec을 이용한 비지도 학습 방식이다. 사람의 labeling 없이 대규모 데이터셋을 생산하여 많은 양의 데이터 학습을 진행시키므로 data setting에 대한 부담을 줄였다. 하지만 이러한 학습 방법은 고품질 데이터에 대한 표현만 좋을 뿐 unsupervised data에 대한 decoder mapping은 성능이 떨어진다.
기존의 방법은 fine-tuning 시 복잡한 작업을 실무자가 진행해야한다.(risk 추가, fine-tuning시 성능이 잘 안 나올 수도 있음)
머신 러닝 method는 같은 데이터에 대한 학습 패턴을 찾는다. 그러나 outlier(brittle, spurious)와 정상치와 다른 데이터셋에 의해 학습이 잘되지 않는다.
Radford et al
- ImageNet classification에서 같은 이미지에 대한 클래스를 7가지 다른 분류로 세분화했을 때 acc 9.2% 증가 시켰다.
large-scale에 대한 편향을 가진 dataset을 학습 시키고 다시 새로운 데이터를 학습시킬 때 high-quality dataset의 몇 배나 되고 이전 학습보다 적은 양의 학습을 하게 된다. (올바른 학습 미미)
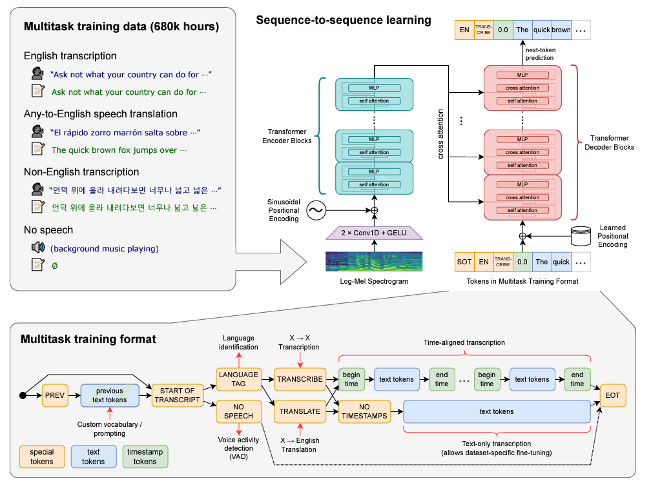
OpenAI 연구진은 데이터 inbalanced 문제를 좁히기 위해 68,000시간의 labeling이 된 오디오 데이터를 사용했다.
- Whisper: *weakly supervised speech recognition
영어뿐만아니라 117,000 h 96개의 언어 dataset, 125,000h X→en 의 영문 변환 번역 dataset 학습
일반적으로 large-model에 있어 다국어 학습은 단점이나 장점 둘 다 없다.
최근 weakly supervised pre-training이 저평가됨에 있어 lage-scale dataset을 학습 시 self-supervision 또는 self-trainig에 대한 고찰이 필요하다.
음성 언어 모델링 연구에 기여하기 위해 OpenAI whisper를 공개함.
Approach
Data Processing
Trend에 따라 ML system의 web-scale text를 사용하고 최소한의 데이터 전처리를 진행
기존의 방식과 다르게 Significant standardization(표준화) 없이 seq2seq model로 audio data와 transcript pair 데이터를 만듦
Naturalistic transcriptions을 생성하기 위한 Text 정규화를 하지 않아 pipeline이 간소화된다.
구축 결과 environments, recording setups, speakers, languages 별 다 양한 데이터셋이 구축되었다.
다양한 audio quality는 model 학습에 도움이 되지만 transcript quality에는 거의 되지 않는다.
데이터 검증 결과, 원 데이터에 수준 이하의 데이터들이 많이 발견되었다.
인터넷에 있는 많은 transcript 데이터는 실제로 사람이 생성한 것이 아니라 기존 ASR의 결과물이 많았고 인간과 기계가 생성한 데이터를 학습할 경우 학습 성능을 크게 저하시킨다는 연구 결과가 있다. (https://arxiv.org/abs/2109.07740)
기계음성 분류를 위해 heuristics 개발 / 기존의 많은 ASR은 복잡한 구두점(. , ! ?) 단락과 같은 서식 공백, 대문자 등 오디오 vocab에 쓰기 어려운 경우가 정규화를 통한 제한된 집합의 문자언어만 사용했다.
많은 ASR 시스템에는 어느 정도의 텍스트 정규화가 진행되지만 단순하거나 rule-base로 처리하는 경우가 많다.
