
728x90
Robust Speech Recognition via Large-Scale Weak Supervision
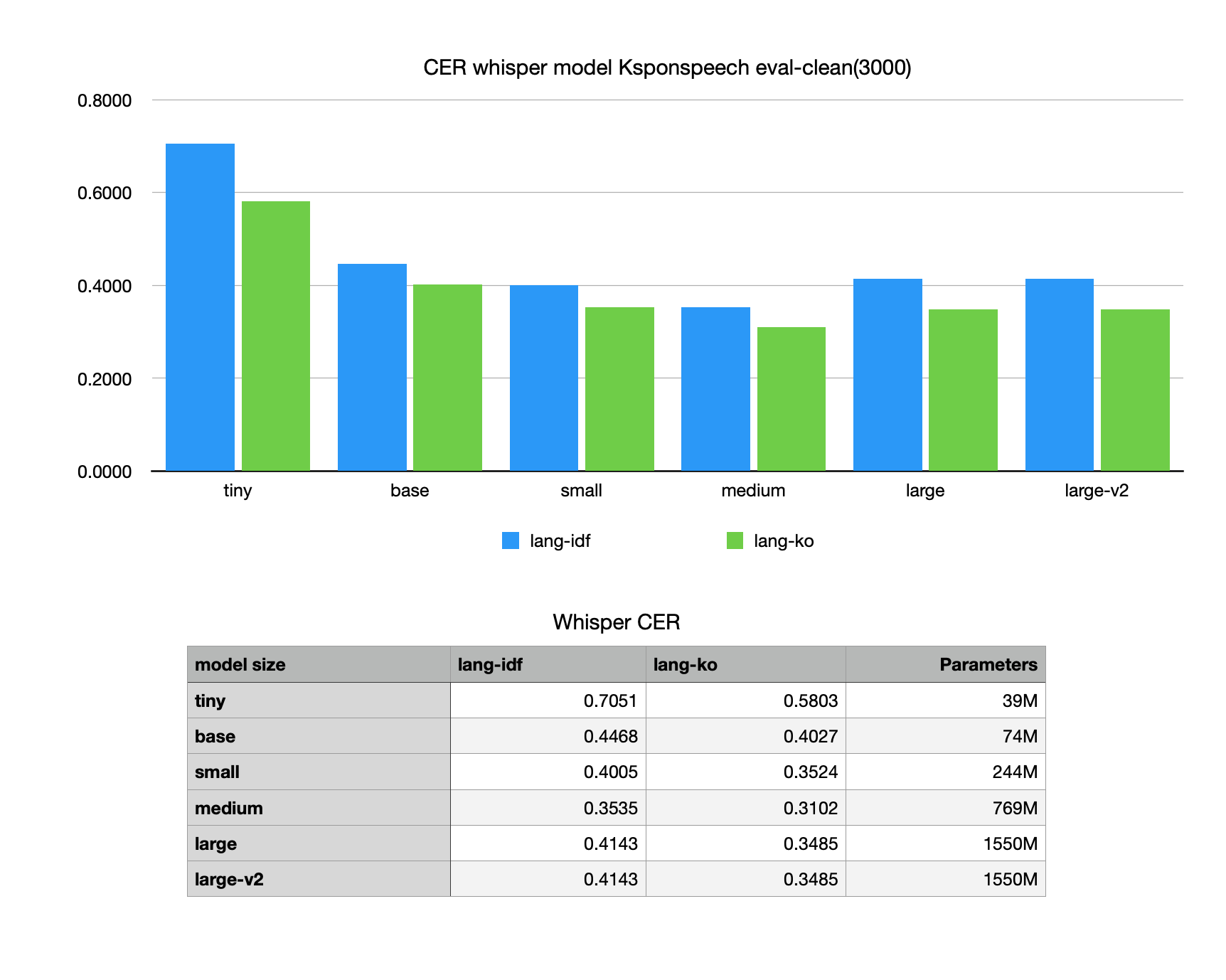
*large model은 2023.1 large-v2와 동일하게 바뀜
KsponSpeech 데이터는 짧은 발화의 audio를 주로 구성되어있다.
Whisper는 99개의 토큰으로 처음 발화에 대한 언어 예측(language identification)을 수행한다.
하지만 너무 짧은 발화 같은 경우 whisper가 다른 언어로 예측해 translate 자체가 틀려버려 CER이 증가하는 것을 볼 수 있다.
language Configure을 korean으로 설정하면 language identification을 수행하지 않고 바로 transcript로 예측해 더 좋은 성과가 났다.
model size는 예측과 양의 상관 관계를 내는 것이 일반적이지만 Whisper는 발화에 대한 번역을 한번더 수행하기 때문에 CER이 다소 크게 나올수 있음 WER은 낮을 것으로 예측
반응형
'👾 Deep Learning' 카테고리의 다른 글
| [Whisper] Robust Speech Recognition via Large-Scale Weak Supervision - (2) (0) | 2023.03.19 |
|---|---|
| [Whisper] Robust Speech Recognition via Large-Scale Weak Supervision - (1) (0) | 2023.03.18 |
| [Whisper] Koreanspon Valid (0) | 2023.03.10 |
| [Whisper] (1) - Abstract & Introduction (0) | 2023.03.06 |
| [NVIDIA RIVA ASR] 설치 가이드 (feat.nvidia-riva-sdk) (0) | 2023.02.23 |