Language detector(VoxLingua107, proto-type dataset) 사용
- CLD2에 따라 음성 언어가 script 결과와 일치하는지 비교 (일치하지 않으면 train 제외)
- X->en (음성 번역 훈련 예제)로 데이터 세트에 추가한다.
- fuzzy de-duping을 사용해 transcript를 한번 더 정제 (중복 방지, 기계 생성 데이터 제거)
- 오디오 파일 30초 segment로 나누고 해당 시간 내에서 발생하는 transcript 하위 집합과 pair 진행 (audiofile_1 – transcript_1, audiofile_2 – transcript_2 ..)
음성이 없는 데이터는 음성 활동 감지를 위한 훈련 데이터로 활용
이 과정에서 데이터 오류율을 집계하고 품질이 낮은 데이터를 식별하고 제거, 수동작업
스크립트와 음성 정렬이 잘못되었거나 필터링에 걸리지 못한 이상 데이터 대량 발견
오염 방지를 위해 데이터 중복 제거 + TED-LIUM 3 수준의 전처리 진행
Model
연구 결과에 혼선이 가지 않게 기성 모델 아키텍쳐를 사용(비판 요소 새로운 모델이 아닌 전처리를 중점으로 다룸, human detect filter)
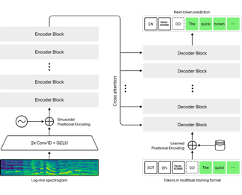
검증된 아키텍처 Transformer(Attention Is All You Need) encoder-decoder를 사용함.
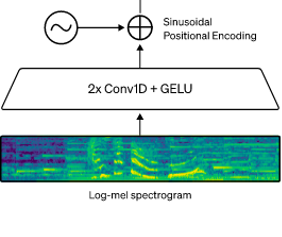
모든 오디오는 16,000HZ로 resampling -> 80 channel -> log-mel spectrogram
0.010 sec 간격으로 표현된 mel spectogram을 25mm/sec 단위로 channel 계산 (25 mm/sec - 10 mm/sec )
Normalization - Standardization -1~1
Conv1D(filter=3) + Conv1D(filter=3, stride=2) & GELU
Sinusoidal position embeddings (=positional encoding)
N x encoder Block -> N x decoder Block

Multitask Format
분절된 audio가 어떤 단어가 발화되었는지 예측하는 것이 speech recognition 분야에서 주로 다루는 핵심 문제이지만, 이 문제만이 있는 것은 아니다.
현 speech recognition에는 개선해야할 부분이 더 있다.
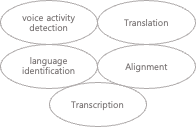
1. voice activity detection (음성 활동 감지)
2. speaker diarization (화자 분할)
3. inverse text normalization (ITN, 삼십일분 -> 31분)
이 문제를 개별적으로 처리하는 경우가 많아 모델이 상대적으로 복잡해 진다.
Whisper는 단일 모델로 이 문제를 해결함
모델의 인터페이스에서 수행하는 Task
1. Transcription (전사)
2. Translation (번역)
3. voice activity detection (음성 활동 감지)
4. Alignment (위치 조정)
5. language identification (언어 식별)
이 경우 단일 모델에서 one to many 작업이 불가피해 resource가 필수로 필요하다.
조건부 정보(conditional information)를 input token으로 Decoder에 전달

Training Details

Experiments
Zero-shot Evaluation
Evaluation Metrics
Speech recognition 연구에서 통상 사용하는 metric WER(word error rate) 사용
* 그러나 WER은 string edit distance(levenshtein distance)를 기반으로 차이를 계산해 transcript의 특성이 무시됨
* 사람이 정확하다고 판단하는 transcript를 WER은 작은 차이로 크게 계산할 가능성이 높음
* 모든 transcript에서 문제가 되지만 특정 dataset transcript에서 whisper와 같은 zero-shot 모델에서 특히 심각하게 작용
인간의 판단과 더 잘 맞는 metric을 개발하는 것 또한 하나의 연구 분야이다. 하지만 음성 인식에 널리 사용되는 것은 아직 없음
WER 계산 전에 text를 광범위하게 표준화(standardization)하여 정답 label간의 차이를 최소화함
Whisper의 text normalizer(4.4)는 반복적인 수동 manual을 통해 개발
WER이 사소한 차이로 인해 Whisper 모델의 loss를 올리는 것을 패턴을 통해 찾음
몇 몇 dataset에서 공백이 있는 단어의 축약어를 분리하는 결과 WER 50% 하락을 관찰
코드 공개 (https://github.com/openai/whisper/tree/main/whisper/normalizers)
English Speech Recognition
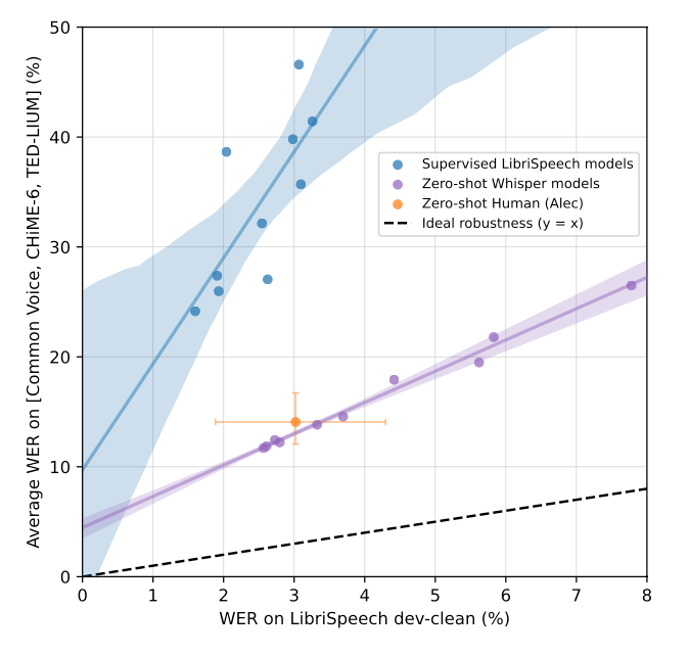
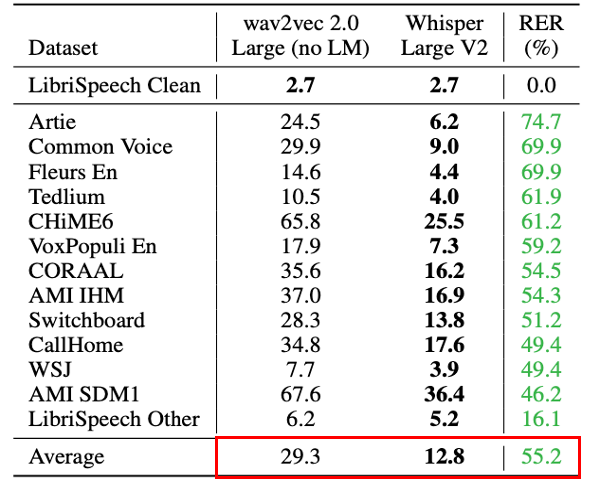
Multi-lingual Speech Recognition
다국어 음성 인식을 비교하기 위해 두가지 low-data benchmark 사용
- MLS(Multilingual LibriSpeech) (Pratap et al)
- VoxPopuli(Wang et al)
Whisper zero-shot setting에서 MLS, outperforming XLS-R, mSLAM, Maestro dataset에서 좋은 성능을 보임
- Text standardizer를 사용해 SOTA 모델과 비교할 수 없다는 것을 유의
- VoxPopuli dataset에서 whisper는 이전 작업보다 성능이 현저히 떨어짐, VP-10K+FT에서만 좋은 성능
- Voxpopuli에서 Whisper 모델의 성능이 낮게 나온 것은 다른 모델들이 unsupervised pre-training data 때 이 dataset을 사용하고 dataset 학습에 있어 supervised data를 더 많이 사용해 fine-tuning에 이점이 있을 것이라 봄
- MLS는 언어당 10시간의 train data를 가지고 있는 반면, VoxPopuli는 언어당 평균학습 데이터의 양이 약 10배 더 많다.

이 두 benchmark는 15개의 언어만 포함하며, 대부분이 인도-유럽권에 속하고 리소스가 많이 필요한 언어이기 때문에 범위가 좁음
Whisper를 좀더 broad하게 성능 측정을 위해 Fleurs dataset을 사용
- 주어진 Train data의 양과 zero-shot downsteam performance의 관계를 연구
- Fig3 log(WER)와 log(언어별 학습 데이터의 양) 관계를 보면 coefficient 0.83으로 강한 상관 관계가 있음을 알 수 있음
- 학습 data가 16배 증가 할 때마다 WER이 절반으로 줄어들 것으로 추정
- 또한 예측이 가장 떨어지는 히브리어(HE), 탈로그어(TE), 중국어(ZH), 한국어(KO) 등은 인도-유럽 언어와 더 멀리 떨어져 있고 unique scripts를 가진 것으로 나타남
- Linguastic distance(언어적 거리)
- Our byte level BPE tokenizer poor match (Tokenizer 성능차이)
- Variations data quality (데이터 품질 차이)
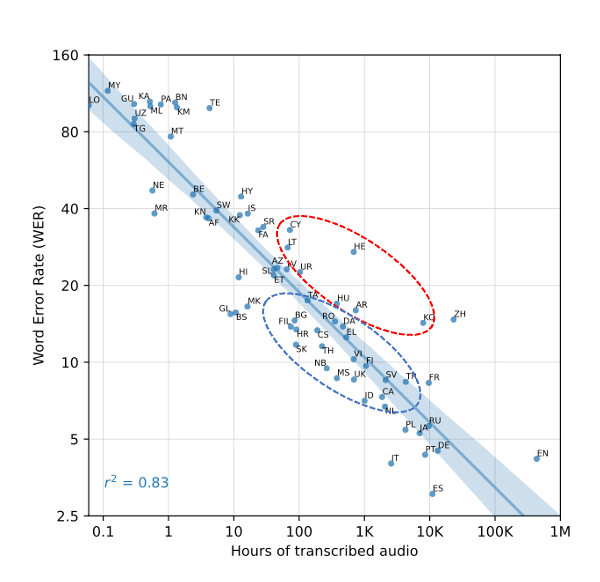
Translation
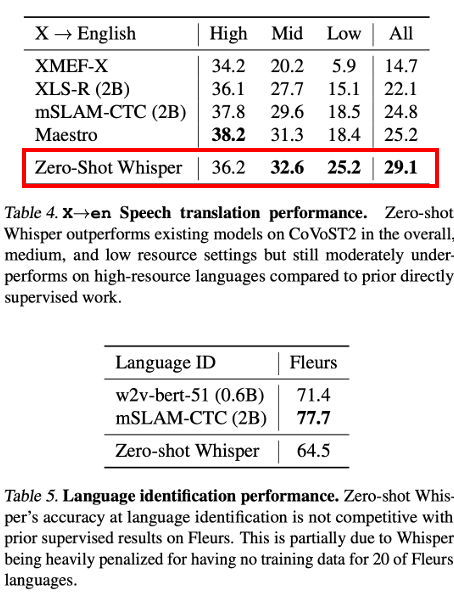
CoVoST2 dataset(X→en)의 성능을 측정해 whisper의 translate performance 연구
선행 language detect 모델 Maestro, mSLAM, XLS-R 비교
Whisper는 CoVoST2 dataset을 사용하지 않고 zero-shot 29.1 BLEU achieve
- Whisper는 68,000 시간의 dataset(X→en) 학습이는 CoVoST2 861시간과 비교하면 큰 차이가 있음
Whisper의 검증은 zero-shot이기 때문에 CoVoST2에서도 적은 resource로 mSLAM보다 6.7 BLEU 개선됨
High resource model에서는 Maestro, mSLAM보다 개선되지 않았음
Language identification performance
- Fleurs dataset 결과 whisper는 Fleurs의 20개 언어가 제외됨에 따라 선행 모델에 비해 낮게 나옴
언어별 translate train data의 양과 Fleurs zero-shot BLEU 점수 간의 상관관계 시각화
Train data의 증가함에 따라 개선되는 추세는 분명하지만, WER의 상관관계와 비교했을 때 0.83보다 훨씬 낮은 0.24에 불과
- 부분적으로 음성 언어 식별 오류로 인해 train data가 noise가 많기 때문인 것으로 추정
- 웨일즈(CY) 언어를 예를 들면 9000시간의 translate data를 train 했음에도 전체 translate 보다 낮은 13 BLEU performance를 보이고 전체 4위를 차지하며 프랑스어, 스페인어, 러시아어 등 세계에서 가장 많이 사용되는 언어보다 앞서 있음
- 웨일즈 언어를 조사해보니 대부분의 data에 영어 caption이 있고 indentification system에 의해 영어 audio가 웨일즈 언어에 잘못 포함되어있는 data가 있음

Language Identification
Evaluate dataset : Fleurs
pretrained 되어 있지 않으므로 SOTA 대비 13.6% 낮은 성능 보유
Whisper는 Fleues에 포함된 102개의 언어 중 20개의 언어가 포함되어 있지 않음
다른 SOTA 모델이 80.4% 상한 선을 넘었기 때문에 20개 언어를 제외하고 다른 모델과 비교하기는 힘듦
Robustness to Additive Noise
Test Dataset : LibriSpeech
Model : 14개의 LibriSpeech Trained Model, noise robustness of Whisper models
Audio Degradation Toolbox(오디오 품질 저하) program을 사용
White noise & pub noise 추가
- Pub noise : 주변 소음과 불확실한 대화, 시끄러운 환경, 레스토랑이나 펍 환경
14개의 모델 사이 12개의 모델은 LibriSpeech에 대해 pre-trainded model 또는 fine-tuning 된 모델이며, 나머지 두개의 모델은 SpeechStew와 같은 선행 모델과 유사한 혼합 dataset에 대해 학습된 NVIDIA STT models임
주어진 signal 대비 signal-to-noise 비율(SNR)은 signal power를 기반으로 계산됨
- SNR = P_sig/P_noise
Noise(SNR) 증가에 따른 WER
- 저잡음(40dB SNR)에서 whisper 능가(LibriSpeech 기반 train)
- 14개의 모델은 10dB 미만에서 Whisper보다 성능이 나빠짐
- 이는 whisper의 Robustness to Additive Noise 성능

Long-form Transcription
Chunk size : 30초 (초과 데이터 사용 불가)
Chunk size에 대한 ISSUE
- 짧은 발화 audio로 구성된 train dataset에서는 문제가 되지 않지만 몇분 몇 시간 분량의 audio를 텍스트로 변환해야하는 작업에서는 문제가 발생
- 30초 분량의 audio segment를 연속으로 transcript하고 model이 예측한 timestamp에 따라 window를 이동하는 방식으로 긴 audio의 buffering을 transcript하는 전략
긴 audio를 안정적으로 transcript하기 위해 모델 예측의 반복성(reptitiveness)과 로그 확률(log probability)을 사용
이 과정에서 beam search와 temperature scheduling이 중요 (4.5)
긴 transcription에 대한 performance 측정하기 위해 7개의 dataset으로 구성된 다양한 길이의 recording 상태를 검증(다양한 데이터 분포를 가지도록 구성)
- TED-LIUM3의 full-length TED 강연
- The Late Show Jargon-laden(with Stephen Colbert)
- Videos/podcasts
- online blogs (Rev16 and Kincaid46)
- recordings of earnings calls
- the full-length interviews from the Corpus of Regional African American Language (CORAAL)
- Full detail longform dataset Appendix A
Result


'👾 Deep Learning' 카테고리의 다른 글
| [Forensic Architecture] Justice Vision / "Vision으로 정의 구현" (0) | 2023.11.18 |
|---|---|
| [DATA] ACNE04 Dataset download(여드름 병변 검출) (0) | 2023.10.16 |
| Demand forecasting in logistics (0) | 2023.07.25 |
| CM3leon(.Meta) (0) | 2023.07.16 |
| [CS324] Introduction (0) | 2023.07.03 |
https://arxiv.org/abs/2212.04356
Robust Speech Recognition via Large-Scale Weak Supervision
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard
arxiv.org
Robust Speech Recognition via Large-Scale Weak Supervision
Abstract & Introduction
680,000 시간의 다국어 학습을 진행 시 fine-tuning 없이 zero-shot transfer benchmark 수준의 결과를 얻을 수 있다. 또한 사람에 근접한 accuracy와 robustness를 가지게 됨.
기존의 데이터 학습 방식은 Wave2Vec을 이용한 비지도 학습 방식이다. 사람의 labeling 없이 대규모 데이터셋을 생산하여 많은 양의 데이터 학습을 진행시키므로 data setting에 대한 부담을 줄였다. 하지만 이러한 학습 방법은 고품질 데이터에 대한 표현만 좋을 뿐 unsupervised data에 대한 decoder mapping은 성능이 떨어진다.
기존의 방법은 fine-tuning 시 복잡한 작업을 실무자가 진행해야한다.(risk 추가, fine-tuning시 성능이 잘 안 나올 수도 있음)
머신 러닝 method는 같은 데이터에 대한 학습 패턴을 찾는다. 그러나 outlier(brittle, spurious)와 정상치와 다른 데이터셋에 의해 학습이 잘되지 않는다.
Radford et al
- ImageNet classification에서 같은 이미지에 대한 클래스를 7가지 다른 분류로 세분화했을 때 acc 9.2% 증가 시켰다.
large-scale에 대한 편향을 가진 dataset을 학습 시키고 다시 새로운 데이터를 학습시킬 때 high-quality dataset의 몇 배나 되고 이전 학습보다 적은 양의 학습을 하게 된다. (올바른 학습 미미)
OpenAI 연구진은 데이터 inbalanced 문제를 좁히기 위해 68,000시간의 labeling이 된 오디오 데이터를 사용했다.
- Whisper: *weakly supervised speech recognition
영어뿐만아니라 117,000 h 96개의 언어 dataset, 125,000h X→en 의 영문 변환 번역 dataset 학습
일반적으로 large-model에 있어 다국어 학습은 단점이나 장점 둘 다 없다.
최근 weakly supervised pre-training이 저평가됨에 있어 lage-scale dataset을 학습 시 self-supervision 또는 self-trainig에 대한 고찰이 필요하다.
음성 언어 모델링 연구에 기여하기 위해 OpenAI whisper를 공개함.
Approach
Data Processing
Trend에 따라 ML system의 web-scale text를 사용하고 최소한의 데이터 전처리를 진행
기존의 방식과 다르게 Significant standardization(표준화) 없이 seq2seq model로 audio data와 transcript pair 데이터를 만듦
Naturalistic transcriptions을 생성하기 위한 Text 정규화를 하지 않아 pipeline이 간소화된다.
구축 결과 environments, recording setups, speakers, languages 별 다 양한 데이터셋이 구축되었다.
다양한 audio quality는 model 학습에 도움이 되지만 transcript quality에는 거의 되지 않는다.
데이터 검증 결과, 원 데이터에 수준 이하의 데이터들이 많이 발견되었다.
인터넷에 있는 많은 transcript 데이터는 실제로 사람이 생성한 것이 아니라 기존 ASR의 결과물이 많았고 인간과 기계가 생성한 데이터를 학습할 경우 학습 성능을 크게 저하시킨다는 연구 결과가 있다. (https://arxiv.org/abs/2109.07740)
기계음성 분류를 위해 heuristics 개발 / 기존의 많은 ASR은 복잡한 구두점(. , ! ?) 단락과 같은 서식 공백, 대문자 등 오디오 vocab에 쓰기 어려운 경우가 정규화를 통한 제한된 집합의 문자언어만 사용했다.
많은 ASR 시스템에는 어느 정도의 텍스트 정규화가 진행되지만 단순하거나 rule-base로 처리하는 경우가 많다.
Language detector(VoxLingua107, proto-type dataset) 사용
- CLD2에 따라 음성 언어가 script 결과와 일치하는지 비교 (일치하지 않으면 train 제외)
- X->en (음성 번역 훈련 예제)로 데이터 세트에 추가한다.
- fuzzy de-duping을 사용해 transcript를 한번 더 정제 (중복 방지, 기계 생성 데이터 제거)
- 오디오 파일 30초 segment로 나누고 해당 시간 내에서 발생하는 transcript 하위 집합과 pair 진행 (audiofile_1 – transcript_1, audiofile_2 – transcript_2 ..)
음성이 없는 데이터는 음성 활동 감지를 위한 훈련 데이터로 활용
이 과정에서 데이터 오류율을 집계하고 품질이 낮은 데이터를 식별하고 제거, 수동작업
스크립트와 음성 정렬이 잘못되었거나 필터링에 걸리지 못한 이상 데이터 대량 발견
오염 방지를 위해 데이터 중복 제거 + TED-LIUM 3 수준의 전처리 진행
Model
연구 결과에 혼선이 가지 않게 기성 모델 아키텍쳐를 사용(비판 요소 새로운 모델이 아닌 전처리를 중점으로 다룸, human detect filter)
검증된 아키텍처 Transformer(Attention Is All You Need) encoder-decoder를 사용함.
모든 오디오는 16,000HZ로 resampling -> 80 channel -> log-mel spectrogram
0.010 sec 간격으로 표현된 mel spectogram을 25mm/sec 단위로 channel 계산 (25 mm/sec - 10 mm/sec )
Normalization - Standardization -1~1
Conv1D(filter=3) + Conv1D(filter=3, stride=2) & GELU
Sinusoidal position embeddings (=positional encoding)
N x encoder Block -> N x decoder Block
Multitask Format
분절된 audio가 어떤 단어가 발화되었는지 예측하는 것이 speech recognition 분야에서 주로 다루는 핵심 문제이지만, 이 문제만이 있는 것은 아니다.
현 speech recognition에는 개선해야할 부분이 더 있다.
1. voice activity detection (음성 활동 감지)
2. speaker diarization (화자 분할)
3. inverse text normalization (ITN, 삼십일분 -> 31분)
이 문제를 개별적으로 처리하는 경우가 많아 모델이 상대적으로 복잡해 진다.
Whisper는 단일 모델로 이 문제를 해결함
모델의 인터페이스에서 수행하는 Task
1. Transcription (전사)
2. Translation (번역)
3. voice activity detection (음성 활동 감지)
4. Alignment (위치 조정)
5. language identification (언어 식별)
이 경우 단일 모델에서 one to many 작업이 불가피해 resource가 필수로 필요하다.
조건부 정보(conditional information)를 input token으로 Decoder에 전달
Training Details
Experiments
Zero-shot Evaluation
Evaluation Metrics
Speech recognition 연구에서 통상 사용하는 metric WER(word error rate) 사용
* 그러나 WER은 string edit distance(levenshtein distance)를 기반으로 차이를 계산해 transcript의 특성이 무시됨
* 사람이 정확하다고 판단하는 transcript를 WER은 작은 차이로 크게 계산할 가능성이 높음
* 모든 transcript에서 문제가 되지만 특정 dataset transcript에서 whisper와 같은 zero-shot 모델에서 특히 심각하게 작용
인간의 판단과 더 잘 맞는 metric을 개발하는 것 또한 하나의 연구 분야이다. 하지만 음성 인식에 널리 사용되는 것은 아직 없음
WER 계산 전에 text를 광범위하게 표준화(standardization)하여 정답 label간의 차이를 최소화함
Whisper의 text normalizer(4.4)는 반복적인 수동 manual을 통해 개발
WER이 사소한 차이로 인해 Whisper 모델의 loss를 올리는 것을 패턴을 통해 찾음
몇 몇 dataset에서 공백이 있는 단어의 축약어를 분리하는 결과 WER 50% 하락을 관찰
코드 공개 (https://github.com/openai/whisper/tree/main/whisper/normalizers)
English Speech Recognition
Multi-lingual Speech Recognition
다국어 음성 인식을 비교하기 위해 두가지 low-data benchmark 사용
- MLS(Multilingual LibriSpeech) (Pratap et al)
- VoxPopuli(Wang et al)
Whisper zero-shot setting에서 MLS, outperforming XLS-R, mSLAM, Maestro dataset에서 좋은 성능을 보임
- Text standardizer를 사용해 SOTA 모델과 비교할 수 없다는 것을 유의
- VoxPopuli dataset에서 whisper는 이전 작업보다 성능이 현저히 떨어짐, VP-10K+FT에서만 좋은 성능
- Voxpopuli에서 Whisper 모델의 성능이 낮게 나온 것은 다른 모델들이 unsupervised pre-training data 때 이 dataset을 사용하고 dataset 학습에 있어 supervised data를 더 많이 사용해 fine-tuning에 이점이 있을 것이라 봄
- MLS는 언어당 10시간의 train data를 가지고 있는 반면, VoxPopuli는 언어당 평균학습 데이터의 양이 약 10배 더 많다.
이 두 benchmark는 15개의 언어만 포함하며, 대부분이 인도-유럽권에 속하고 리소스가 많이 필요한 언어이기 때문에 범위가 좁음
Whisper를 좀더 broad하게 성능 측정을 위해 Fleurs dataset을 사용
- 주어진 Train data의 양과 zero-shot downsteam performance의 관계를 연구
- Fig3 log(WER)와 log(언어별 학습 데이터의 양) 관계를 보면 coefficient 0.83으로 강한 상관 관계가 있음을 알 수 있음
- 학습 data가 16배 증가 할 때마다 WER이 절반으로 줄어들 것으로 추정
- 또한 예측이 가장 떨어지는 히브리어(HE), 탈로그어(TE), 중국어(ZH), 한국어(KO) 등은 인도-유럽 언어와 더 멀리 떨어져 있고 unique scripts를 가진 것으로 나타남
- Linguastic distance(언어적 거리)
- Our byte level BPE tokenizer poor match (Tokenizer 성능차이)
- Variations data quality (데이터 품질 차이)
Translation
CoVoST2 dataset(X→en)의 성능을 측정해 whisper의 translate performance 연구
선행 language detect 모델 Maestro, mSLAM, XLS-R 비교
Whisper는 CoVoST2 dataset을 사용하지 않고 zero-shot 29.1 BLEU achieve
- Whisper는 68,000 시간의 dataset(X→en) 학습이는 CoVoST2 861시간과 비교하면 큰 차이가 있음
Whisper의 검증은 zero-shot이기 때문에 CoVoST2에서도 적은 resource로 mSLAM보다 6.7 BLEU 개선됨
High resource model에서는 Maestro, mSLAM보다 개선되지 않았음
Language identification performance
- Fleurs dataset 결과 whisper는 Fleurs의 20개 언어가 제외됨에 따라 선행 모델에 비해 낮게 나옴
언어별 translate train data의 양과 Fleurs zero-shot BLEU 점수 간의 상관관계 시각화
Train data의 증가함에 따라 개선되는 추세는 분명하지만, WER의 상관관계와 비교했을 때 0.83보다 훨씬 낮은 0.24에 불과
- 부분적으로 음성 언어 식별 오류로 인해 train data가 noise가 많기 때문인 것으로 추정
- 웨일즈(CY) 언어를 예를 들면 9000시간의 translate data를 train 했음에도 전체 translate 보다 낮은 13 BLEU performance를 보이고 전체 4위를 차지하며 프랑스어, 스페인어, 러시아어 등 세계에서 가장 많이 사용되는 언어보다 앞서 있음
- 웨일즈 언어를 조사해보니 대부분의 data에 영어 caption이 있고 indentification system에 의해 영어 audio가 웨일즈 언어에 잘못 포함되어있는 data가 있음
Language Identification
Evaluate dataset : Fleurs
pretrained 되어 있지 않으므로 SOTA 대비 13.6% 낮은 성능 보유
Whisper는 Fleues에 포함된 102개의 언어 중 20개의 언어가 포함되어 있지 않음
다른 SOTA 모델이 80.4% 상한 선을 넘었기 때문에 20개 언어를 제외하고 다른 모델과 비교하기는 힘듦
Robustness to Additive Noise
Test Dataset : LibriSpeech
Model : 14개의 LibriSpeech Trained Model, noise robustness of Whisper models
Audio Degradation Toolbox(오디오 품질 저하) program을 사용
White noise & pub noise 추가
- Pub noise : 주변 소음과 불확실한 대화, 시끄러운 환경, 레스토랑이나 펍 환경
14개의 모델 사이 12개의 모델은 LibriSpeech에 대해 pre-trainded model 또는 fine-tuning 된 모델이며, 나머지 두개의 모델은 SpeechStew와 같은 선행 모델과 유사한 혼합 dataset에 대해 학습된 NVIDIA STT models임
주어진 signal 대비 signal-to-noise 비율(SNR)은 signal power를 기반으로 계산됨
- SNR = P_sig/P_noise
Noise(SNR) 증가에 따른 WER
- 저잡음(40dB SNR)에서 whisper 능가(LibriSpeech 기반 train)
- 14개의 모델은 10dB 미만에서 Whisper보다 성능이 나빠짐
- 이는 whisper의 Robustness to Additive Noise 성능
Long-form Transcription
Chunk size : 30초 (초과 데이터 사용 불가)
Chunk size에 대한 ISSUE
- 짧은 발화 audio로 구성된 train dataset에서는 문제가 되지 않지만 몇분 몇 시간 분량의 audio를 텍스트로 변환해야하는 작업에서는 문제가 발생
- 30초 분량의 audio segment를 연속으로 transcript하고 model이 예측한 timestamp에 따라 window를 이동하는 방식으로 긴 audio의 buffering을 transcript하는 전략
긴 audio를 안정적으로 transcript하기 위해 모델 예측의 반복성(reptitiveness)과 로그 확률(log probability)을 사용
이 과정에서 beam search와 temperature scheduling이 중요 (4.5)
긴 transcription에 대한 performance 측정하기 위해 7개의 dataset으로 구성된 다양한 길이의 recording 상태를 검증(다양한 데이터 분포를 가지도록 구성)
- TED-LIUM3의 full-length TED 강연
- The Late Show Jargon-laden(with Stephen Colbert)
- Videos/podcasts
- online blogs (Rev16 and Kincaid46)
- recordings of earnings calls
- the full-length interviews from the Corpus of Regional African American Language (CORAAL)
- Full detail longform dataset Appendix A
Result
'👾 Deep Learning' 카테고리의 다른 글
| [Forensic Architecture] Justice Vision / "Vision으로 정의 구현" (0) | 2023.11.18 |
|---|---|
| [DATA] ACNE04 Dataset download(여드름 병변 검출) (0) | 2023.10.16 |
| Demand forecasting in logistics (0) | 2023.07.25 |
| CM3leon(.Meta) (0) | 2023.07.16 |
| [CS324] Introduction (0) | 2023.07.03 |